Background
시작하기에 앞서, 왜 갑자기 Detection 논문을 읽는지에 대해, 잠깐 짚고 넘어가려고 합니다. skeleton based model의 큰 문제점은 무엇일까요? 정확도? 속도? 이를 다따지기 전에, single person과 multi person interaction에 대한 action만을 recognize 할 수 있다는 거죠. 그럼 내가 제품을 상용화해야하는데, edge device가 single or multi person만 추론할 수 있다? 음..아무도 안쓰겠죠? 그래서 이를 detection의 two stream 방식으로 system을 구성하기 위해 이 논문을 보게 된거죠. 물론 보기야 봤었지만, 정리를 한다는 것은 제가 프로젝트에 고려하겠다는 말과 같다고 보시면 됩니다.
Abstract
object detection에서, keypoint based approaches는 incorrect object bounding boxes의 large number 때문에 문제가 되죠. 이는 cropped regions으로 additional look의 lack 때문이라고 말하죠. 이 연구는 efficient solution을 제안하는데 각 minimal costs를 가진 cropped regions에서 visual parrerns을 사용하죠. 저자들은 CornerNet이라 불리는 representative one-stage keypoint-based detector에 기반하여 설계하죠. 이가 바로 CenterNet이고 각 object를 kepoints의 triplet 으로 detect 하죠. 이는 percision과 recall에 향상을 가져왔고요. 저자들은 two customized modules를 design하는데 각각 cascade corner pooling 과 center pooling 이라고 불리죠. 이들은 각각 top-left와 bottom-right coners에 의해 collected된 information을 enriching하고 central regions에서 more recognizable information을 제공하는 데 중요 역할을 하죠. 성능에 대한 내용은 생략할게요
Introduction
Object detection은 deep learning에 힘입어 엄청난 발전을 해왔죠. 특히 CNNs의 도움이 컸습니다. 가장 대중적인 흐름 중 하나는 anchor-based 이고, pre-defined sized를 가진 rectangles의 set을 배치하죠. 그리고 ground-truth objects의 도움을 바탕으로 desired place로 rectangles들을 regressed 하죠. 이 approaches는 종종 ground-truth objects를 활용해 high IoU rate를 ensure하는 수 많은 anchors가 필요하죠. 그리고 anchor box의 size와 aspect ratio는 manually하게 designed 되어야하죠. 게다가 anchors는 ground-truth boxes와 aligned되지 않죠. 이는 bounding box classification task에 conducive 하지 않고요.
이 anchor-based approaches의 drawback을 극복하기위해, CornerNet이라는 keypoint-based object detection pipline 이 제안되었죠. CornerNet은 각 object를 coner keypoints의 pair에 의해 각 object를 represented하죠. 이는 anchor boxes의 need를 bypassed 하고 SOTA object detection accuracy를 achieved 했죠. 그럼에도 불구하고, CornerNet의 performance는 object의 global information를 refer하는 weak ability 에 의해 여전히 restricted 되죠. 다시 말해, 각 object는 corners의 pair로 constructed 되기 때문에, algorithm은 objects의 boundary를 detect하는 것에 sensitive하죠. 반면에, keypoints의 pairs를 object로 grouped 해야할지에 대해서는 알지 못하죠. 결과적으로, Figure 1에서 보여지는 것과 같이, incorrect bounding boxes를 생성하죠. 물론 이들 중 대다수는 aspect ratio와 같은 complementary information을 활용해 쉽게 filtered 될 수 있지만요.

이 문제를 해결하기 위해, CornerNet에 각 proposed region에서 visual patterns를 perceiving 하는 ability를 equip 했다고 합니다. 그렇게 함으로써, CornerNet은 스스로 bounding box의 correctness를 identify 할 수 있죠. 이 논문에서, 저자들은 CenterNet을 제안합니다. 이는 proposal의 central part를 explore하죠. 가령, 하나의 extra keypoint를 가진 geometric center과 가까운 region이 예시가 되겠죠. 저자들의 직관은 predicted bounding box가 ground-truth box와 high IoU를 가진다면, its central region에 대한 center keypoint가 같은 class로 predicted 될 확률이 높을 것이며 그 역에 대해서도 성립할 것이란 거죠. 따라서, inference 동안, proposal이 corner keypoins로 generated 된 이후에, its central region 안에 same class falling의 center keypoint가 있는지를 checking 함으로써 그 proposal 이 실제 object인지를 결정하죠. 이 idea는 Figure 1에 나타나 있고, 각 object를 represent하는 keypoints의 triplet을 사용하죠.
center keypoints와 corner을 더 잘 detecting하기 위해, center와 corner information을 enrich하게 해주는 두 가지 strategies를 제안합니다. 첫 번째 strategy는 cneter pooling입니다. 이는 branch에서 center keypoints를 predicting 하는 데에 사용되죠. Center pooling은 center key points가 object내 에서 more recognizable visual patterns을 얻는 데 도움이 되죠. 이는 proposal의 central part를 perceive하는 것을 더 쉽게 만들기도 하고요. center pooling은 max summed response를 getting out 함으로써 달성할 수 있는데, max summed response는 predicting center keypoints를 위한 feature map에 대해 horizonatl 과 vertical 방향의 center keypoint를 통해 얻어지죠. 두 번째 strategy는 cascade corner pooling이라고 불리는 strategy죠. 이는 original corenr pooling module에 internal information을 perceiciving 하는 ability를 주는 것이죠. 이는 predicting corners를 위한 feature map에 대해 boundary와 internal directions에서 max summed response를 getting out함으로써 가능하죠. 실험적으로, 저자들은 tow-directional pooling method가 more stable 하다는 것을 증명했죠.
Related Work
Object detection은 object를 locating과 classifying하는 것을 포함하죠. deep learing 시대에, object detection approaches는 두 개의 main stream 이 있죠. two-stage와 one-stage 입니다.
Two-stage approaches
이는 object detection task를 두 개의 stage로 나눕니다. RoIs를 extract하고 RoIs를 regress하고 classify 하죠. R-CNN은 seletive search method를 사용하는 데, 이는 input images에서 RoI를 locate합니다. 그리고 DCN-based regoinwise clasifier를 사용하는 데 이는 RoIs를 각가 classify하죠. SPP-Net과 Fast-RCNN은 R-CNN을 향상시켰는데 RoIs를 feature map으로부터 extract하죠. Faster-RCNN은 end to end하게 trained 되도록 했는데 이는 RPN ( region proposal network)을 도입함으로써 가능해 진 것이고요. RPN은 RoIs를 generate 할 수 있는데 anchor box를 regress함으로써 이를 가능하게 하죠. 후에, anchor boxes는 object detection task에서 널리 사용됩니다. Mask-RCNN은 Faster-RCNN에 대해 mask prediction branch를 추가합니다. 이는 objects를 detect 하고 동시에 their masks를 predict 할 수 있게 해주죠. R-FCN은 fully connected layers를 position-sensitive score maps로 대체하는 데 이는 object를 더 잘 detecting하게 하죠. Cascade R-CNN은 training time에 overfitting problem과 inference taime에 quality mismatch를 IoU thresholds를 incereasing하여 detectors의 sequence를 training 함으로써 다루죠. keypoint-based object detection approaches는 ancor boxes와 bounding boxes regression을 사용하는 것의 disadvantages를 avoid하기 위해 제안되었죠. Other meaningful works는 object detection에서 different probelms에 대해 제안되었으며 예시로는 architectur desinge에 초점을 맞추기도 하고, contextual relationship에 초점을 맞추기도 하며, multi-scale unification에 초점을 맞추기도 했죠.
One-stage approaches
이는 RoI extraction process를 제거하죠. 그리고 candidate anchor boxes를 직접 classfiy 하고 regress합니다. YOLO는 fewer anchor boxes를 사용합니다. YOLOv2는 more anchor boxes와 new bounding box regression을 사용하여 performance를 향상시켰죠. SSD 는 input image에 걸쳐 anchor boxes를 densely하게 배치합니다. DSSD는 deconvolution module을 SSD에 도입하는데 이는 low level과 high-level features를 combine 해주죠. R-SSD는 pooling과 deconvolution operations를 different feature layers에 사용하고 이는 low-level과 high-level features를 combine 하죠. RON은 reverse connection과 objectness를 multiscale features 를 extract하기에 앞서 제안하죠. RefineDet은 locations과 anchor boxes의 size를 two times에 대해 refine하는데요. 이는 one-stage와 two-stage 모두에 사용되죠. CornerNet은 또 다른 keypoint-based approach입니다. 이는 object를 직접 detect하는데 conrenrs의 pair를 활용하죠. CornerNet이 high performance를 달성하긴 했지만, 개선의 여지가 남아있죠.
Approach
Baseline and Motivation
이 논문은 CornerNet을 baseline으로 사용하죠. corners를 detecting하기 위해, CornerNet은 두 개의 heatmaps를 생성합니다: top-left corners의 heatmap과 bottom-right corners의 heatmaps 죠. heatmaps는 different categories에 대한 keypoints의 location을 represent합니다. 그리고 각 keypoint에 대해 confidence score를 assign하죠. 게다가, embedding과 각 corner를 위한 offset group을 predicts하죠. embeddings는 two corners가 same object으로부터 나온것인지를 identify하는데 사용됩니다. offsets는 heatmaps으로부터의 corners를 imput image로 remap하는 것을 learn하는 데 사용되고요. object bounding boxes를 generating하기 위해, top-k left-top corners와 bottom-right corners가 scores에 따라 heatmaps로부터 선택되죠. 그런 다음, corners의 pair에 대한 embedding vectors의 distance가 paired corners가 같은 object에 속해 있는지를 결정하기 위해 계산되죠. object bounding box는 distance가 threshold보다 작다면 생성되는데, bounding box는 confidence score가 assigned되죠. 이는 corner pair의 average scores와 동일합니다.

Table 1에서 , 저자들은 CornerNet의 deeper analysis를 제공합니다. false discovery rate을 count 하고 incorrect bounding boxes의 proportion으로 정의했죠. quantitative results는 incorrect bounding boxes가 low IoU thresholds에서 큰 proprotion을 차지한다는 것을 보여줍니다. 하나의 가능성있는 이유는 CornerNet은 bounding boxes안의 regions를 look할 수 없기 때문입니다. CornerNet이 bounding boxes에서 visual patterns를 perceive하게 하기 위해, 하나의 potential solution은 CornerNet을 two-stage detector에 adapt하는 것이죠. 그러나 이는 computationally expensive합니다.
이 논문에서, 저자들은 highly efficient alternative 를 제안하는데 CenterNet이라 불리고 bounding box안에서 visual patterns를 explore합니다. object를 detecting하기 위해, triplet을 사용히죠. 그렇게 함으로써, one-stage detector를 고수합니다. 그러나, 부분적으로 RoI pooling의 functionality를 활용합니다. 저자들의 방법은 center information에만 집중하기 때문에, cost가 minimal하죠. 그럼과 동시에, 저자들은 objects 안에서 visual patterns를 keypoint detection process에 도입합니다. 이는 center pooling과 cascade corner pooling을 활용하고요.
Object Detection as Keypoint Triplets
overall network architecture는 Figure 2에서 볼 수 있습니다.

저자들은 각 object를 center keypoint와 corners의 pair로 represent합니다. 구체적으로, 저자들은 CornerNet의 basis에 center keypoints를 위한 heatmap을 embed하고 center keypoints의 offsets를 predict합니다. 그런다음, CornerNet에 proposed된 method를 사용하죠. 이는 top-k bounding boxes를 generate하는데 사용됩니다. 그러나, incorrect bounding boxes를 filter out하기 위해, 저자들은 detected center keypoints를 leverage하고 따라나오는 절차에 따라 resort합니다: (1) top-k center keypoints 를 their scores에 따라 select합니다. (2) input image에 center keypoints를 remap하는 corresponding offsets를 사용합니다. (3) 각 bounding box를 위한 central region을 define하고 central region이 center keypoints를 contains하는지를 check합니다. checked center keypoints의 class labels는 bounding box의 것과 같다는 것을 기억하시길 바랍니다. (4) center keypoint가 central region에서 detected되면, bounding box를 preserve 합니다. bounding box의 score는 three points의 average scores로 replaced됩니다. 3 points는 top-left corner, bottom-right corner 그리고 center keypoint를 가리키죠. its central region에 detected 된 center keypoints가 없다면, bounding box는 removed 됩니다.
bounding box에서 central region의 size는 detection results에 영향을 미치죠. 예를 들어, smaller central regions는 small bounding boxes를 위한 low recall rate을 야기합니다. 반면에 larger central regions는 large bounding boxes에 대한 low precision을 야기하죠. 그럼으로, 저자들은 scale-aware central region을 제안하는데 이는 bounding box의 size를 adaptively하게 fit하죠. scale-aware central region은 small bounding box에 대해 relatively large central region을 생성하고 large bounding box에 대해 relatively small central region을 생성하죠. bouning box i 가 preseved 되는 지를 결정해야한다고 가정해봅시다. tl_x와 tl_y는 i번째 top-left corner의 coordinates를 나타내고 br_x와 br_y는 i번째 bottom-right corner의 coordinates를 나타냅니다. central region j를 정의합니다. ctl_x와 ctl_y는 j의 top-left corner의 coordinates를 cbr_x와 cbr_y는 j의 bottom-right corner의 coordinates를 표기합니다. 그러면 위의 변수들은 아래의 관계를 만족하죠.

여기서 n은 odd인데 central region j의 scale을 결정합니다. 이 논문에서, n은 bounding boxes의 scales에 대해 3 과 5로 set하고 각각 150보다 less하고 greater합니다. Figure 3은 two central regions를 보여줍니다. 각각 n=3 과 n=5일 때를 나타내죠

Equation 1에 따르면, scale-aware central region을 결정할 수 있고, central region이 center keypoints를 포함하는지를 check할 수 있죠.
Enriching center and Corner Information
Center pooling
objects의 geometric centers는 recognizable visual patters를 convey 할 필요가 없죠. 예를 들면 human head는 strong visual patterns를 포함하지만, center keypoint는 human body의 중앙인 것처럼요. 이 문제를 다루기 위해, center pooling을 제안하는데, 이는 richer 하고 more recognizable visual patterns를 capture하죠. Figure 4(1)는 center pooling의 principle을 보여줍니다.
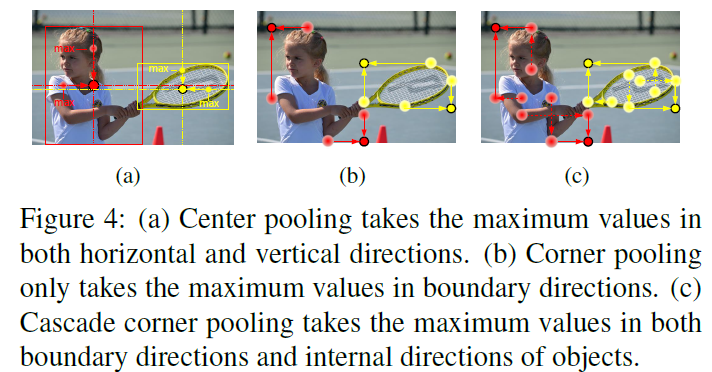
center pooling의 detailed process는 다음과 같습니다: backbone은 feature map을 출력합니다. 그리고 feature map에 pixel이 center keypoint인지를 결정하기 위해, horizaontal과 vertical 방향에서 maximum value를 찾고 그들을 더하죠. 그렇게 함으로써, center pooling은 center keypoints의 detection이 더 잘되는데 도움이 됩니다.
Cascade corner pooling
Corenrs는 objects의 outside죠. local apperance features가 lack 한 것은 당연합니다. CornerNet은 이 문제를 해결하기 위해 corner pooling을 사용합니다. corner pooling의 principle은 Figure 4(b)에서 볼 수 있죠. Corner pooling은 boundary directions에서 maximum values를 찾는 것을 목표로 합니다. corner를 determine하기 위함이죠. 그러나, 이 process는 corner가 edges에 sensitive하게 하죠. 이 문제를 다루기 위해, 저자들은 corner가 objcests의 visual patterns를 "see" 하게 하죠. cascade corner pooling의 principle은 Figure 4(c)에 나타나있죠. 먼저 boundary를 따라 boundary maximum value를 찾죠. 그런 다음 internal maximum value를 찾기 위해 boundary maximum value의 location 을 따라 탐색하죠. 그리고 최종적으로, two maximum values를 더하죠. 이렇게 함으로써, ccorners는 boundary information과 objects의 visual patterns 모두를 얻습니다.
center pooling과 cascade corner pooling 모두는 corner pooling 을 different directions에 combining함으로써 쉽게 achieved 될 수 있죠. Figure 5(a)는 center pooling module의 structrue를 보여줍니다.

direction에서 maximum value를 취하기 위해, left pooling과 right pooling을 일렬로 connect 할 필요가 있죠. Figure5 (b)는 cascade top corner pooling module의 structure를 보여줍니다. CornerNet의 top corner pooling과 비교하면 left corner pooling이 top corner pooling전에 추가되죠.
Training and Inference
Training
CenterNet은 pytorch로 구현됬고, scratch로부터 trained 됩니다. image의 resolution은 511 x 511 이고 128 x 128 heatmap을 생성합니다. data augmentation strategy를 사용했는데 이는 robust model을 train하기 위함이죠. training loss를 optimize하기 위해 Adam이 사용됩니다. training loss는 아래와 같고요

여기서 L^co_det와 L^ce_det는 focal losses를 나타내고 network가 corner와 center keypoints를 detect하는 데 사용됩니다. L^co_pull은 corners에 대한 pull loss이며, same object에 속한 embedding의 distance를 minimize하기 위해 사용됩니다. L^co_push는 corner에 대한 push loss이며, different object에 속한 embedding vectors를 maximize하는 데 사용됩니다. L^co_off 와 L^ce_off는 l1-loss이고 network가 corners와 center keypoints의 offset을 predict하는 데에 사용됩니다. alpha, beta, gamma는 corresponding losses를 위한 weights를 표기하고 0.1, 0.1, 1로 각각 set합니다. L_det, L_pull, L_push와 L_off는 CornerNet에 정의되어 있습니다. 8 Tesla V100 (32GB) GPUs에서 train했고 batch size로 48을 사용했습니다. iteration의 maximum number는 480k 입니다. learning rate는 2.5 x 10^-4 가 처음 250k 동안 사용되고 나머지 30k는 2.5 x 10-5이 사용됩니다.
Inference
singe-scale testing을 위해, original과 horizontally flipped images 를 넣습니다. 반면에, multi-scale testing에서, 저자들은 original과 horizontally flipped image를 넣는 데 0.6, 1, 1, 1.2, 1.5 , 1.8 의 resolutions를 가진 images들을 넣습니다. top 70개의 center keypoints, top 70 개의 top-left와 bottom-right를 bounding boxes를 detect하는 heatmaps로부터 선택합니다. 저자들은 fliped images로 부터 detected된 bounding boxes를 flip하고 original bounding boxes와 mix 합니다. 저자들은 최종적으로 top 100 bounding boxes를 score에 따라 선택하는데 이가 final detection results입니다.
여기까지 하겠습니다.
한 동안 안되는 하드웨어 맞게
net들을 하도 고쳐서 고생좀 했습니다만,
아직도 고생을 좀더 해야겠네요..
요구사항을 맞추려면요. 그럼 이만!



