하다보니 6 번째 글이네요
왜 이렇게 길게 다 다루냐..
그래서 고민입니다. 정리하는 게 생각보다 시간이 많이 걸리거든요
그래도 제목에 맞게 정리해보겠습니다 ㅎㅎ
여튼 시작합니다.
오늘은 Feature Clustering입니다.
2022.06.23 - [AI 논문] - [꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 5
[꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 5
안녕하세요, WH입니다. 오늘은 저번 글에 이어서 data-based interpretation의 두 번째 파트입니다. feature transformation strategy 인데요 그 중에서도 feature reduction에 대해 다루고 있습니다. 오늘은 feat..
developer-wh.tistory.com
Feature Clustering
Feature clustering 은 original features의 더 추상적인 feature representation을 찾는 것을 목표로 합니다. 비록 feature clustering이 feature extraction으로 간주되긴 하지만, 전에 언급한 mapping-based extraction과는 다릅니다.
예를 들면, 몇몇 transfer learning approaches는 명시적으로 co-clustering technique을 사용해서 features를 줄입니다. information theory에 기반한 contingency table의 행과 열을 ( co-cluster라고 불리는 ) clustering하는 법등이 예입니다. Dai의 연구는 Co-Clustering Based classification( CoCC )이라는 알고리즘을 제안합니다. document classification에 사용되죠. document classification 문제에서 transfer learning task는 labeled source document-to-word data를 가지고 target--domain documents를 분류합니다. CoCC는 co-clustering technique을 지식 transfer를 위한 bridge로 여깁니다. CoCC algorithm에서 source and target document-to-word marices 는 co-clustered 됩니다. source document-to-word matrix는 알려진 label information에 기반해 word cluster를 생성하기 위해 co-clustered 됩니다. 그리고 이 word cluster는 target-domin data의 co-clustering 과정동안 constrains로 사용됩니다. co-clustering 기준은 mutual informaion에서 loss를 최소화하는 것이고 clustering 결과는 iteration을 통해 얻어집니다. 각 iteration은 2 가지 단계를 포함합니다.
1. Document Clustering
- target document-to-word matrix의 행은 document cluster updating을 위한 objective function에 기반해 재정렬됩니다.
2. Word Clustering
- word cluster는 source and target document-word matrices 의 mutual-informaion loss를 최소화하기 위해 조정됩니다.
몇 번의 interation 후에, algorith은 수렴하고 classification 결과가 얻어집니다. CoCC에서 word clustering process는 균일한 word cluster를 형성하는 word feature를 추출합니다.
Dai는 unsupervised clustering approach를 제안합니다. Self-Taught Clustering ( STC )인데요. CoCC와 유사하게, 이 algorithm은 co-clustering based one입니다. 그러나 STC는 label information을 필요로 하지 않습니다. STC는 source와 target domain이 common feature space에서 same feature cluster를 공유한다는 가정하에 cocluster하는 것을 목적으로 합니다. 그럼으로 two co-clustering task는 동시에 개별적으로 shared feature clusters를 찾기 위해 수행됩니다. 각각 iteration 은 아래의 단계를 따릅니다.
1. Instance Clustering
- source domain 과 target domain의 clustering results는 mutual information에서 respective loss를 최소화하기 위해 업
데이트 됩니다.
2. Feature Clustering
- feature clusters는 mutual information 에서 joint loss를 최소화 하기 위해 업데이트 됩니다.
algorithm이 수렴하면, target-domain instances의 clustering results가 얻어집니다.
위에 언급한 co-clustering-based 연구와 다른 데, 몇몇 approaches는 concept( or topic )으로 original feature를 추출합니다. document classification probelm에서 concepts는 high-level abstractness of words( word cluster 과 같은 )를 나타냅니다. concept-based transfer learning approaches를 쉽게 소개하기 위해, Latent Semantic Analysis( LSA ) 되짚어보는데요. Probabilistic LSA ( PLSA )와 Dual-PLSA 는 아래에서 설명합니다.
LSA
- LSA는 SVD technique에 기반한 document-to-word matrix을 low-dimensional space로 맵핑하는 approach입니다. 짧
게, LSA는 words의 true meaning를 찾고자 시도합니다. 이를 실현하기 위해, SVD technique은 dimensionality를 축소
하는 데 사용됩니다. irrelevant information을 제거하고 raw data로 부터 noise를 filter out 합니다.
PLSA
- PLSA는 LSA의 statistical 관점에 기반해 developed 되었는데요. PLSA는 concept을 reflect하고 document d와 word w
와 관련된 latent class variable z 가 있다고 가정합니다. 게다가 d와 w는 z에 개별적으로 conditioned 되는데요. 이
graphical modle의 diagram은 아래와 같이 표현됩니다.

i와 j, k는 document, word, concept의 index를 나타냅니다. PLSA는 Baysian network를 설계합니다. 그리고 파라미터들
은 Expectation-Maximization( EM ) algorithm을 통해 추정됩니다.
Dual-PLSA
- Dual-PLSA는 PLSA의 확장판인데요, 이 approach는 z_d와 z_w latent variables가 있다고 가정합니다. 특별히 z_d와
z_w는 document 와 word 의 concept를 반영합니다. Dual-PLSA의 diagram은 아래와 같습니다.
Dual-PLSA의 파라미터들은 EM algorithm에 기반해 구해집니다.
몇몇 concept-based transfer learning approaches는 PLSA에 기반하여 설계되었는데요. Xue의 논문에서는 Topic-Bridged Probablistic Latent Semantic Analysis(TPLSA) 라는 cross-domain text classification approach를 제안합니다. TPLSA 는 PLSA의 확장판으로 source-domain과 target-domain의 instances가 words 의 같은 mixing concepts를 공유한다고 가정합니다. 두 PLSA가 source domain과 target domain에 각각 수행되는 대신에, 저자는 이 두 PLSA가 mixing concept z 를 bridege로 사용하여 integrated 됩니다. 각각의 concept는source-domain and target-domain document를 생성할 probabilities 가지고 있습니다. TPLSA의 diagram은 아래와 같습니다
PLSA는 label information을 필요로 하지 않는다는 것을 상기하시길 바랍니다. label information을 사용하기 위해, 저자는 concept constraints를 추가합니다. 이는 TPLSA의 objective funtion에서 penalty term입니다. 결론적으로 objective function은 EM algorithm을 활용해서 classificatkon results를 얻기 위해 반복적으로 최적화됩니다.
Zhuang의 연구는 multi-domain text classification을 위해 Collaborative Dual-PLSA( CD-PLSA )를 제안합니다. diagram은 아래와 같습니다.
의 조건에서 k_0는 domain index입니다. domain D는 variables d와 w 와 연결되고 z^d와 z^w는 각각 독립적입니다.
값을 초기화하는 데 source-domain instance의 label information가 사용됩니다. target-domain label information의 부족함 때문에 P(d_i | z^d_k) 값은 supervised classifier에 기반해 초기화 됩니다. 유사하게 저자는 파라미터를 찾기위해 EM algorithm을 적용합니다. iterations를 통해, Bayesian network의 모든 파라미터들이 얻어집니다. 따라서, target domain 속 i번째 document의 class label은 posterior probabilities를 계산하여 예측됩니다. 즉 아래의 식을 계산합니다
저자는 나아가 general framework을 제안하는데요. Homogeneous-Identical-Distinct-Concept Model( HIDC ) 입니다. 이 framework는 Dual-PLSA의 확장판인데요. HIDC는 3가지 generative model로 구성됩니다. identical-concept, homogeneous-concept, 그리고 distict-concept model이 그 구성입니다. 이 3 가지 모델은 아래와 같이 표현됩니다.
original word concept z^w는 3가지 타입으로 나눠집니다.
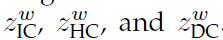
identical-concept model에서는 word distributions가 word concepts에 의존합니다. word concepts는 domain과 독립적입니다. 그러나 homogeneous-concept model에서는 word distributions는 domain에 의존합니다. identical and homogeneous concept의 차이는 z_IC 는 직접 transferable하지만, z_HC는 different domains마다 word distributions에 다른 효과를 미치는 domain-specific transferable 하다는 점입니다. distinct-concept model, z_DC는 실제로 nontransferable domain-specific 한 모델인데요. specific domain에서만 찾아볼 수 있습니다. 위에 언급된 3가지 모델은 integrated one으로 합쳐집니다. HIDC는 파라미터를 얻기 위해 EM algorithm을 사용합니다.
아직도 리뷰해야할 부분이 한참이나 남았지만
해당 논문에 대한 리뷰는 잠시 미뤄야 할 것 같습니다.
그러나 한 가지는 약속드립니다.
마무리되지 않은 논문이 현재 2가지가 있는데
이번 논문을 포함해 해당 논문 역시 마무리는 확실하게 지을게요
다음 글은 아마 tracking에 관한 논문이 될 것 같아요
이상 wh였습니다.



