안녕하세요, WH입니다.
오늘은 저번 글에 이어서 data-based interpretation부터 시작할게요
잠깐 이번 논문을 왜 읽어야 하는가에 대해 언급하고 넘어가겠습니다.
최근 리뷰하는 논문들은 대게 최신 논문이지만 해당 논문은
19년도 논문으로 최신 논문이라 하기 어렵죠
그럼에도 현업에서 일을 하다보면,
모델을 만드는 아이디어도 중요하지만 어떻게 학습을 시키느냐 역시 매우 중요합니다.
따라서 모델을 학습 시키는 데에 통찰력을 얻기 위해 필요한 논문이라고 생각이 드네요
2022.06.21 - [AI 논문] - [꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 2
[꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 2
안녕하세요, WH입니다. 오늘은 저번 글에 이어서 related work 부터 시작할게요 2022.06.17 - [AI 논문] - [꼼꼼하게 논문 읽기]A Comprehensive Survey on Transfer Learning 1 ( 2019 ) [꼼꼼하게 논문 읽기]A C..
developer-wh.tistory.com
Data-based interpretation
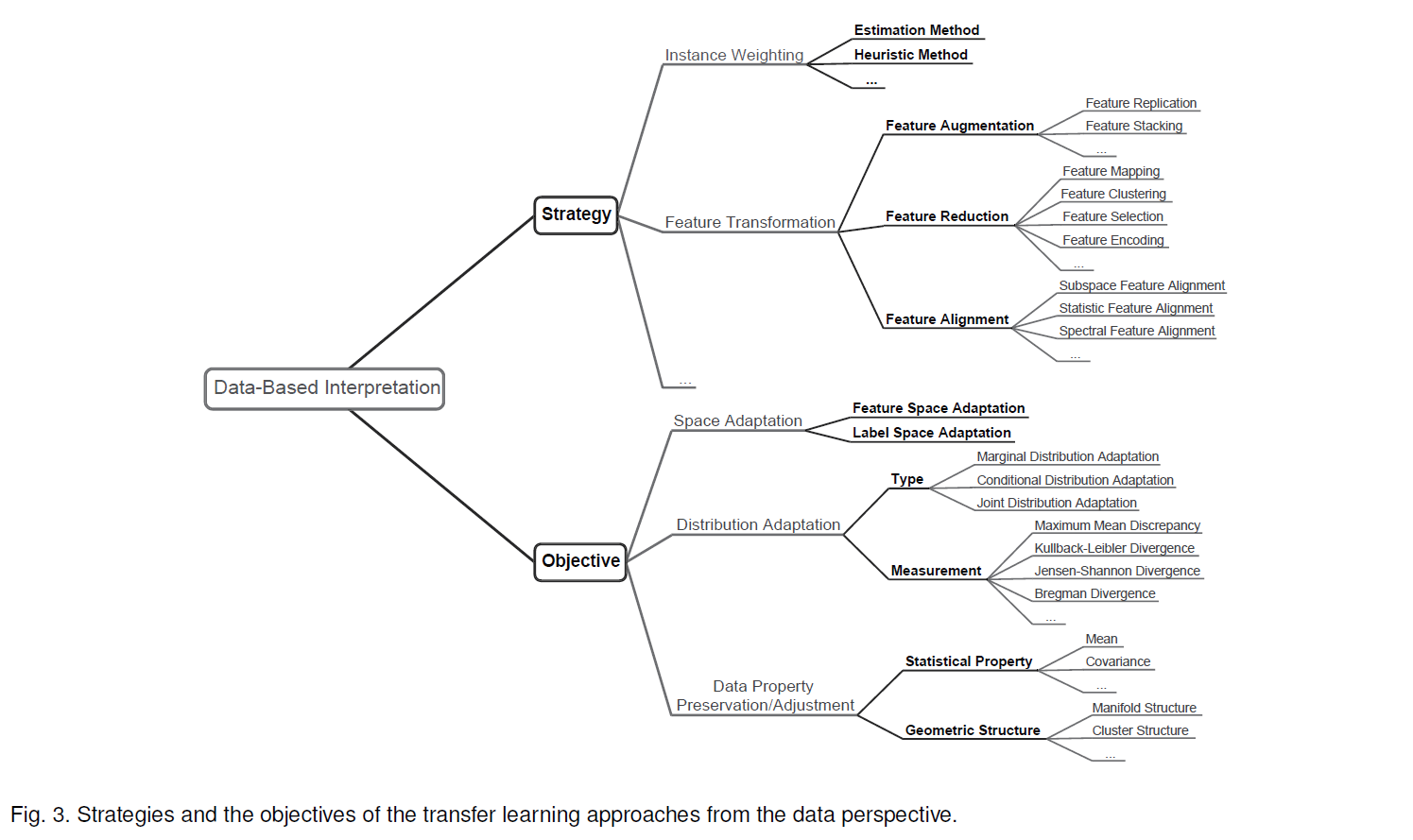
많은 transfer learning approaches는 ( 특히 data-based approaches ) data의 변황과 조정을 통해 지식을 전달하는데요. 위의 그림은 데이터 관점에서 전략과 접근에 따른 분류를 보여줍니다. 그림 3에서 볼 수 있는, space adaption은 접근 방법에 따른 분류 중 하나인데요. 해당 접근은 대게 heterogeneous transfer learning 시나리오를 요구하는 경우가 많습니다. 이 연구에서는 전에도 말했다시피, source와 target domain 사이의 분포의 차이를 줄이는 homogeneous transfer learning에 초점을 맞춥니다. 게다가 더 발전된 접근은 adaption 과정에서 data의 특성을 보존하고자 시도합니다. 데이터 관점으로부터 해당 접근을 현실화하는 데에 일반적으로 2 가지 전략이 있는데요 ( instace weighting and feature transformation ) 이 섹션에서 그림 3에 있는 내용들을 설명해 준다고 합니다.
Instance Weighting Strategy
우선 많은 양의 labeled source domain이 있고 한정된 target-domain을 가지고 있으며 domain간 차이는 marginal distribution만 차이가 있다는 시나리오를 가정해 봅시다. 가정을 식으로 표현하면 아래와 같습니다.

예를 들어보면, 우리는 나이 많은 사람들의 정보가 대부분을 차지하는 한정된 데이터를 가지고 암을 진단하는 모델을 만든다고 가정해봅시다. 그리고 우리에게는 젊은 사람들의 정보가 대부분을 차지하는 데이터를 이용할 수 있다고 해봅시다.( source domain ) 젊은 사람들의 정보가 포함된 데이터를 직접 transfering 하는 것은 marginal distribution이 다르고 나이 많은 사람들이 젊은 사람들에 비해 암에 대한 리스크가 크기 때문에 성공적이지 못할 수 있습니다. 이 시나리오에서는 marginal distribution은 adapting 하는 것이 자연스럽습니다. 가장 심플한 아이디어는 source domain 데이터의 loss fuction에 weight를 할당하는 것입니다. 위의 말을 식으로 전개해보자면 아래와 같습니다.

따라서 learning task의 일반적인 objective function은 아래와 같이 쓸 수 있습니다.
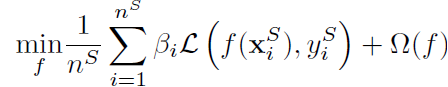
여기서 베타는 weighting parameter입니다. 이론적으로 베타_i의 값은 아래 식과 같습니다.

그렇지만 이 위 식은 일반적으로 알려져있지 않으며 전통적인 방법을 사용해서 얻어내는 것은 어렵습니다.
Kernel Mean Matching(KMM)은 위에 알려지지 않은 비율에 대한 추정 문제를 source domain과 target domain 사이의 means를 RKHS(Reproducing Kernel Hilber Space)에서 매칭시킴으로써 해결합니다. RKHS는 아래와 같습니다.

위의 식에서 델타는 매우 작은 파라미터고 베타는 constraint를 위한 파라미터입니다. 위의 최적화 문제는 kernel trick을 사용하고 확장해서 quadratic programming problem로 커버될 수 있습니다. 분포 간의 비율을 추정하기 위한 방식은 존재하는 알고리즘을 통해 쉽게 구할 수 있습니다. 한번 weight 베타를 얻으면 leaner는 source-domain 데이터로 부터 학습될 수 있습니다.
weights를 추정하기 위한 몇몇 다른 연구들이 있습니다. KLIEP ( kullback-leibler Importance Estimation Procedure ) 는 Kullback-Leibler (KL) divergence 최소화에 의존적이고 내장모델 선택 절차를 포함합니다. 이 연구에 기초해서, 몇몇 instacne-based transfer learning framework 나 algorithm이 제안되었는데요. 2SW-MDA( s-Stage Weighting Framework for Multi-Source Domain Adaption ) 을 예로 들 수 있으며 아래 두가지 전략에 따라 제안되었습니다.
1. Instance Weighting
- source-domain instances는 garginal distribution difference를 줄이는 weight가 할당됩니다.
2. Domain Weighting
- smoothness assumption에 기반한 conditional distribution difference 줄이기 위해 각각의 source domain에 Weight가 할당됩니다.
위와 같이 하면, source-domain instances는 위 전략에 따라 domain weight와 instance weight가 reweight 됩니다. 이 reweighted된 instance와 labeled target-domain이 모델 학습에 사용됩니다.
weighting parameter를 직접 추정하는 것에 더해, weights를 반복적으로 조정하는 것 또한 효과적인데요. 핵심은 target learner에 부정적 효과를 가지는 instances의 weight을 줄이는 메카니즘으로 디자인 하는 것입니다. 대표적인 연구로 TrAdaBoost가 있는데요. 이 framework는 AdaBoost의 확장판입니다. AdaBoost는 전통적인 machine learning task를 위해 디자인된 효과적인 boosting algorithm입니다. AdaBoost의 각 iteration에서 learner는 데이터를 가지고 weights를 update하며( weak classifer가 되는 ) 학습됩니다. instance의 weighting mechanism은 분류가 잘못된 경우 더욱 많은 주의를 기울이는 것을 보장합니다. 결론적으로, 결과로 만들어진 weak classifier들은 strong classifier를 만들기 위해 합쳐집니다. TrAdaBoost는 transfer learning 시나리오에서 AdaBoost 확장하는데요. distribution difference의 영향을 줄이기 위해 새로운 weighting mechanism이 디자인 되었습니다. 특별히, TrAdaBoost에서는 labeled source domain instance와 labeled target domain instance 전체가 weak classifier를 학습하기위해 training set으로 결합됩니다. source domain instance를 위한 weighting operations와 target domain instance weighting operations가 다른데요. 각 interation에서 labeled target domain instance에 대해 classifer의 error를 측정하는임시 변수 델타가 계산됩니다. 그 이후에, target-domain instance의 weights가 델타와 각각 분류결과에 기반하여 업데이트됩니다. 반면에 source-domain instance의 weights는 디자인된 상수와 각각의 분류 결과에 기반해 업데이트됩니다. 즉 위의 언급을 k-th interation에 대해 식으로 보여 드리면 아래와 같습니다.

각 iteration은 새로운 new classifier를 형성합니다. 그리고 최종 classifier는 voting scheme를 통해 weak classifiers의 반을 앙상블하고 합치는 방식으로 만들어집니다.
TrAdaBoost를 확장한 몇몇의 연구가 있는데요. 그게 바로 MsTrAdaBoost algorithm입니다. 그리고 MsTrAdaBoost는 각 iteration에서 아래의 두 단계를 따릅니다.
1. Candidate Classifier construction
- weak classifiers의 후보 그룹은 source domain과 target domain 쌍으로 구성된 weighted instance 에서 훈련됩니다.
2. instance Weighting
- target domain에서 최소 분류 error 델타를 가지는 classifier는 target과 source domain instance의 weight를 업데이트 하는 데 사용됩니다.
결과적으로, 각 iteration에서 선택된 classifier들은 합쳐지고 최종 classifier를 만들게 됩니다. 다른 parameter-based algorithm은 TaskTrAdaBoost인데요 이는 뒤에서 소개한다고 합니다.
몇몇 approaches는 heuristic(발견적) 방법으로 instance weighting strategy를 실현하는 데요. 해당 framework의 objective function에 3 가지 타입의 instance의 cross-entropy loss를 최소화 하도록 디자인된 3 가지 terms 있습니다. 아래 instances의 타입들은 target classifier를 만드는데 사용됩니다.
1. Labeled Target-domain Instance
- classifier는 해당 instance에서 cross-entropy를 최소화해야 합니다.
2. Unlabeled distribution
- instances의 실제 조건 분포가 알려져 있지 않기 때문에 추정해야합니다. 가능한 solution은 조건 분포를 추정하는 것을 돕고 가짜의 label을 할당하기 위해 보조 classifier를 labeled domain과 target domain에서 학습하는 것입니다.
3. Labeled Source-domain instance
- weight X를 알파와 베타로 나누었습니다. 베타는 KMM 과 같은 non-parametric method로 추정할 수 있고, 최악의 경우 uniformly 하게 설정할 수 있습니다. 알파는 target domain과 확연히 다른 source domain instance를 걸러냅니다.
heuristic method는 알파를 생성하는데 사용되며, 아래 3 단계를 따릅니다.
1. Auxiliary Classifier Construction
- 보조 classifier는 target-domain에서 학습되고 unlabeled source-domain instance를 분류하는 데 사용합니다.
2. instance Ranking
- source-domain instance는 probabilistic prediction results에 기반해서 순위를 매깁니다.
3. Heuristic Weighting ( 베타 )
- 잘못된 예측결과에 대한 top-k source-domain instance의 weights는 0으로 세팅됩니다. 그리고 다른 weights는 1로 세
팅 됩니다.
이번 논문 리뷰는 여기까지 하고 다음 논문에서는
Feature Transformation Strategy에 대해 다루도록하겠습니다.
뭔가 상당히 긴 여정이 될것 같다는 느낌이 오네요.. ㅎㅎ
이상 wh였습니다.
'AI 논문' 카테고리의 다른 글
| [꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 5 (0) | 2022.06.23 |
|---|---|
| [꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 4 (0) | 2022.06.23 |
| [꼼꼼하게 논문 읽기] A comprehensive Survey on Transfer Learning 2 (0) | 2022.06.21 |
| [꼼꼼하게 논문 읽기]A Comprehensive Survey on Transfer Learning 1 ( 2019 ) (0) | 2022.06.17 |
| [꼼꼼하게 논문 읽기] Multiscale Vision Transformers 1 (0) | 2022.06.09 |


