안녕하세요. WH입니다
요즘은 너무나도 당연한 개념 중 하나인 attention에 관한 논문입니다.
이 논문이 오래되었음에도 정리하는 이유는
attention에 대한 생각을 다시 한번 정리하기 위함인데요
시작하겠습니다
Abstract
neural machine translation 은 machine translation에서 approach로 제안되었습니다. 전통적인 statistical machine ranslation과 다르게, nerual machine translation은 translation performance를 최대화화 하기 위해 jointly하게 tuned 될 수 있는 single neural network를 building 에 목적을 둡니다. nueral machine translation을 위해 최근 제안된 models는 encoders-decoders의 family에 속해 있습니다. 그리고 source sentence를 decoder가 translation하는 fixed-length vector로 encode 하죠. 이 논문에서는, 저자들은 fixed-length vector의 사용이 basci encoer-decoder architecture의 성능을 향상시키는 데에 bottleneck 이라고 생각한답니다 ( conjecture이라는 단어를 사용했는데, 이 말은, 충분한 근거 없이 예상해 본다라 는 의미 입니다 여튼 ) 그리고 basic encoder-decoder achitecture의 확장을 제안하는데요. model이 target word 예측과 관련된 source setence의 parts에 대해 automatically search 하도록 했다고 하네요. 다만 해당 과정은 hard sgment로서 명확한 form은 가지지는 않는다고 합니다. 이 new approach로, 저자들은 영어-to-프랑스어 translation task에서 phrase- based system 중 SOTA와 견줄만한 translation performance 달성 했다고합니다.
Introduction
Neural machine translation은 machine translation approach에서 새롭에 emerging 하도 있는데요. phrase-based translation system 과 다르다고 하네요. phrase-based model은 많은 small sub-components로 구성되어 있습니다. 그리고 그 sub-components는 개별적으로 tuned 되죠. neural machine translation은 setence를 읽고 올바르게 translation 결과를 내보내는 single, large neural network를 build하고 train합니다.
대게 제안된 neural machine translation models는 encoder-decoders의 family에 속해 있는데요. 각 language를 위한 encoder와 decoder나 languate-specific encoder를 포함하죠. encoder neural network는 source sentence를 fixed-length vetor로 encode 합니다. decoder은 encoded vetor로부터 translation을 출력하죠. whole encoder-decoder system은 language pair를 위한 endcoder와 decoder로 구성됩니다. 그리고 그 system은 주어진 source sentence로 올바른 translation의 probability를 최대화하도록 jointly하게 학습됩니다.
encoder-decoder approach가 지니는 poential issue는 neural network가 fixed-length vector에 source sentence의 information 모두를 압축해야할 필요가 있다는 점이죠. 이 issue는 neural network가 long sectence copy하는 것을 어렵게 하죠. Cho( 2014b paper에서 )는 input sentence의 길이가 증가함에 따라 basic encoder-decoder의 성능이 빠르게 감소하는 것을 보여주었습니다.
이 issue를 다루기 위해, 저자들은 encoder-decoder model을 확장했다고 하네요. 그리고 그 모델은 align 하고 translate를 함께 한다고 합니다. 제안된 모델은 translation에서 word를 생성합니다. 또한 해당 모델은 관련된 정보가 집중된 source sentence에서 positions의 set에 대해 searches 합니다. model은 그 다음 이전에 생성된 모든 target wors와 source position이 associated 된 context vectors에 기반해 traget word를 예측합니다.
이 approach의 distingushing feature는 a single fixed-length vector에 모든 input sentence를 encode하려는 시도를 하지 않는 다는 점입니다. 대신에, input sentence를 vetor의 sequence로 encode 합니다. 그리고 translation decoding 동안 이 vector의 subset을 adaptively 하게 선택합니다. 이것은 neural translation model이 source sentence의 모든 information을 압축된 상태로 가지고있는 것으로부터 자유롭게 합니다.
이 논문에서, 저자들은 align과 translate를 동시해 학습하는 approach가 basic encoder-decoder approach의 translation performance를 향상시켰다고 합니다. 이 improvement는 longer sentece에서 더 그럴싸 해보인다고 하네요. 물론 어떤 길이에서도 관찰될 수도 있다고합니다.
Background : neural machine translation
probabilistic perspective에서, translation은 target sentece y를 찾는 것인데요. 이는 주어진 source sentence x에 대해 conditional probability y를 최대화하는 것입니다. neural machine translation에서, 저자들은 parameterized model을 parallel training corpus를 사용하여 sentence pairs의 conditional probability를 최대화하도록 한다고 하는데요. conditional distribution은 translation model로 학습되면, translation과 관련된 주어진 source sentence는 conditional probability를 최대화하는 sentences에 대한 searching에 의해 생성됩니다.
많은 논문들이 neural networks를 이 conditional distirbution을 직접 학습하도록 제안해왔는데요. 이 neural machine translation approach는 두 개의 components로 구성되어있습니다. 하나는 source sentence x를 encode하는 component고 다른 하나는 target sentence y를 decodes 하는 component입니다.
RNN encoder-decoder
RNN encder-decoder라 불리는 framework을 간단하게 설명합니다. 그리고 이를 기반으로 새로운 architecture를 만들었다고 하네요. Encoder-Decoder framework에서 encoder는 input sentence( a sequence of vetor x )를 vector c 로 바꿉니다. 대게의 approach는 RNN을 사용합니다. 그 식은 아래와 같죠

여기서 h_t는 time t에서 hidden state을 말합니다. c 는 hidden state로부터 생성되는 vector입니다. f 와 q는 nonlinear functions 입니다. 예를 들어보면, 한 연구에서는 f에 LSTM을 사용했죠.
decoder는 context vector c 와 모든 이전에 predicted word가 주어질 때 next word y_t'를 예측하기 위해 학습됩니다. 다른 말로 하면, decoder는 ordered conditionals로 joint probability를 decomposing함으로써 translation y 에 대한 probability로 정의합니다. 식으로 나타내면 아래와 같죠
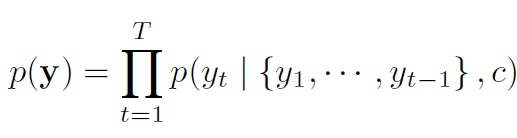
여기서 bold y는 아래와 같습니다
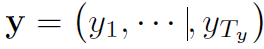
RNN 을 가진, 각 conditional probability는 아래와 같이 모델링됩니다.

여기서 g는 nonlinear, potentially multi-layterd, function 입니다. y_t의 probability를 출력하죠. s_t는 RNN의 hidden state 입니다.
Learning to align and translate
이번 section에서, 저자들은 neural machine translation을 위한 새로운 architecture를 제안한다고 하는데요. 새로운 architecture는 bidirectional RNN으로 구성됩니다. bidirenctional RNN은 a translation을 decoding하는 동안 source sentence로 통해 searching을 emulate하는 encoder와 decdoer입니다.
Decoder : general description
new model architecture에서, 저자들은 conditional probability를 아래와 같이 정의합니다
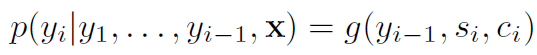
s_i는 time i에서 RNN의 hidden state을 말합니다. 그리고 s_i는 아래와 같이 계산되죠
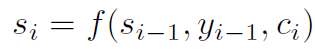
기존 approch와 다른데, 여기서 probability는 each target word y_i에 대한 context vector c_i에 영향을 받습니다. context vector encoder가 input setence를 매핑한 sequnce of annotations 의존하는데요. 각 annotation h_i는 input sequence의 i-th word 를 둘러싼 부분을 가지는 전체 input sequece에 대한 정보를 포함합니다. 저자들은 annotationsdmf 계산하는 방법을 다음 section에서 설명합니다. context vectro c_i는 weighted sum으로 계산되는데요. 아래의 식과 같습니다.

각 annotation h_j의 weight 알파_ij는 아래와 같이 계산됩니다.

여기서 e_ij 는 alignment model인데요. alignment model은 position j 주변의 inputs과 position i의 output이 얼마나 잘 match되는지를 score합니다. Score는 RNN hidden state s_i-1, input sequecne의 j-th annotation h_j에 기반합니다.
저자들은 alignment model a를 제안된 system의 모든 components를 가지고 동시에 trained 하는 feedforward neural network로써 파라미터화합니다. 기존 machine translation과 다른데, alignment는 latent variable로 고려되지 않습니다. 대신에, alignment model은 soft alignment를 직접 계산하는데, 이는 cost function의 gradient가 backpropagated 되는 것을 허용하죠. 이 gradient는 alignment mode과 whole translation model을 동시에 train 하기 위해 사용됩니다.
저자들은 all the annotations의 weighted sum을 taking하는 apporach를 expected annotation으로 이해할 수 있다고 합니다. expectation은 possible alignments를 넘어섭니다. 알파_ij를 target word y_i가 source word x_j에 aligned 나 translated 하는 probability라고 합시다. 그러면 i-th context vector c_i는 probabilities 알파_ij를 가지는 모든 annotation에 걸친 expected annotation입니다.
probability 알파_ij( 관련된 energy e_ij )는 next state s_i를 결정하고 y_i를 생성하는데에 있어 이전 hidden state s_i-1에 관한 annotation h_j의 중요도를 반영합니다. 직관적으로, 이것은 decoder에서 attention의 mechanism을 구현합니다. decoder는 집중해야 할 source sentence의 parts를 결정합니다. decoder가 attention mechanism을 가지도록 함으로써, 저자들은 encoder가 source sentence에서 all information을 fixed-length vector에 encoding 해야하는 부담을 완화시켰습니다. new approach로 information은 annotations의 sequece 전체로 퍼져나갈 수 있습니다. decoder에 의해 선택적으로 retrieved 될 수 있기 때문이죠.
Encoder : bidirectional RNN for annotationg sequences
usual RNN은 inpute sequence x를 읽습니다. ( x1 부터 마지막까지 순서대로 읽죠 ) 그러나, 제안된 scheme에서. 저자들은 preceding words를 요약할 뿐만아니라, following words 역시 요약하는 each word의 annotation을 원했습니다. 따라서, 저자들은 bidirectional RNN을 사용할 것을 제안합니다.
BiRNN은 forward 와 backward RNN's 로 구성되어습니다. forward RNN 은 input sequence를 순서데로 읽습니다. 그리고 forward hidden states의 sequence를 계산하죠. backward RNN은 input sequence를 거꾸로 읽습니다. 그리고 backward hidden state을 생성하죠.
저자들은 each word x_j에 대해 annotation을 forward hidden state와 backward hidden state를 concatenating 함으로써 얻었는데요.이런 방식으로 annotation h_j는 preceding words와 following words 모두에 대한 요약을 포함합니다. 최근 input을 더 잘 represent하는 RNN의 tendency 때문에, annotation h_j는 x_j 주변의 words에 focus 합니다. 이 annotations의 sequece는 decoder와 나중에 context vector를 계산하는alignment model에 사용됩니다. 아래의 그림은 이를 요약하여 나타낸 그림이죠.

이번 리뷰는 여기까지 하겠습니다.
아래 실험과 결론 등을 생략할께요
이번 논문을 통해 attention에 대한 정리가 되었기를 바랍니다.
이상 WH였습니다. 감사합니다.
이론 부분과 함께보면좋을것 같아요 ㅎㅎ
하나만 아래 링크로 걸어놓겠습니다.
읽어 주셔서 감사합니다
2022.07.05 - [AI] - Transformer 동작 원리 이해하기
Transformer 동작 원리 이해하기
안녕하세요. WH 입니다. 오늘은 transfomer의 이론적인 내용을 정리해보려고 합니다. 원 논문과 나동빈님의 강의를 참조하였습니다. 2022.06.28 - [AI 논문] - [ 꼼꼼하게 논문 읽기 ] Attention Is All You Need..
developer-wh.tistory.com
'AI 논문' 카테고리의 다른 글
| [ 꼼꼼하게 논문 읽기 ] Towards Real-Time Multi-Object Tracking (0) | 2022.07.08 |
|---|---|
| [꼼꼼하게 논문 읽기] Multiscale Vision Transformers 2 (0) | 2022.07.07 |
| [ 꼼꼼하게 논문 읽기 ] End-to-End Object Detection with Transformers 1 (0) | 2022.07.04 |
| [ 꼼꼼하게 논문 읽기 ] Attention Is All You Need ( feat. trasnformer ) (0) | 2022.06.28 |
| [ 꼼꼼하게 논문 읽기 ]MOTR : End-to-End Multiple-object Trackin with Transformer (0) | 2022.06.27 |



