리뷰가 너무 늦어졌네요.
그렇지만 다시 이어서 해보도록할께요
오늘은 MViT architecture에 대해 다뤄볼껀데요
앞의 내용은 아래 글에서 확인하시길 바랍니다.
2022.06.09 - [AI 논문] - [꼼꼼하게 논문 읽기] Multiscale Vision Transformers 1
[꼼꼼하게 논문 읽기] Multiscale Vision Transformers 1
안녕하세요. WH입니다 오늘 리뷰해볼 논문은 2021 facebook에서 나온 논문인데요 Multiscale Vision transformers라는 논문입니다. 항상 해왔던 것 처럼 Related work까지 다루도록 할게요 Abstract MViT을 출시..
developer-wh.tistory.com
Multiscale Vision Transformer ( MViT )
저자들의 genric Multiscale Transformer architecture는 stage의 core concept 로 설계가 되었다고 합니다. 각 stage는 specific space-time resolution과 channel dimension을 가진 multiple transformer blocks로 구성되어 있죠. Multiscale Transformers의 main idea는 channel capacity의 확장에 있다고 하는데요. input부터 output까지 resolution을 pooling 하는 동안 channel capacity가 확장된다고 하네요
Multi Head Pooling Attention
저자들은 먼저 Multi Head Pooling Attention에 대해 설명한다고 합니다. MHPA는 self attention operator ( input들을 relation한 representation이 나오겠네요. 여튼 ) 인데요. 이 operator는 Multiscale Transformers가 progressively 하게 spatiotemporal resolution 을 changing 에서 계산할 수 있도록 하는 transformer block에서 flexible 한 reolution modeling을 가능하게 해주죠. original MHA operators는 이와 대조적으로, channel dimension과 spatiotemporal resolution이 고정된 체 남아 있습니다. MHPA는 attended input의 sequence length( resolution )을 줄이기 위해 latent tensors의 sequence를 pools 합니다. 그 concept은 아래서 볼 수 있죠.

구체적으로, sequence length L 의 D dimensional input tensor X 를 고려해 봅시다. 식으로 나타내면 아래와 같죠.

MHA에 이어, MHPA는 input X 를 linear operations를 가진 intermediate query tensor hat Q, key tensor hat K, value tnesor hat V 로 project 합니다. 식은 아래와 같죠.


weights W_Q, W_K, W_V 의 dimensions 는 D X D 입니다. 얻어진 intermediate tensors는 sequence length로 pooling operator로 pooled 됩니다.
pooling Operator
input을 attending 하기 전에, intermediate tensor hat Q, hat K, hat V는 extension( 저자들의 Multiscale Transformer architecture 를 말합니다)에 의해 pooling operator로 pooled 되는데요. 이 operater는 MHPA에서 중요한 역할을 합니다.
이 operator는 각 dimensions에 따라 input tensor에서 pooling kernel computation을 수행합니다. 이 operator를 풀어서 ( k, s, p )라 하면, operator는 dimensions k_T X k_H X k_W의 pooling kernel k을 사용하고, dimensions k_T X k_H X k_W 에 해당하는 stride s 그리고 dimensions p_T X p_H X p_W 에 해당하는 padding p를 dimension L = T X H X W의 input tensor를 coordinate-wise를 적용한 equation을 가진 L~ 로 줄이기 위해 사용합니다. L~의 식은 아래와 같습니다.

pooled tensor는 polling operator의 결과로 다시 flatten 됩니다. 물론 reduced sqeunce length 를 가지게 되겠죠. default 로 저자들은 pooling attention operator에서 shape-preserving padding p 를 가진 overlapping kernels k 을 사용합니다. ~L이 s_Ts_Hs_W의 factor로써 overall reduction을 경험하도록 하기 위해서 말이죠.
Pooling Attention
pooling operator는 intermiate tensor hat Q, hat K 그리고 hat V에 선택된 pooling k, strde s 그리고 padding p를 가지고 독립적으로 적용되는데요. reduced seuqence lingths의 pre-attention vectors Q, K 와 V 생성하는 세타를 나타냅니다. Attention은 이 shortened vectors 에서 계산되는 데요. 식은 아래와 같습니다.

자연스럽게, operation은 pooling operators 를 이용할 때 제약이 있는데요. 그 제약은 밑의 식과 같습니다.

요약하면, pooling attention은 다음과 같이 계산됩니다.

루트 d 는 row-wise로 inner product matrix를 normalizing 합니다. Pooling attention operation의 output은 query vector Q 의 shortening 다음 나오는 stride factor에 의해 줄어든 sequence length를 가지게 되죠.
Multiple heads
computation은 고려된 h head에 의해 parallelized 될 수 있는데요. 각 head는 pooling attention을 input tensor X 차원 D의D/h channels에 대한 non overlapping subset 에서 pooling attention을 수행합니다.
Computational Analysis
attention computation scales가 sequence lenghth에 관해 quadratically 하기 때문에, key, query 그리고 value tensor를 pooling하는 것은 Multiscale Transformer model의 memory와 compute reqirements에 대해 dramatic한 이점이 있죠. sequece length reduction factor를 나타내면 아래와 같습니다.

dimensions D X T X H X W 를 가지는 input tensor에 pooling operator를 고려하면, head 당 MHPA의 run-time complexity는 아래와 같습니다.

memory complexity는 다음과 같습니다.
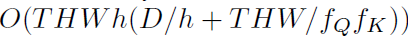
channels D와 sequence length term THW / f_Qf_K 사이의 trade-off는 저자들의 heads와 layer의 width와 같은 architecture parameters에 대한 design choice에 정보를 줍니다.
Multiscale Transformer Networks
MHPA 설계를 기반으로 저자들은 MHPA 와 MLP를 사용하는 visual representation learning을 위한 Multiscale Transformer model에 대해 설명합니다. 저자들은 Vision Transformer Model에 대해 간단하게 리뷰한다고 하네요.
ViT와 관한 부분은 그에 대한 논문 리뷰로 대체하겠습니다. vit은 올리지 않았네요..ㅎㅎ 그럼 다시 시작합니다. 당연히 썻을거라 생각했는데
Preliminaries : Vision Transformer ( ViT )
Vision Transformer ( ViT ) architecture는 resolution T X H X W의 input video를 dice( 잘라냄으로써, 풀어서 설명하자면 patch를 만드는 과정을 말합니다 ) 함으로써 시작합니다. 여기서 T는 높이 H 와 넓이 W frame의 개수가 되죠. 그리고 이는 각 frame을 size 1 X 16 X 16인 non-overlapping pathces 로 잘라냅니다. transformer의 latent dimension D 로 project하는 flattend image patch에서 linear layer의 point-wise application에 의해 나오게 되죠. 이것은 1 X 16 X 16 의 stride와 kernerl size를 가진 convolution과 equivalent합니다. patch_1 stage에 대한 내용을 표로 정리하면 아래와 같습니다.

다음 positional embedding E는 projected sequence 의 dimension D를 가진 length L 의 각 element에 더해집니다. 이는 permutation invariance를 없애고 positional information을 encode 하기 위함이죠. learnable class embedding이 projected image patches에 첨가됩니다.
L + 1에 resulting sequence of length는 N 개의 transformer blocks에 의해 sequentially 하게 처리됩니다. 각 block은 MHA, MLP 그리고 LN operation을 수행하죠. block의 input 이 된 X를 고려하면 single transformer block의 output( Block ( X ) ) 는 아래와 같이 계산됩니다.

N 개의 block 이후 resulting sequence는 layer-normalized 되고 class embedding이 추출됩니다. class embedding은 class를 예측하는 linear layer를 통과하게 되죠. default로, MLP의 hidden dimension은 4D입니다. ViT은 all blocks 내내 channel capacity와 spatial resolution 유지합니다.
Multiscal Vision Transformers(MViT)
key concept은 점진적으로 channel resolution ( i.e. dimension ) 이 커진다는 겁니다. 그리는 동안 동시에 spatiotemporal resolution ( i.e. sequence length) 는 작아지게 되죠. MViT architecture는 fine spacetime과 coarse channel resolution을 co가집니다. 아래 Table2에서 확인할 수 있죠.

Scale stage
scale stage는 channels 와 space-time dimension D x T x H x W에 걸쳐 동일한 resolution을 가진 same scale에서 계산하는 N개의 transformer blocks의 set으로 정의됩니다. input 에서 , 저자들은 patches( temporal extent를 가진다면 cubes )를 smaller channel dimension ( e.g. 8 x smaller than a tyical ViT ) 에 project합니다. 그렇지만 sequence는 길죠 ( ViT에 비해 16 x 만큼 깁니다)
stage transition에서, processed sequence의 channel dimension은 upsampled됩니다. 반면에 sequce의 length는 down-sampled 되죠. 이 과정은 network가 더 complex features에서 processed information을 완전히 이해하도록 하는 동안 visual data의 spatio-temporal resolution을 효과적으로 줄입니다
Channel expansion
one stage에서 다음으로 transitioning 할 때, 저자들은 channel dimension을 이전 stage에서 final MLP layer의 output을 해당 stage에서 inroduced된 resolution과 관련한 factor만큼 증가시킴으로써 확장합니다. 구체적으로, space-time resolution을 4 x로 down-sample하면 channel dimension은 2x 만큼 증가합니다.
Query pooling
pooling attention operation은 key 와 value vetor의 length에서 뿐만아니라 query, output, sequence의 length에서 역시 flexibility를 afford합니다. query vector P ( Q ; k ; p ; s )를 pooling하는 것은 s 만큼 sequence reduction을 야기합니다. 따라서 저자들의 의도는 초기 stage에서 resolution을 감소하는 것이고 그런 다음 이 resolution을 stage 내내 유지하는 겁니다. 각 stage의 오직 처음 pooling attention operator 만이 non-degenerate query strid 에서 계산합니다.
Key-Value pooling
Query pooling과 다르게, K 와 V tensor의 sequence length를 바꾸는 것은 output sequence length( space-time resolution
)을 바꾸지 않습니다. 그러나 key-value pooling은 pooling attention operator의 전체 computational requirements에 중요한 역할을 합니다
저자들은 K, V와 Q pooling을 분리합니다. Q pooling은 각 stage의 first layer에서 사용되고, K, V pooling은 다른 모든 layer에서 사용됩니다. key와 value tensor의 sequence length는 attention weight calculation을 위해 identical해야 하기 때문에, key와 value tensor에 사용되는 pooling stride 역시 identical 해야합니다. default setting에서, 저자들은 all pooling paramters를 stage안에서 identical 하도록 제약했는데요. 그렇지만 stage에 따라 scale에 관해서는 다양한 s를 적용했다고 하네요.
Skip connections
residual block에서 sequence length와 channel dimension이 바뀌기 때문에, 저자들은 two ends 간의 mismatch dimension을 적용한 skip connection을 pool하는데요. MHPA는 query pooling operator를 residual path에 더함으로써 이 mismatch를 다룬다고 하네요. output에서 MHPA의 input X를 직접 더하는 대신에, 저자들은 pooled input X를 output에 더합니다. 그렇게 함으로써 attended query Q에 resolution에 matching했다고 하네요. 이것은 아래 Table 3에서 확인할 수 있습니다.
stage changes 간의 channel dimension mismatch를 다루기 위해, 저자들은 MHPA operation의 layer-normalized out 에서 계산하는 extra linear layer를 사용합니다.

Network instantiation details
위의 Table 3은 vision transformer와 Multiscale vision transformers에 대한 base model의 구체적인 instantiations를 보여줍니다. ViT-Base 처음에 input을 D=768, 1 x 16 x 16 pathces shape에 projects합니다. 그 다음 N = 12인 transformer blocks가 나오죠. 8 x 224 x 224 input으로 resolution은 768 x 8 x 14 x 14 로 모든 layer에서 고정됩니다. sequence length ( spacetime resolution + class token ) 은 8 * 14 * 14 + 1 = 1569 입니다.
MViT-Base는 4 scale stage로 이뤄져있는데요, 각각은 consistent channel dimension의 several transformer blocks를 가집니다. MViT-B는 초기에 input을 3 x 7 x 7 shape의 overlapping space-time cubes를 가진 D = 96 channel로 projects 합니다. resulting sequence of length 8*56*56 + 1 = 25089는 4 stage 각 additional stage에 대해 factor 에 의해 줄어드는데요. scale_4에서 final sequence length는 8*7*7 + 1 입니다. all pooling operations( resolution down-sampling)은 processed class token embedding 없는 data sequence에 대해 수행됩니다.
저자들은 MHPA의 scale_1에서 head = 1로 set 합니다. 그리고 head 당 D/h의 channel dimension을 가진 heads의 number를 늘립니다.
각 stage transition에서 이전 stage output MLP dimension은 2 X 남큼 증가되고 MHPA는 net stage의 input에서 S^Q = ( 1, 2, 2 )를 가진 Q tensor에 pools 합니다. 저자들은 K, V pooling을 모든 MHPA blocks에서 사용하는데요. scale_1에서는 조건은 아래와 같습니다.

K,V tensor가 all blocks에 따라 consistent scale을 가지는 stage에 따른 scale에 관한 이 stride는 adaptively하게 decay합니다.
오늘은 여기까지 입니다.
실험부분이나 고찰 결론, 부분은 다루지 않았습니다.
꽤나 오랫동안 미루다가 올렸는데
그래도 읽어주셔서 감사합니다. 이상 WH였습니다/



