안녕하세요, WH입니다.
오늘은 Feature Transformation Strategy을 다루려고합니다
이 부분도 많아서 아마도 나눠서 글을 올릴듯 하네요.
2022.06.22 - [AI 논문] - [꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 3
[꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 3
안녕하세요, WH입니다. 오늘은 저번 글에 이어서 data-based interpretation부터 시작할게요 잠깐 이번 논문을 왜 읽어야 하는가에 대해 언급하고 넘어가겠습니다. 최근 리뷰하는 논문들은 대게 최신 논
developer-wh.tistory.com
Feature Transformation Strategy
Featur transformation strategy는 feature-based approach에 적용됩니다. 예를들어 text clssification 문제의 cross-domain을 고려해봅시다. task는 domain과 관련된 labeled txt data를 사용해서 target classifier를 만드는 일입니다. 이 시나리오에서 feasible 한 soultion은 feature transformation을 통해 공통된 latent features 찾고 지식을 transfer할 연결 고리로 사용하는 겁니다. Feature-based approaches는 원래의 feature를 지식 transfer를 위한 새로운 feature로 transform 합니다. 새로운 feature를 설계하는 objectives는 marginal and conditional distribution difference를 최소화하는 것, 데이터의 potential structures 나 특성을 보존하고, features 사이의 상관 관계를 찾는 것을 포함합니다. feature transformation 의 operations는 3 가지 type으로 나눠질 수 있습니다. ( feature augmentation, feature reduction, and feature alignment 입니다.) 게다가 feature reduction은 feature mapping, feature clustering, feature selection, and feature encoding으로 나눠질 수 있죠. 완전한 feature transformation process는 몇개의 operations로 이루어져 있습니다.
Distribution Difference Metric
feature transformation의 primary objective는 sourece와 target domain instance의 distribution difference 줄이는 겁니다. 따라서 domians 간의 유사도나 차이를 효과적으로 측정하는 방법은 중요한 문제입니다.
Maximum Mean Discrepancy(MMD)라는 측정법은 transfer learning 에서 광범위하게 사용되며, 식은 아래와 같습니다.

MMD는 kernel trick을 사용하여 쉽게 계산할 수 있는데요. 간결하게 말하면, MMD는 RKHS에서 instacnes의 mean value의 distance( 거리라고 한글 표현을 사용하지 않은 이유는 많은 종류의 거리가 있기 때문입니다 )를 계산함으로써 distribution difference를 정량화합니다. 전에 언급한 KMM은 실제로 domains 간의 MMD distance를 최소화함으로써 instance의 weight를 생성합니다.

Table 2에서는 은히 사용되는 metric과 관련된 algorithms을 목록이 있습니다. transfer learning에 적용된 몇 개의 측정 기준이 있습니다. Wasserstein distance, central moment discrepancy 등등 입니다. 몇몇 연구는 존재하는 측정법을 향상시키고 최적화 시키는 데 초점이 맞춰져 있습니다. MMD를 예로 들겠습니다. MMD의 경우 MK-MMD( multi kernel verson of MMD ) multi kernel를 사용합니다. 게다가 다른 연구자는 class weight bias 문제를 해결하기 위해 weight version of MMD를 제안합니다.
Feature Augmentation
Feature augmentation operations는 feature transformaion에 광범위하게 사용됩니다. 특이 symmetric feature-based approaches에 사용되는데요. 더 자세하게 말하면, feature replication 와 feature stacking과 같은 feature augmentation를 구현하기 위한 몇가지 방법이 있는데요. 더 자세한 이해를 위해 feature replication에 기반해 만들어진 transfer learning approach를 보도록 합시다.
Daume에 의한 연구는 simple domain adaptation method를 제안합니다. Feature Augmentation Method( FAM ) 인데요. 이 method는 original features를 simple feature replication에 의해 transform 됩니다. 특별히, single source transfer learning scenario에서 feature space는 원본 사이즈의 3 배로 augmented 됩니다. new feature representation은 general feature, source-specific feature 과 target-specific features로 이뤄져 있습니다. transformed source-domain instances를 위해, target-specific features는 0으로 세팅됩니다. 유사하게 transformed target-domain instances를 위해 source-specific features 를 0으로 세팅합니다. FAM의 new feature representation은 아래의 식으로 나타납니다

파이_s와 파이_T은 새로운 feature space에 target과 source로 부터 매핑된 것을 나타냅니다. 최종 classifier는 transformed labeled instance로 학습됩니다. 이 augmentation method는 실제 중복되는 데요. 다른 말로하면, 다른 방식으로 feature space를 augmenting하는 것은 competent performance를 보여줄 수 있습니다. FAM의 우열함은 feature expansion 은
multi-source 시나리오의 일반화와 같은 좋은 특성이 되는 elegant form을 가집니다. FAM의 확장판도 제안되었는데요. 지식 transfer 과정을 용이하게 하도록 하는 unlabeled instance를 활용했다고 합니다.
그러나, FAM은 heterogeneous transfer learning task를 다루는데 효과적이지 않습니다. 이유는 feature을 relicating하고 zero vector padding 하는 것인 source와 target domain이 다른 feature representation을 가질때 덜 효과적이기 때문입니다. 이 문제를 해결하기 위해 한 학자는 Heterogeneous Feature Augmentation ( HFA )를 제안합니다. HFA의 식은 아래와 같습니다.
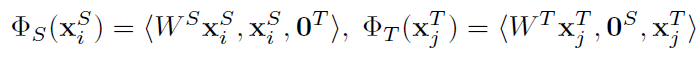
Wx 의 dimension이 S와 T에서 같은 dimension을 가집니다. 또한 0은 x_s와 x_t dimension을 가진 0 vector입니다. HFA는 original features 를 공통된 features space로 맵핑합니다. mapped features, original features, and zero elements는 새로운 feature representation을 만들기 위해 particular order로 쌓여있습니다.
이번 논문 리뷰는 여기까지입니다
Feature reduction 중
2 번째인 feature mapping에 대해 다루도록하겠습니다.
영어가 많아지는 이유는 어줍지 않은 해석보다
영어 표현이 그 상황을 더 잘나타내기 때문입니다ㅎㅎ
이상 wh였습니다.
'AI 논문' 카테고리의 다른 글
| [ 꼼꼼하게 논문 읽기 ] A comprehensive Survey on Transfer Learning 6 (0) | 2022.06.24 |
|---|---|
| [꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 5 (0) | 2022.06.23 |
| [꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 3 (0) | 2022.06.22 |
| [꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 2 (0) | 2022.06.21 |
| [꼼꼼하게 논문 읽기]A Comprehensive Survey on Transfer Learning 1 ( 2019 ) (0) | 2022.06.17 |



