안녕하세요. WH 입니다
오늘은 DETR에 대해 다뤄볼까합니다.
Abstract
object detection을 direct set prediction problem으로 보고 새로운 모델을 출시했다고 하는데요. 저자들의 approach는 detection pipeline를 간소화한다고 하는데요, 효과적으로 많은 hand-designed 된 구성 요소들을 제거한다고 하네요. 뭐 예로써, NMS나 achor generation과 같은 것들을 들어줍니다. newframwork( DETR )의 구성요소는 bipartite matching을 통한 unique prediction에 초점을 맞추는 set-based global loss와 transformer encoder-decoder architectur입니다. learned object queries의 고정된 set이 주어지면, DETR은 병렬적으로 predictions의 최종 set을 직접적으로 출력하기 위해 objects와 global image context의 관계에 대해 추론합니다. 새로운 모델은 개념적으로 단순하고 다른 많은 모델들과는 다르게 specialized library를 필요로 하지 않습니다. DETR은 COCO object detection dataset에 대해 well-established 되고 highly-optimized된 Faster R-CNN baseline과 대등한 accuracy와 run-time performance를 보여줍니다. 게다가, DETR은 unified manner로 panoptic segmentation을 생성하기 위해 쉽게 generalized 될 수 있습니다. 저자들은 competitive baseline를 뛰어넘었다고 하네요.
Introduction
object detection의 목표는 bounding boxes와 category labels의 set을 각 objects of interest에 대해 예측하는 것인데요. Modern detectors는 이 set prediction task를 간접적인 방법으로 다룹니다. 즉, proposals, anchor 또는 window centers의 large set에 대해 surrogate regression과 classification problem으로 정의하죠. 그들의 performances는 anchor에서 near diplicate predictions를 colapse하는 postprocessing( model 이후의 output을 처리하는 과정을 postprocessing 이라고 합니다. 아시겠지만 ㅎㅎ )에 의해, traget boxes 할당하는 heuristics 와 anchor set에 의해 상당히 영향을 받습니다. 이 pipelines를 simplify하기 위해, 저자들은 surrogate task를 무시하는 direct set prediction approach를 제안합니다. 이 end-to-end philosophy는 machine translation이나 sppech recognition과 같은 complex sturctured prediction task 에 상단한 발전을 이끌어왔습니다만, object detection에는 아직 적용되지 않았다고 하네요. 이전에 있던 시도들 역시 challenging benchmarks에 대해 비교할 정도는 아니었다고 하구요. 이 논문이 이 gap을 줄이는 것을 목표로 한다고 하네요.

저자들은 object detection을 direct set prediction probelm으로 봄으로써 training pipeline을 간소화 했다고 하는데요. 저자들은 transformers에 기반한 encoder-decoder architecture를 적용했다고 합니다. 아시다시피 이 encoder-decoder architecture는 sequence prediction에 인기가 있는 architecture죠. transformers의 self-attention mechanisms는 명시적으로 sequences에서 요소들 간의 모든 pairwise한 interactions을 모델링하죠. 또한 이 mechanisms는 architectures가 특별히 duplicate predictions를 removing하는 것과 같은 set prediction의 specific constraints에 적합하도록 합니다. DETR은 모든 objects를 한번에 예측합니다. 그리고 predicted와 ground-truth objects간에 bipartite matching을 수행하는 set loss function을 가지고 end-to-end로 trained됩니다. DETR은 spatial anchors나 non-maximal suppression과 같은 prior knowledge를 encode하는 hand-designed된 구성요소를 dropping함으로써 detection pipeline을 간소화합니다. 대게 존재하는 detection pipeline과 다르게, DETR은 customized layers를 요구하지 않습니다. 따라서 transformer classes나 기준 CNN을 포함하는 어떤 framework에서 쉽게 재생성될 수 있습니다.
direct set prediction에 대해 대부분의 이전 work와 비교해서, DETR의 main features는 bipartite matching loss와 ( non-autoregressive )병렬적인 decoding에 결합합니다. 반면에, 이전 work은 RNN을 가지고 autoregressive decoding에 초점을 맞추는 데요. 저자들의 matching loss function은 prediction을 ground truth object에 uniquely 할당합니다. 그리고 loss function은 predicted object의 permutation에 불변합니다. 때문에 predicted objects를 병렬적으로 보낼 수 있습니다.
저자들은 DETR을 가장 popular한 object detection set COCO에서 Faster R-CNN baseline에 대비하여 평가했습니다. Faster R-CNN은 many design iterations를 겪어왔는데요. 때문에 performance는 original publication 이래로 굉장히 향상되었죠. 저자들의 실험은 DETR이 그와 견줄만한 성능을 보여준다고 합니다. 더 정확하게 DETR은 large object에 대해서는 더욱 뛰어난 성능을 보여줍니다. transformer의 non-local computations에 의해 가능한 결과죠. 그러나 small objects에 대해서는 더 낮은 성능을 보여줍니다. 저자들은 앞으로의 연구는 이 성능을 Faster R-CNN에 적용된 FPN을 비슷한 방식으로 적용해서 향샹시킬 수 있으리라 기대한다고 합니다.
DETR을 위한Training setting은 multiple ways에서 standard object detectors와 다른데요. DETR은 extra-long training schedule과 transfoermet 내의 보조 decoding losses로 부터의 benefits를 요구합니다. 저자들은 demonstrated performance를 위해 어떤 구성요소가 중요한지 철저하게 연구했다고하네요. DETR의 design ethos는 complex tasks로 쉽게 확장할 수 있는데요. 저자들의 실험에서 저자들은 pretrained DETR로 trained된 simple segmentation head가 Panopic Segmentation에 대해 baselines을 뛰어넘는 성능 보여줬다고 하네요. ( pixel -level의 recogniition task에서도 좋은 성능을 보인다고 생각하시면 됩니다 )
Related work
저자들의 연구는 몇몇 domains에서 기존 연구에 기반해 build 되었습니다 : set prediction을 위한 bipartite matching losses, transformer에 기반한 encoder-decoder architectures, parallel decoding 그리고 object detection method가 그 기존 연구들이죠. 아래서는 하나씩 설명합니다. 함께 보시죠
아래 글들을 읽기 전에 AI기초 이론에서 읽으면 좋을만한 글들을 놔둘게요
2022.07.01 - [AI] - SORT 구현을 위한 기초 이론 5 ( feat. Hungarian algorithm )
Set Prediction
directly predict sets에 대한 표준 deep learning model이 없다고 합니다. basic set prediction task는 one-vs-rest, 즉 baseline approach가 elements 간의 underlying sturcture이 존재하는 detection 과 같은 문제에 적용되지 않는 multilabel classification 이라고 하는데요. 이 tasks에서 첫 번째 어려움은 near-duplicate를 피하는 겁니다. Most current detectors는 이 문제를 해결하기 위해 NMS와 같은 postprcessings를 사용합니다. 그렇지만 direct set prediction은 postprocessing이 없죠. detectors들은 reducndancy를 피하기 위해 모든 predicted elements 간의 interactions를 모델링하는 global inference schemes가 필요합니다. constant-size set prediction에 대해, dense fully connected networks 는 충분하지만 costly 하죠. 일반적인 approach는 RNN과 같은 auto-regressive sequence model을 사용하는 겁니다. 모든 cases에 있어, loss function은 predictions의 permutation에 의해 변하지 않습니다. usual solution은 Hungaruan algorithm을 기반해 loss를 design 하는 겁니다. 이는 ground-truth와 prediction의 bipartite matching을 찾기 위함이죠. 이것은 permuation-invariance를 강화합니다. 그리고 each target element가 unique match임을 보장하죠. 저자들은 bipartite matching loss approach를 채택했습니다. 그러나 기존 연구와 다르게, 저자들은 autoregressive model를 사용하는 대신 paralle decoding을 가진 transformers를 사용합니다.
Trnasformers and Parallel Decoding
Trnasformers는 Vaswani에 의해 제안되었는데요. 이는 new attention-based building block을 machine translation을 위해 사용했죠. Attention mechanisms는 entire input sequence로 부터 information은 aggregate하는 NN( neural network ) layers입니다. Transformers는 self-attention layer를 제안합니다. self-attention layers는 Non-Local Neural Networks와 비슷한데요. sequence의 각 요소로 부터 스캔해서 전체 sequence로부터 information을 aggregating 함으로써 업데이트 합니다. attention-based models의 주요 이점 중 하나는 perfect memory와 global computation인데요. models가 long sequeces에 대해 RNN보다 더 적합하도록 만들어주죠. Transformer는 NLP, speech processing 그리고 computer vision에서 많은 문제에 대해 RNN을 대체하고 있습니다.
Transformers는 auto-regressive model에서 먼저 사용되었습니다. 그 모델은 sequence-to-sequence 모델이었죠. 이는 output token은 one-by-one으로 생성합니다. 그러나 엄청난 inferecne 비용 ( output 길이에 따라 비례하며, batch가 어렵기 때문에 ) 다양한 분야에서 parallel sequence generation의 개발을 이끌었죠. 저자들은 computational cost와 set prediction에서 요구되는 global computation을 수행하는 ability 사이의 적합한 trade-off를 위해 transformers와 parallel decoding 합칩니다.
Object detection
현대의 많은 object detection methods는 predictions를 몇몇 초기 추측과 관련되도록 합니다. Tow-stage detectors는 proposals에 대해 boxes를 predictions하게 합니다. 반면에 single-stage methods는 predicions를 anchors나 가능한 object center의 grid 에 대해 predictions하도록 하죠. 최근 연구는 이 systems의 최종 performance가 이 initial guesses를 설정하는 정확한 방법에 따라 크게 달라진다고 것을 보여주고 있죠. 저자들의 모델에서는 저자들은 이 hand-crafted process를 제거할 수 있고 anchor보다 image에 관해 예측하도록 absolute box를 가진 detections의 set을 직접 예측함으로써 detection process를 간소화 할 수 있다고 말합니다.
set-based loss
몇몇 object detectors는 bipartite matching loss를 사용합니다. 그러나 이 초기 deep learning models에서는 다른 prediction 간의 relation은 convolutional 이나 fully-connected layers 만을 가지고 모델링 되었습니다. 그리고 hand-designed NMS post-processing이 그 모델들의 성능을 향상시킬 수 있었죠. 더 최근의 detectors는 ground truth 와 predictions 사이에non-unique assignmet rules를 NMS와 함께 사용했죠.
Learnable NMS methods 와 relation networks는 attention을 가지고 다른 predictions 간의 관계를 모델링합니다. direct set losses를 사용해서, methods와 networks는 어떤 post-processing steps가 필요하지 않습니다. 그러나 이 methods는 additional hand-crafted context features를 사용합니다. 효과적으로 detections 간의 relations를 모델링하기 위한 proposal box coordinate 같은 것들이 그 예입니다. 반면에 저자들은 model에서 encoded된 prior knowledge를 줄이기 위한 solutions를 찾았다고 합니다.
Recurrent detectors
저자들의 approach와 가장 비슷한 접근법은 object detection과 instance segmentation을 위한 end-to-end set predictions인데요. 저자들과 유사하게, 그들은 bipartite-matching losses를 encoder-decoder architectures에서 사용했다고 합니다. 다만 bounding boxes의 set을 직접 생성하기 위해 CNN activations를 사용했지만요. 이 approaches는 small datasets에 대해서만 평가되었고, modern baselines와 비교하지도 않았죠. 실예로, 그 모델들은 autoregressive models( 더 정확히 RNN )에 기반하였기에 parallel decoding을 가진 transformers를 사용하지 않았습니다.
The DETR model
detector에서 direct set predictions를 위한 필수적인 두 가지 구성요소가 있습니다.
1) predicted와 ground truth boxes 간의 unique matching를 강제하는 a set prediction loss
2) a set of objects를 예즉하고( single pass 로 ) 그들의 관계를 모델링하는 architecture
저자들은 Figure 2에서 구체적으로 자신들의 architecture를 묘사합니다.
Object detection set prediction loss
DETR은 N 개의 predictions의 fixed-size set을 추론합니다. decoder를 통한 single pass에서 말이죠. 여기서 N은 한 image에서 objects의 typical number보다 significantly 커집니다. training의 주요 어려움 중 하나는 ground truth에 관해 predicted objects의 score하는 것 입니다. ( class, position, size에 대해서 ) 저자들의 loss는 predicted와 ground truth objects 간의 최적의 bipartite matching 생성합니다. 그리고 나서 object-specific( bounding box ) losses를 최적화 하죠.
저자들은 objects의 ground truth를 y로 표기합니다. 그리고 예측치 y ( hat y ) 는 N개의 predictions의 집합입니다. 즉 hat y는 아래와 같습니다
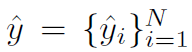
N은 image에서 objects의 수 보다 큽니다. 저자들은 y를 no object에 padded N 크기의 set으로써도 고려합니다. 이 두 개의 sets 간의 bipartite matching을 찾기 위해 저자들은 가장 작은 cost를 가지는 N elments 시그마의 permutation을 찾습니다. 즉 식으로 나타내면 아래와 같습니다.

여기서 L_match()는 ground truth y_i와 index 시그마 (i)를 가지는 prediction 간의 pair-wise matching cost입니다. 최적의 할당은 hungarian algorithm에 의해 효과적으로 계산됩니다.
matching cost는 class prediction과 predicted and ground truth boxes의 similarity 모두를 고려합니다. 각 ground truth set의 element i는 y_i = ( c_i, b_i )로 나타납니다. c_i 는 target class label이며 공집합일 수 있습니다. b_i는 image size에 대해 ground truth의 높이와 넓이 그리고 center coordinates로 정의한 vetor입니다. index 시그마 (i)를 가지고 prediction을 하기 위해 저자들은 class c_i의 probablity를 정의합니다. hat p_sigma(i)( c_i ) 로 말이죠. 그리고 predicted box를 hat b_sigma(i)로 정의합니다. 이 notations로 저자들은 L_match( )를 정의합니다. 아래와 같이 말이죠.

이 finding matching 절차는 proposal 이나 anchors를 ground truth objects에 match하기 위해 사용되었던 heuristic assignment rules와 같은 역할을 합니다. 주요 차이점은 저자들은 duplicates 없이 direct set prediction을 위한 one-to-one matching을 찾는 것이 필요하다라는 점이죠.
두 번 째 step은 loss function을 계산하는 겁니다. 이전 step에서 matched된 모든 pair에 대해 hungarian loss를 계산한다는 거죠. common object detectors의 losses에 loss를 정의하는데요. 예를들어 a box loss와 class prediction에 대해 negative log-likelihood의 linear combiantion이 되겠죠. 식으로 정리하면 아래와 같습니다.

hat sigma는 optimal assignment입니다. step(1)에서 계산되었죠. 실 예로, 저자들은 c_i = 공집합 일 때, class imbalance를 설명하는 log-probability term 으로써 factor 10을 down-weight합니다. 이것은 Faster R-CNN training이 subsampling을 통해 positive/negative proposals를 balances 하는 방법과 유사한데요. objects와 공집합 간의 cost를 matching하는 것은 prediction에 상관하지 않습니다. cost를 matcing하는데 있어, 저자들은 log-probabilities 대신에 probability hat p_sigma(i)( c_i )를 사용합니다. 이것은 class prediction term을 L_box( )와 필적하게 합니다. 그리고 저자들은 실험적으로 더 나은 performance를 관찰했다고 합니다.
Bounding box loss
matching cost와 Hungarian loss의 두 번째 part는 L_box ( )입니다. bounding boxe를 socre하죠. some initial guesses를 관해 변화로써 box predictions 하는 많은 detectors와 다르게, 저자들은 직접 box predictions를 합니다. 대신 기존 approach는 loss의 scaling과 관한 문제가 있는 implementation을 간소화 했습니다. commonly-used l_1 loss는 small과 large boxes에 대해 다른 scales를 가집니다. 상대적 오차가 비슷할 때 조차도 말이죠. 이 문제를 줄이기 위해 저자들은 l_1 loss와 scale-invariant한 generalized IoU loss L_iou( )의 linear combination을 사용합니다. 전체적으로 저자들의 box loss는 아래와 같이 정의됩니다.

람다_iou, 람다_L_1은 hyperparameters 입니다. 이 두 개의 losses는 batch 안에서 objects의 number로 normalized됩니다.
DETR architecture
전체적인 DETR architecture는 놀랄만큼 간단하며 Figure 2에 나타나 있습니다

DETR은 세 가지 주요 구성요소들을 가지고 있죠. 그리고 이는 아래서 설명합니다 : feature representation을 추출하기 위한 CNN backbone, encoder-decoder transformer, 그리고 final detection prediction을 만드는 simple feed forward network ( FFN )이 그 구성요소죠,
많은 modern detectors와 다르게, DETR은 단지 수 백줄(...? 단지 맞나 )의 만 가지고 CNN backbone과 transformer architecture 구현이 제공되는 어떤 deep learning framework에서도 구현될 수 있습니다. DETR애 대한 inferce code는 pytorch에서 50 줄 이내로 구현될 수 있습니다. 저자들은 자신들의 method의 simplicity가 detection community에서 new rewearches로 매력적이길 바란다네요
Backbone
initial image x_img는 3 개의 color channels를 가집니다. CNN backbone은 lower-resolution activation map을 생성하죠.. values는 C= 2048이며 H,W는 H_0/32, W_0/32 입니다.
Transformer encoder
먼저 1*1 convolution이 C부터 smaller dimension d까지 high-level activation map f의 channel dimension을 줄입니다. 이는 new feature map z_0를 만드는데 range는 d*H*W입니다. encoder는 input으로써 sequece를 원하죠. 따라서 저자들은 z_0의 spatial dimensions를 one dimension으로 바꿉니다. 그 결과 d*HW의 feature map이 됩니다. 각 encoder layer는 standard architecture를 가지고 있습니다. 그리고 multi-head self-attention module과 feed forward network로 구성됩니다. transformer architecture는 permutation-invariant하기 때문에, 저자들은 fixed positional encodings와 함께 input을 인코더에 넣습니다. 즉 positional encodings는 각 attention layer의 input에서 더해집니다. 저자들도 타 논문을 참조했다고 하네요
Transformer decoder
decoder는 transformer의 standard architecture를 따릅니다. multi-headed self-attention과 encoder-decoder attention mechanism을 사용해서 size d의 N개의 embeddings를 transform하죠. original transformer와 다른 점은 저자들의 model은 N objects를 병렬적으로 각 decoder layer에서 decodes 한다는 점입니다. Vaswani는 한번에 sequecnce one element를 출력하기 위해 autoregressive model를 사용했죠. 저자들은 개념에 익숙하지 않은 독자들은 보충 자료를 참조하라고 말합니다. decoder 역시 permutation-invariant하기 때문에, N input embedding들은 다른 결과를 생성하기 위해 반드시 달라야 하죠. 이 input embeddings는 학습된 positional encoding인데요. 저자들은 이를 object queries라고 부른답니다. 인코더에서와 유사하게 저자들은 object queries를 각 attention layer의 input에 더합니다. N개의 object queries는 decoder에 의해 output embedding에 transformed 됩니다. 그럼으로 그들은 independently decoded 되죠. 즉, FFN에 의해 box coordinates와 class labels로 말이죠. 이는 final prediction N개의 결과이기도 하고요. self-attention과 encoder-decoder attention을 사용해서, model은 globally하게 all objects에 대해 이유를 제시합니다. all objects 간의 pair-wise relations를 사용해서 말이죠. context로써 whole image를 사용할 수 있죠.
Prediction feed-forward networks ( FFNs )
final prediction는 ReLU activation function과 hidden dimension d를 가진 3-layer perceptron과 linear projection layer에 의해 계산됩니다. FFN은 input images에 대해 box의 normalized center coordinates와 height 그리고 width를 예측합니다.
linear layer는 class label을 softmax function을 사용해서 예측합니다. 저자들은 N bounding boxes의 fixed-size set을 예측하기 때문에, ( N은 images에서 objects of interest의 실제 숫자보다 훨씬 큽니다 ) additional special class label 공집합은 slot 에서 object가 detected 되지 않았음을 나타낼때 사용합니다. 이 class는 standard object detection approaches에서 class background와 유사한 역할을 합니다.
Auxiliary decoding losses
training 동안 decoder에서 auxiliary losses를 사용하는 것이 좋다는 것을 알았다고 하는데요. 특히 각 class의 올바른 objects 수를 출력하는데 도움이 된다고 하네요. 저자들은 각 decoder layer 이후에 Hungarian loss와 FFN prediction을 추가했다고 하는데요, FFN의 all predictions는 parameters로 공유합니다. 저자들은 additional shared layer-norm을 different decoder layer로부터 prediction FFNs에서 input을 normalize하기 위해 사용했다고 하네요.
그 아래 실험적인 부분과 고찰 부분은 생략하도록 하겠습니다
다음 글에서는 부록에서 다루고 있는 개념들을 정리해 볼까합니다.
그럼 다음 글에서 뵐께요



