안녕하세요. WH 입니다.
오늘은 transfomer의 이론적인 내용을 정리해보려고 합니다.
원 논문과 나동빈님의 강의를 참조하였습니다.
2022.06.28 - [AI 논문] - [ 꼼꼼하게 논문 읽기 ] Attention Is All You Need ( feat. trasnformer )
[ 꼼꼼하게 논문 읽기 ] Attention Is All You Need ( feat. trasnformer )
안녕하세요. WH입니다. 오늘은 매우 핫한 논문들의 base를 이루는 기초(?) 논문 리뷰입니다. 사실 다루지 않을까도 했는데 정리도 다시할 겸, 정리하겠습니다. 사실 이 논문을 정리하려면 seq2seq 논
developer-wh.tistory.com
Encoder
encoder가 하는 역할은 무엇일까요? 나름대로 고민해보고 정리한 바를 말하자면, encoder 란 source 의 feature map을 만들어 주는 역할을 합니다. 왜 feature map 이냐, 사실 많이 사용하는 용어를 빌려왔을 뿐, feature map이라고 하지는 않았던거 같아요. 그럼에도 왜 feature map이라고 표현했냐하면, decoder의 query 에 대한 key와 value를 제공하기 때문이죠. 여기서 query, key, value에 대해서 짚고 넘어가도록 하겠습니다.
query : 물어보는 주체
key : 물어보는 대상
value : 가중치
간단한 예시가 있습니다. vision ai로 예를 들어볼까요? 하나의 image가 있습니다. encoder를 통과하게 되면 image는 attention matrix가 나옵니다. 이 attention marix는 decoder에서 key와 value가 됩니다. 그럼 query는 뭐냐 decoder에서 물어보는 대상이 되는 겁니다. 여기까지 쉽죠? 그럼 위에서 말했던 query에 대한 key와 value를 제공하기 때문에 feature map라고 표현했다라고 했습니다. 즉 우리가 찾고자 하는 대상에 대한 특징을 가지고 있는 source가 encoder의 output기 때문에 위와 같은 표현을 사용했습니다. 이해가 되실까요??
Decoder
decoder는 내가 던진 query에 대해서 encoder의 output과 연관하여 결과를 출력하는 역할을 합니다. 즉 decoder가 하는 일은 encoder의 모든 출력을 참고하고, 매번 encoder의 모든 출력 중에서 어떤 정보가 중요한지를 계산합니다. 여기서 energe라는 개념이 나옵니다. 식은 아래와 같은데요. 이 식은 transformer가 아닌 seq2seq에 사용된 concept임을 알려드립니다. 그럼에도 설명하는 이유는 여기 적용된 아이디어가 transformer에도 비슷하게 적용되기 때문이죠.

seq2seq model에서 energy는 decoder의 현재 hidden state( representation 이라고도 하는 , 정보를 압축하고 있는 친구 )를 구할 때 사용하는 concept입니다. 즉 현재의 hidden state는 이전 decoder의 hiden state과 모든 encoder의 정보를 활용합니다. 이 energy를 활용하여 weight를 구하게 됩니다. 이 weight는 각 encoder의 hidden state와 곱해 더해집니다. 즉, 아래의 상황을 연출하게 되는거죠. + 되는 값은 weighted sum입니다.
Attention
transformer에서는 attention을 사용합니다. 그런데 attention이 뭘까요? KQ, 즉 energy에 softmax를 취한 확률에 value를 곱한 것이 attention이죠. 그런데 이게 도대체 의미하는게 뭐죠? attention은 input이 가지는 representation을 말합니다. 즉 input에서 특정 대상( query )에 대해 어디에 초점을 두어야 하는지에 대한 정보를 가지고 있다는 겁니다. encoder self-attention은 input이 아마도 전체 sequence 였죠? 그럼 이렇게 되는 겁니다. 해당 sequence 내 에서 그들이 가지는 relation에 대한 representation을 말합니다. masked decoder self-attention은 mask를 이용해 전체의 sequence를 보는 것이 아닌 이전에 나온 정보만을 반영한 relation에 대한 representation입니다. encoder-decoder는 decoder의 query와 encoder output으로 부터 key, value를 가져오죠. 이는 decoder에 대한 대상을 incoder의 정보를 참조하여 결과를 배출하게 되는 거죠.
Transformer
오늘의 메인 주제 transformer입니다. 관련 논문에 대한 요약은 위에 첨부해 놨답니다.
우선 input이 들어옵니다. 그런데 input 전체 sequence가 들어오죠. 즉 i am a student 자체가 들어옵니다. 문제는 우리는 저것을 순서대로 인식을 하지만 해당 input을 token화해서 sequence로 들어가게 되면 position에 대한 정보가 없다는 거죠. 그래서 attention에 들어가기 전에 position정도를 더해주게 되죠. 그럼 한 가지 의문이 듭니다. 문장이 얼마나 길줄 알고 우리가 그 문장을 토큰화해서 넣어주게되죠? 이를 해결한 아이디어가 embedding입니다. 우리는 필요한 token들이 다 들어갈 수 있도록 embedding에 미리 넣어 놓습니다. 보통 단어면 반복되는 단어보다 더 긴 길이의 embedding을 사용합니다. 만약 vision과 관련하여 class에 대한 정보가 들어가야 된다면 해당 class 수보다 긴 길이로 구성이 되겠죠. 여튼 이 embedding을 활용하여 key, query, value를 구합니다. 그리고 multi-head attention에 넣고 attention을 뽑아냅니다. 그럼 key, query, value를 어떻게 구할까요? I love you 라는 문장으로 예를 들어보죠
embedding dimension을 d_model이라 하는데요. multi head attention은 head를 여러개를 가지고 있습니다. 따라서 각 dimension은 embedding dimension을 head 수로 나눠주고 됩니다. 예시에서는 embeding dimension이 4, head가 2 개 라고 해봅시다. 그럼 q,k,v 의 dimension은 4/2 = 2가 되어야합니다. 각각의 q,k,v는 각각 W_q, W_k, W_v 를 해당 요소에 해당하는 embedding에 곱하여 계산됩니다. 그럼 W의 dimension은 4x2 가 되겠죠. 그래야 1x4 matmal 4x2 = 1x2 가 될테니까요. 그럼 이번에는 I 에 해당하는 quert의 attention이 구해지는 과정을 보도록하죠
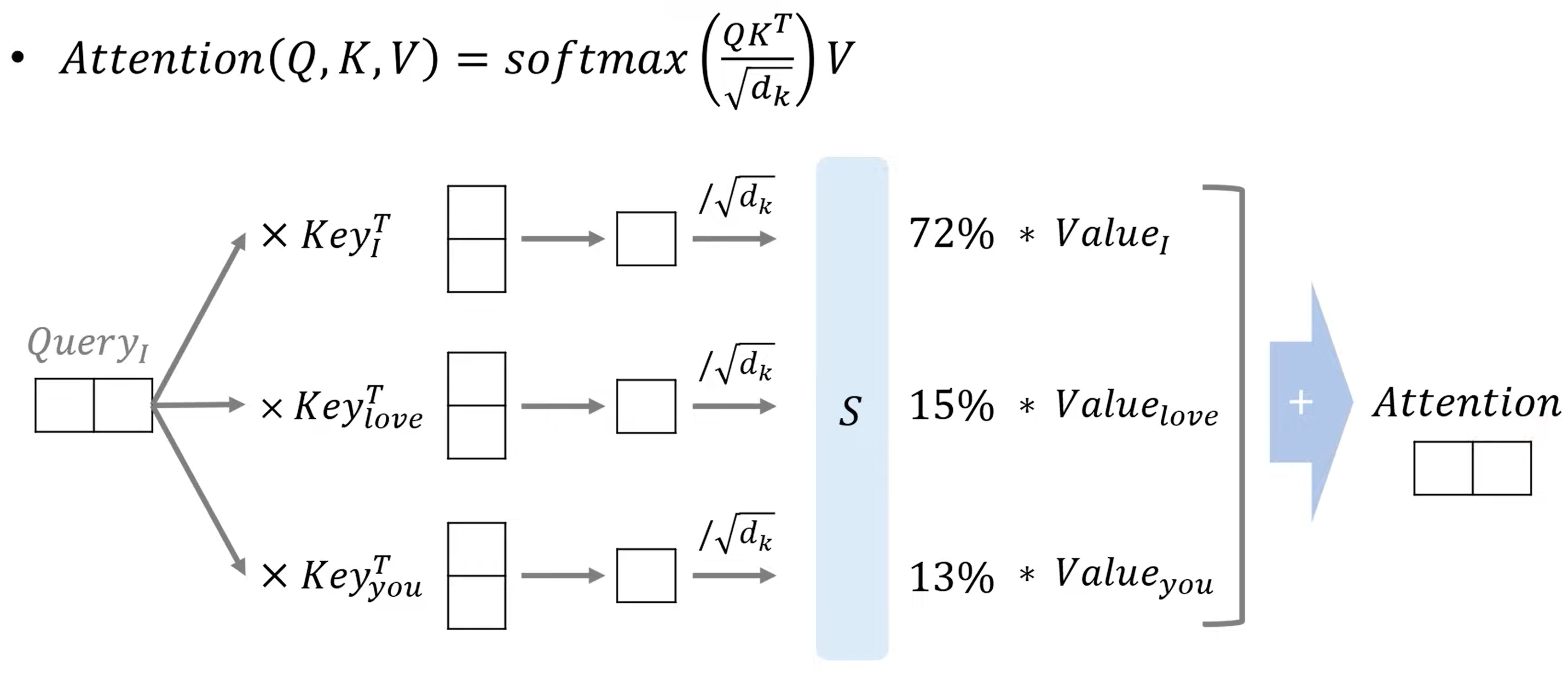
위의 과정을 통해 I에 대한 query가 나왔습니다. 이제 QK ( energy )를 구합니다 그리고 softmax에 넣어 I 가 문장에서 어떤 요소와 관계가 깊은지에 대해 확률로 나타내고 해당 확률에 value를 곱해 Attention이 나오게 됩니다. 루트 d_k로 나눠주는 이유는 softmax function의 경우 0을 기준으로 멀어지게되면 gradient vanishing이 일어나게 되고, 그를 방지하기 위해서 나눠주는 겁니다. 그럼 이번에는 전체 과정에서 대해서 정리한 그림을 보도록 하죠.
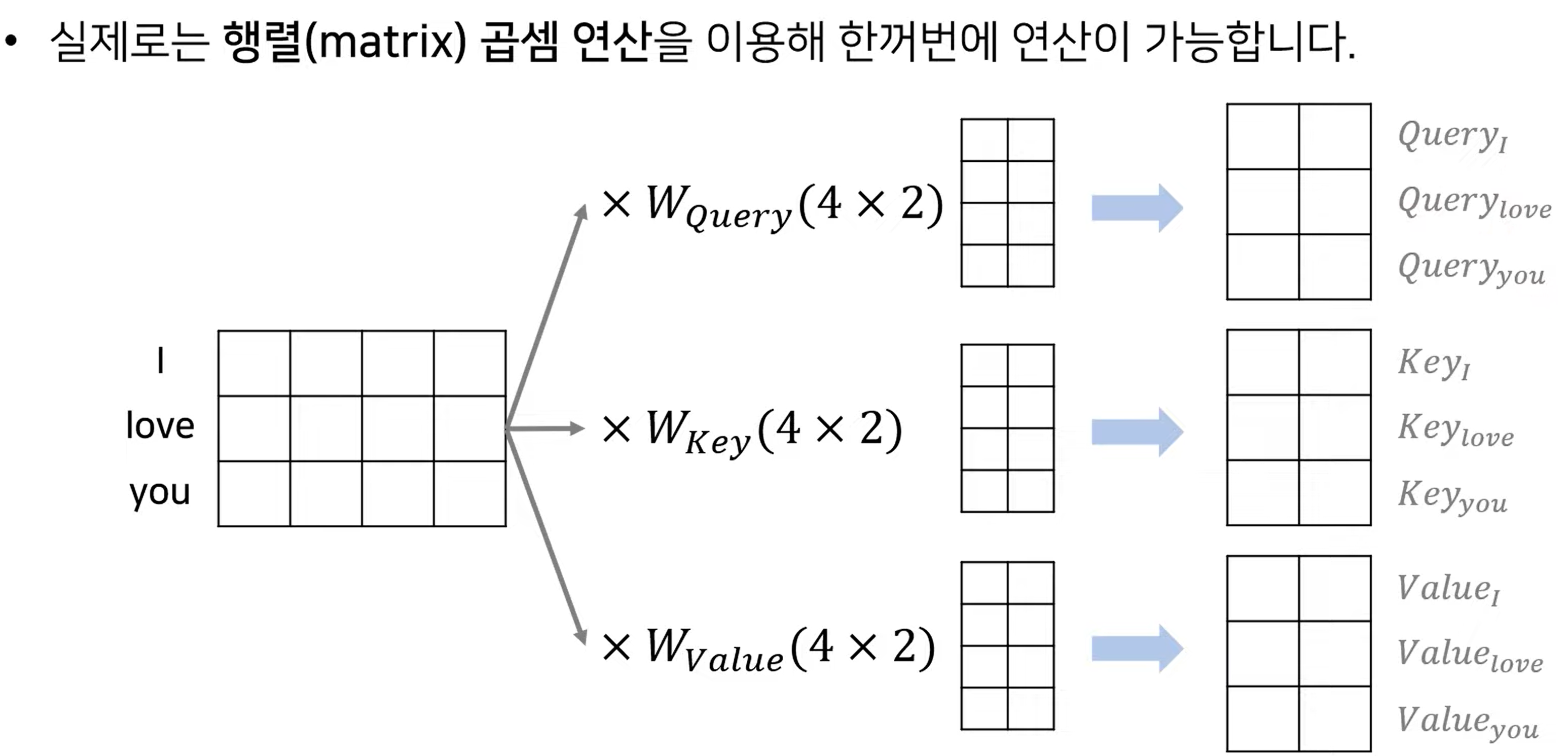
각 단어의 embedding을 하나의 matrix로 생각하면 각가의 weight를 곱해 Q, K, V 를 한번에 구할 수 있습니다. 그럼 이렇게 구해진 Q, K, V에 대한 처리는 아래와 같습니다.
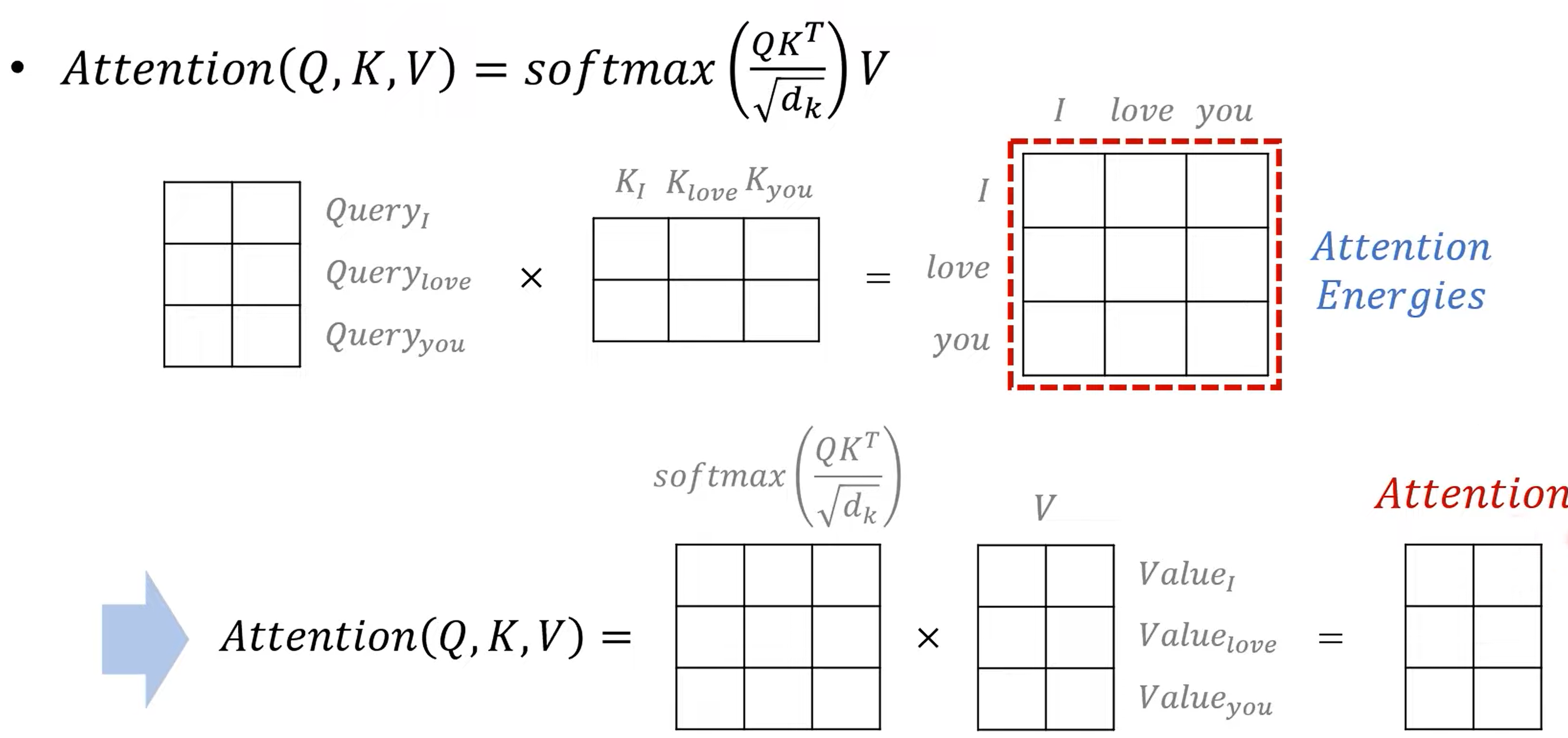
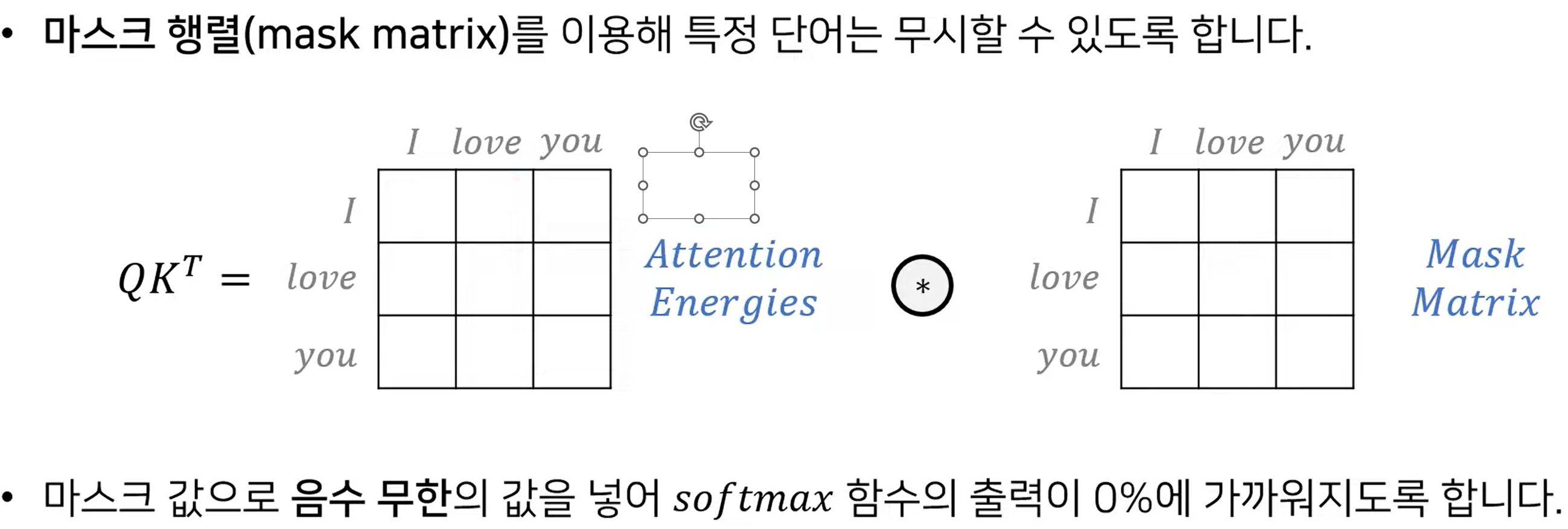
구해진 Query matrix와 Key matrix를 곱해 energy map을 구하게 되는데 이는 각각의 단어가 어떤 연관성을 가지게 되는지를 나타내 주는 map입니다. 여기에 softmax를 취하게 되면 그를 확률로 나타내 주며, 여기에 value를 곱해 최종 attention을 구하게 됩니다. attention은 가릴 수 있는데요. 이는 decoder self attention과 같은 곳에서 참고하지 말아야 할 단어에 대한 처리를 할 때 활용해 줄 수 있습니다. 이 말을 정리하면 아래와 같습니다
transformer에서 사용되는 attention은 위에서도 잠깐 언급했다시피 multihead attention인데요. head는 filter 혹은 kernel 과 같은 역할을 하신다고 생각하시면 됩니다. 각각의 다른 특징을 가지고 있다고 생각하시면 됩니다. 이를 그림으로 나타내면
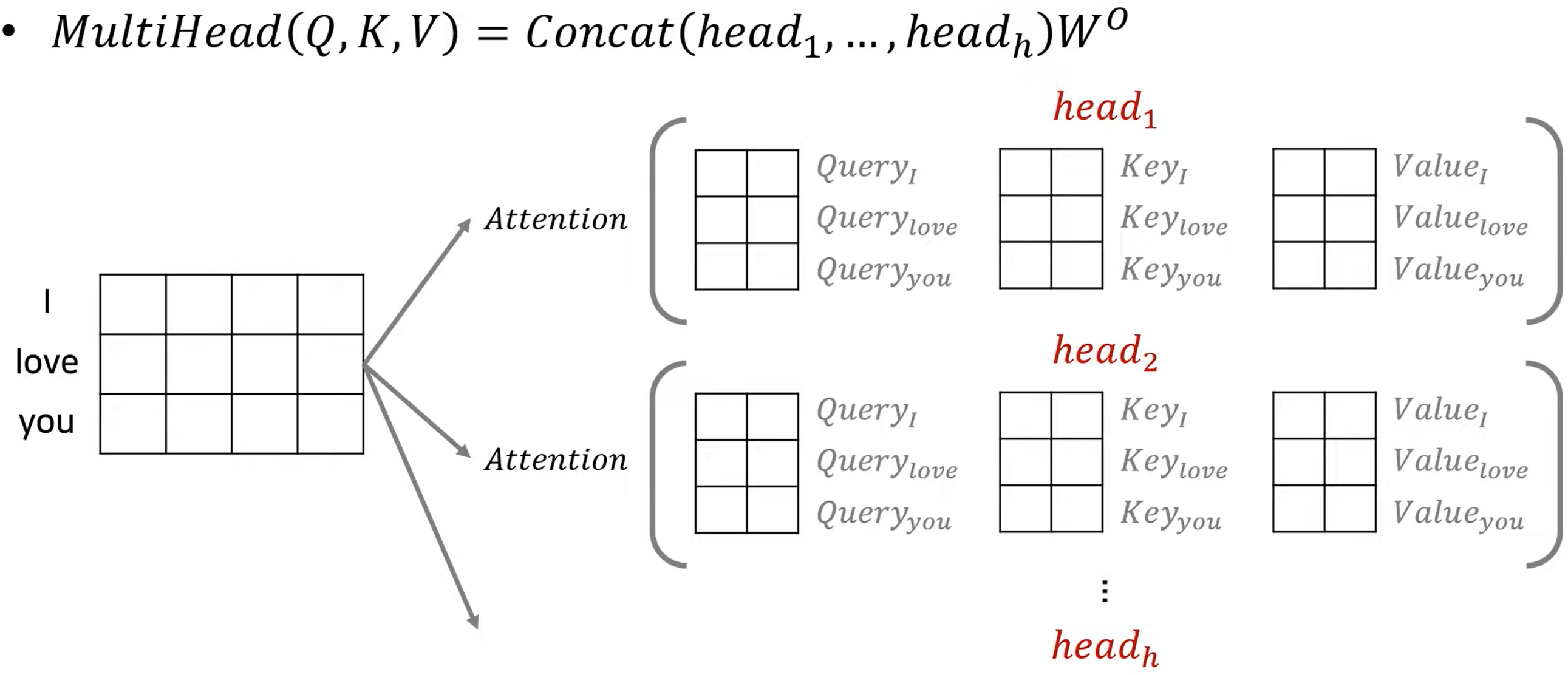
그러면 이렇게 나눠진 attention을 합쳐줘야 겠죠? 그리고 architecture에서 알 수 있듯이 반복적으로 사용함으로 dimension 역시 d_model로 맞춰주어야할겁니다. 즉 attention은 concat해주어야 겠죠. 아래 그림을 보고 설명을 이어나가도록 하겠습니다.
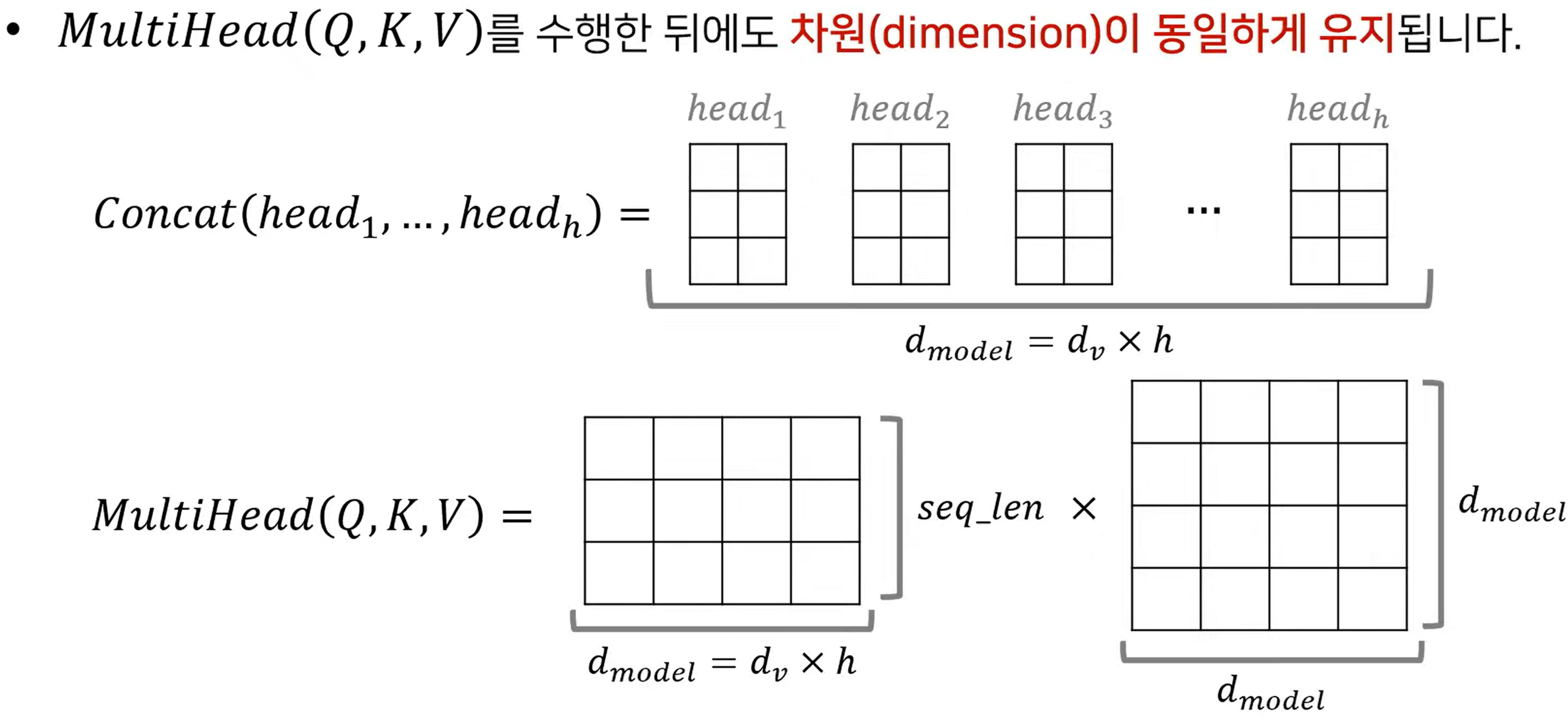
즉 위 그림에서 head 에 있는 matrix는 attention을 의미합니다. 그런데 우리가 k, q, v 의 dimension을 d_model / number of head로 했죠? 그럼 attention의 차원은 어떻게 될까요? k,q,v 와 같은 dimension이 될 겁니다. 이 때의 dimension을 d_v라 하면 d_model = d_v X h 가 되겠죠? 이를 concat하여 합치면 아래의 그림의 가운데 matrix 형태가 되며 여기에 W를 곱해주면 seq_len X d_model 로 차원은 유지됩니다.
자 다시 위의 architecture를 가져왔습니다. 그림은 왼쪽부터 설명합니다. 왼쪽은 encoder 오른쪽을 decoder라 합니다. 이제 다시 본론으로 돌아와 flow를 이해해보죠. encoder에 input을 input embedding하고 position embedding을 통해 위치 정보까지 준 sequence로 q,k,v 를 구성하여 multi head attention에 넣습니다. 그럼 input 전체에 대해 단어가 문장에서 연관된 정도에 대한 정보가 multihead attention의 output으로 나오겠죠. 이 output을 Feed forward를 통과 시키고 그 output으로 decoder의 key, value를 구성합니다. 이렇게 하면 encoder의 정보를 decoder의 query를 통해 연관도를 고려하여 matching 할 수 있겠죠. 이번에는 오른쪽 decoder로 넘어가겠습니다. decoder 에서 outputs를 embedding하고 positional embedding을 더해준다음 multihead attention을 통해 output 사이의 상관 관계가 파악된 output으로 query를 구성합니다. 이 때 input과 다르게 masking이 들어가는데 이는 앞선 결과가 예측에 영향을 미치지 못하게 하기 위함입니다. 해당 과정을 통해 query를 구성하게 되면, output과 input의 관계를 이어줄 attention이 나오고 해당 output을 Feed forward 에 넣어 나온 output을 linear layer를 통과시키고 softmax를 취해 최종 결과를 뽑아주게 됩니다. 이것이 transformer의 동작 원리 입니다.
정리를 하는 과정이 생각보다 오래걸리고 어렵네요
내가 아는 것이랑, 그것을 알게 설명한다는 것을 다르다는 것을 느낍니다.
이번 글도 읽어 주셔서 감사합니다. 이상 WH였습니다.
'AI' 카테고리의 다른 글
| coco 2017 pose track image and open pose keypoint (0) | 2022.10.18 |
|---|---|
| st-gcn 코드 분석 1 (2) | 2022.10.04 |
| SORT 구현을 위한 기초 이론 5 ( feat. Hungarian algorithm ) (0) | 2022.07.01 |
| SORT 구현을 위한 기초 이론 4 ( feat. Hungarian algorithm을 위한 이론들 ) (0) | 2022.06.30 |
| SORT 구현을 위한 기초 이론 3 ( feat. Kalman filter ) (0) | 2022.06.29 |



