안녕하세요. WH입니다.
오늘은 매우 핫한 논문들의 base를 이루는 기초(?) 논문 리뷰입니다.
사실 다루지 않을까도 했는데
정리도 다시할 겸, 정리하겠습니다.
사실 이 논문을 정리하려면
seq2seq 논문이나 기타 정리해야할 논문들이 있습니다만..
생각 좀 해보겠습니다.
computer vision에 transformer가 architecture가 적용되면서
한번은 리뷰하면 누군가는 보지 않을까하는 생각에 리뷰합니다.
이 블로그에서 정리한 논문 중에는
정확히는 기억이 나질 않지만
Vivit, Vit( 이걸 다뤘나요 ? ), MTV 등이 있겠지요.
물론 이 논문은 자연어 처리와 관련된 논문입니다만,
CNN을 모르고 computer vision을 한다는 것이 말이 되지 않는 것처럼
요즘 나오는 architecture를 알기위해
이 논문 리뷰는 반드시 100% 이해하고 넘어가길
반드시 추천드립니다.
Abstract
지배적인 sequence transduction models는 encoder와 decoder를 포함하는 complex recurrent 나 econvolutionla neural networks에 기반하는데요. 가장 perfoming models 역시 attention mechanism을 통해 encoder와 decoder가 연결됩니다. 저자들은 Transformer라는 새로운 simple network architecture를 제안합니다. Transformer는 attention mechanism에 기반합니다. recurrence와 convolutions를 전부 생략한 것이 특징입니다. two machine translation 실험은 이 모델들이 quality 측면에서 우위에 있는 모습을 보여주고 기존보다 병렬화에 강점이 있으며 짧은 train 시간을 필요하다는 것을 보여줍니다. 이 아래 내용은 성능 면에서 뛰어나며 학습 시간 또한 짧았다는 실험 결과에 대해 요약하고 있습니다.
Introduction
REcurrent neural networks( RNN )은 ( 특히, long short-term memory 와 gated recurrent neural networks ) language modeling과 machine translation 같은 sequence modeling과 transduction problems에서 SOTA approaches 로 자리를 잡았는데요. 수 많은 노력들은 recurrent language models와 encoder-decoder architectures의 boundaries를 지속적으로 push 했습니다. Reucurrent models는 전통적으로 input과 output sequence의 symbol positions 에 따라 계산을 인자로 하는데요. computation time에서 steps로 positions를 Aligning하면, 그들은 이전 hidden state h_t-1 와 position t의 input에 대한 function으로 hidden states h_t를 생성합니다. 이 본질적으로 sequential nature은 training examples에서 parallelization 배제하는 것인데요. 이것은 memory constraints가 exampes 간에 batching을 제한하기 때문에 longer sequence lenghts에서 중요합니다. 최근 연구( 최근은 아니지만 ) conditional computation과 fatorizaion tricks를 통해 computational efficiency에서 중요한 성과를 이룩했다고 하네요. conditional computation의 경우는 모델의 성능역시 향상시켰다고 하고요, 그러지만 본질적은 sequential computation의 constraint는 존재한다고 합니다.
Attention mechanism은 input이나 output sequence에서 그들의 distance에 관계 없는 dependencies의 modeling을 허용하는 various task에서 compell한 sequence modeling과 transduction models에 필수적 요소가 되었는데요. 그러나 당시까지만 해도 몇몇 case를 제외하고 attention mechanisms는 recurrent network와 함께 사용되었다고 합니다.
이 논문에서 저자들은 Transformer를 제안합니다. Transformer는 recurrence를 피하는 model architectur이고 input과 output 사이의 global dependecies를 draw하기 위해 전적으로 attention mechanism을 사용합니다. Transformer는 훨씬더 많은 parallelization을 가능하게 하며 SOTA를 달성했습니다.
Background
sequential computation을 reducing하는 목표는 Extended Neural GPU, ByteNet 과 ConvS2S 의 foundation을 형성하는 건데요. 이들은 basic building block으로 CNN을 사용하고 all input 과 output position에 대해 병렬적으로 hidden representation을 계산합니다. 이런 모델들에서, 두개의 임의의 input 이나 output positions로 부터 singals를 relate하기 위해 요구되는 연산의 수는 positions 사이의 distance 에 따라 늘어납니다. ConvS2S는 linearly 하게, ByteNet은 logarithmically 하게 늘어나죠. 이것이 distant positions 간에 dependencies를 학습하는 것을 더 어렵게 만들죠. Transformer에서는 이것은 attention-weighted position를 averaging하기 때문에 reduced effective resolution의 cost ( Multi-Head Attention의 영향 ) 에도 불구하고 operations의 constant number로 감소합니다.
Self-attention은 때때로 intra-attention이라고도 불립니다. self-attention은 sequence의 representation을 계산하기 위한 single sequence 의 different positions와 관계된 attention mehanism입니다. Self-attention은 많은 분야에서 성공적으로 사용된다고 하네요
End-to-End memory networks는 sequence-aligned recurrence 대신 recurrent attention mechanism에 기반합니다. simple-languate question answering and language modeling task에서 잘 작동하죠
그러나 Transformer는 sequence aligned RNNS 이나 convolution없이 input과 output의 representation을 계산하기 위한 self-attention으로만 이루어진 최초의 transduction modeling 입니다. 다음 파트에서 Transformer를 묘사하고, self-attention에 대해 환기하며, 기존 모델을 뛰어넘는 이점에 대해 논의합니다.
Model Architecture
most competitive neural sequence transduction models는 encoder-decoder structur입니다. encoder는 symbol representations의 input sequence를 contunuous representation z의 sequece에 매핑합니다. z가 주어지면, decoder 는 한 symbols의 output sequence를 한 번에 한 요소씩 생성합니다. 각 step에서 model은 auto-regressive인데요. 다음 generating에서 additional input으로 이전 생성된 symbols를 소비합니다.
Transformer는 self-attention과 point-wise, fully connected layers를 encoder와 decoder에 대해 쌓은 architecture를 따릅니다. 아래 그림을 참고하세요

Encoder and Decoder stacks
Encoder
encoder는 6 개의 indentical layer를 쌓아 구성되었습니다. 각 layer는 두 개의 sub-layers를 가집니다. 첫 번째는 multi-head self-attention mechanism이고 다른 하나는 간단한 position wise fully connected feed-forward network입니다. 저자들은 residual connection을 두 개의 sub-layer에 사용했습니다. 따라서 sub-layer의 output은 LayerNorm(x + Sublater(x) )가 됩니다. 여기서 Sublayer(x)는 sub-layer에 의해 구현된 function입니다. 이 residual connections를 사용하기 위해, embedding layers를 포함하는 모든 sub-layers는 dimension의 output을 생성합니다. ( d_model = 512 )
Decoder
decoder 역시 6 개의 identical layers로 구성되어 있습니다. 게다가 각 encoder layer의 두 개의 sub-layer에서 decoder는 third sub-layer를 insert합니다. 이는 encoder stack에 걸쳐 multi-head attention을 수행합니다. encoder와 유사하게, 저자들은 resideual connections를 각 sub-layers에 걸쳐 사용했는데요. 저자들은 decoder stack에서 attending to subsequent positions로부터 position을 방지하기하기 위해 self-attention sub-layer를 변형했습니다. 이 masking은 output embedding은 one position으로 offset 하는 사실에 합쳐져 position i 에 대한 predictions를 i 보다 작은 position에서 알려진 ouptputs에만 의존할 수 있게 합니다.
Attention
attention funtion은 output에 query와 key-value쌍을 매핑하는 것을 말하는데요. query, key, value와 output은 모두 vector입니다. output은 value의 weighted sum으로 계산됩니다. value에 assinged된 weight는 해당 key를 가진 query의 compatibility function에 의해 계산됩니다.

Scaled Dot-Product Attention
저자들은 자신들의 particular attention을 " Scaled Dot-Product Attention" 이라고 부르는데요. input은 dimension d_k의 queris와 key, 그리고 d_v dimension의 values로 구성되어 있습니다. 저자들은 all keys를 query와 dot products를 계산합니다. 각각은 (루트 d_k )로 나눠지죠. 그리고 softmax funtion을 value의 weights를 얻기 위해 적용합니다.
실제로, 저자들은 attention function을 queris 의 set에서 동시에 계산합니다. matrix Q로 묶어서 말이죠. keys는 marices K와 V에 함께 묶여있습니다. 저자들은 아래의 식으로서 outputs의 matrix를 계산합니다
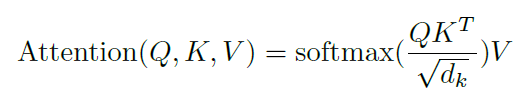
두 가지 most commonly used attention functions는 additive attention과 dot-product attention입니다. Dot-product attention은 저자들의 algorithm에서 indentical합니다. scaling factor로 나눠준 것을 제외하면 말이죠. additive attention은 a single hidden layer에서 feed-forward netowrk를 사용하여 compatibility function을 계싼합니다. 두 가지는 theoretical complexity면에서 유사하지만, dot-product attention은 훨씬 빠르고 공간 효과적입니다. 왜냐하면 highly optimized matrix multiplication code를 사용해서 구현되었기 때문이죠.
d_k의 samll values에 대해 두 mechanisms 는 유사하게 작동하지만. additive attention 은 d_k의 larger values에 대해 scaling이 없이 dot product attention을 능가합니다. 저자들은 d_k의 large values 에 대해 ( dot products는 magnitude에 따라 커집니다 ) softmax function이 매우 작은 값으로 만드는 것이 아닐까 의심했다고 합니다. 이 효과를 줄이기 위해, dot products를 scaling 했다고 합니다
Multi-Head Attention
d_model dimensional key, value 그리고 queries를 가지고 single attention fuction이 수행되는 대신에, 저자들은 queris, keys, values를 linearly project하는 것이 beneficial하다는 것을 알아냈다고 합니다. 각각의 projected version의 queris, keys 그리고 values 를 가지고 저자들은 병렬적으로 attention function을 수행했다고 합니다. 이것들은 합쳐지고 다시한번 projected됩니다. 그렇게 final values가 되고 Figure 2에서 볼 수 있죠. Multi-head attention은 model이 다른 positions에서 다른 representation subspaces로 부터 information에 jointly attend하게 해줍니다. Single attention head에서는 averaging이 이것을 막습니다.

논문에서는 h=8 parallel attention layers 나 heads가 사용되었습니다. 각각에 대해 d_k=d_v=d_model/h = 64입니다. 각 head의 reduced dimension 때문에 total computational cost는 fully dimensionality에서 single-head attention과 유사합니다.
Applications of Attention in our Model
Transforemr는 multi-head attention을 3 가지 다른 방식으로 사용합니다.
1. "encoder-decoder attention" layer에서, 이전 decoder layer로부터 queies가 나옵니다. 그리고 memory keys 와 values 가 encoder의 output으로 부터 나오죠. 이는 decoder에서 every position이 input sequence에서 all position에 걸쳐 attend하도록 합니다. 이것은 seq2seq model의 typical encoder-decoder attention mechanisms를 모방한 것입니다.
2. encoder는 self-attention layer를 포함합니다. self-attention layer에서 keys, values 그리고 queries 모두는 같은 곳으로부터 나오는데요. 이 경우, encoder에서 이전 layer의 output이 되겠습니다. encoder에서 각 position은 encoder의 이전 layer에서 all position을 attend 할 수 있습니다.
3. 유사하게, decoder에서 self-attention layers는 decoder에서 각 position이 해당 position을 포함해서 decoder의 모든 positions에 attend하도록 합니다. 저자들은 auto-regressice property를 보존하기 위해 decoder에서 leftward information flow를 방지해야했습니다. 저자들은 illegal connetions 해당하는 모든 softmax의 input value를 masking 함으로써 scaled dot-product attention을 대신하여 이것을 구현했다고 합니다.
position-wise Feed-Forward Networks
attention sub-layer와 더불어, 각 layer는 fully connected feed-forward network를 포함하는데요, 이것은 각 position에 각각 똑같이 적용됩니다. 이것은 두 개의 linear transformations와 그 사이에 relu를 activation으로 구성한다고 합니다.

different positions에 따라 linear transformation이 같은 반면, layer에서 layer까지는 다른 파라미터를 사용합니다. 다른 방법으로는 kernel size 1인 convlolutions를 사용하여 표현됩니다.
Embeddings and softmax
sequence transduction models와 비슷하게 저자들은 learned embedding을 d_model의 vetor에서 output tokens와 input tokens를 변환하기 위해 사용했다고 하는데요. 저자들은 usual learned linear transformation 과 softmax fuction을 예측된 next-token probabilities에서 decoder output을 convert하기 위해 사용했다고 하네요. 저자들은 같은 weight matrix를 two embeddin layers와 pre-softmax linear transformation 이 공유하도록 했다고 합니다. embedding layer에서 루트 d_model 을 weights에 곱해준다고 하네요
Positional Encoding
저자들의 모델이 recurrence와 convolution이 없기 때문에 sequence의 order를 사용하게 하기 위해, 저자들은 relative 혹은 absolute postion 에 대한 약간의 정보를 inject해야만 했는데요. 저자들은 positional encodings를 추가 했다고 합니다. 이는 encoder와 decoder stacks의 밑 바닥에 input embeddins에 넣었다고 하네요. positional encodings는 d_model과 같은 dimension를 가지고 두 개는 더해진다고 하네요. positional encodings을 위한 많은 선택을 할 수 있는데요. 저자들은 sine 과 cosine funtions를 사용했다고 합니다.
이 정도로 정리해볼게요.
읽어주셔서 감사합니다.



