이번 논문은 center net의 확장판 이라고보면 되겠습니다.
오랜만에 보는 tracking 논문이네요
tracking 필요하면 봐야죠.
생각할 게 많네요
시작할게요
Abstract
Tracking은 space와 time에 따라 following interest points의 기술이었죠. 이것은 deep networks가 rise로 인해 변했습니다. 요즘, tracking은 object detection에 temporal association으로 뒤이어 나오는 흔희 tracking-by-detection으로 알려진 pipelines로 dominated되죠. 저자들은 simultanesous detection 하고 tracking alrgorithm을 제안하는 데, 이는 SOTA 보다 simpler, faster, 그리고 more accurate 하죠. CenterTrack은 detection model에 applies하는데 prior frame으로 부터, images와 detections의 pair에 applies 하죠. minimal input 이 주어지면, CenterTrack은 objects를 localize하고 previous frame을 가지고 their associations를 predicts 합니다. 그게 답니다. Center Track은 간단하고 online 이며, real-time 입니다.
Introduction
초기 computer vision에서는, tracking은 space와 time에 따라 following interest points 로써 흔히 phrased 되었죠. Early trackers는 simple, fast, and resonably robust 했죠. 그러나 그들은 corners나 intensity peaks와 같은 strong low-level cues가 없는 상황에서는 실패하기 쉬웠죠. high-performing object detection models의 advent로 인해, powerful alternative가 부상합니다: tracking-by-detection ( 더 정확하게 말하면, tracking-after-detection ). 이 models은 object를 identify 하고 그런 다음 그들을 time에 따라 separate stage에서 linke 하는 주어진 accurate recognition에 의존하죠. Tracking-by-detection은 deep-learning-based object detectors의 power를 leverages합니다. 그리고 최근 dominant tracking paradigm이죠. 아직, the best-performing object trackers는 drawbacks 가 있지만요. 많은 것들은 detected boxes를 time에 따라 link하는 slow and complex association strategies에 달려 있습니다. 최근 simultaneous detection and tracking에 관한 많은 연구들은 이 complexity를 alleviating 하는 데 있어 progress 를 이뤄냈죠. 저자들은 point-based tracking 과 simultaneous detection 을 합치고 더 간단히 tracking하는 방법을 보여준다고 합니다.
저자들은 joint detection과 tracking을 위한 point-based framework 제안합니다. 이는 CenterTrack이라 불리죠. 각 object는 its bounding box의 center에 single point로 represented됩니다. 이 center point는 time에 따라 tracked 되죠. 이는 Figure 1에서 볼 수 있고요.
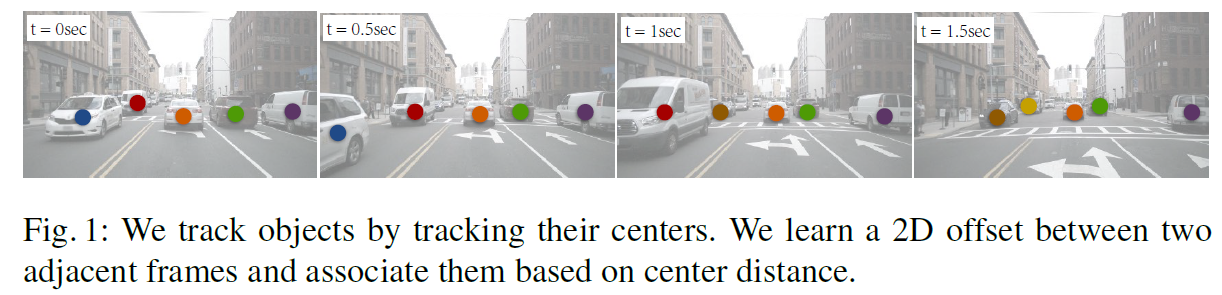
구체적으로, 저자들은 object centers를 localize하는 CenterNet detector 적용합니다. 저자들은 detector를 두 개의 연속된 frames와 prior tracklets의 heatmap에 대해 조절하는 데 이는 points 로 represented되죠. 저자들은 current object center로 부터 previous frame에서 its center 로 offset vector를 ouput하는 detector를 train합니다. 저자들은 this offset을 little additional computational cost로 center point의 attribute 로써 learn합니다. 이 predicted offset과 previous frame에서 detected center point 간의 distance에만 기반한 greedy matching은 object association을 위해 suffices하죠. tracker는 end-to-end trainable하고 differentiable합니다.
points로써 Tracking objects는 tracking pipeline의 two key components로 simplifies 합니다. 먼저, tracking-conditioned detection으로 simplifies 하는데요. 만약 past frames에서 각 object가 single point로 represented 된다면, objects의 constellation은 points의 heatmap에 의해 represented될 수 있죠. 저자들의 tracking-conditioned detector는 직접 이 heatmap을 ingests 하고 frame에 걸쳐 objects을 associating 할 때 all objects를 jointly 하게 reasons about하죠. 두 번째, point-based tracking은 time에 걸친 object association을 simlifies합니다. simple displacemnet prediction은 sparse optical flow와 유사한데, different frames에서 objects들이 linked되도록하죠. 이 displacement prediction은 prior detections에 대해 conditioned 됩니다. 이는 current frame에서 objects를 동시에 detect하는 것을 learn하고 objects를 prior detections에 associate 하죠.
overall idea는 simple 하지만, 이 일을 하는 데 있어 subtle details가 중요하죠. consecutive frames에서 Tracked objects는 매우 correlated 되죠. previous-frame heatmap이 input으로 주어지면, CenterTrack은 preceding frame으로부터 predictions를 repeat하는 것을 learn하죠. 그리고 large training error를 incurring 없이 track하는 것을 refuse하죠. 저자들은 이를 prevent하는데 training 동안 aggressive data-augmentation scheme을 통해 실현하죠. 사실, data augmentation은 static images로 부터 objects를 track하는 것을 learn하는 model을 위해서는 충분히 aggressive 하죠. 즉, CenterTrack은 static image datasets에 대해 성공적으로 trained 될 수 있죠. 즉 real video input이 필요하지 않죠
CenterTrack은 purely local인데요. centertrack은 adjacent frames에서 objects를 associates만을 하죠. lost한 long-range tracks를 reinitializing 하지 않습니다. local regime에서 simplicity, speed, 그리고 high accuracy를 위해 long-range tracks을 reconnect하는 ability를 trades합니다.
Related work
Tracking-by-detection
most modern trackers는 tracking-by-detection paradigm을 따릅니다. off-the-shelf object detector는 먼저 all objects를 각 individual frame에서 찾죠. Traking은 bounding box associaiton 문제이죠. SORT는 bounding boxes를 kalman filter를 이용해 tracks하고 each bounding box를 associates하는 데 bipartite matching을 사용해 current frame에서 highest overlapping detection을 가진 bounding box를 associate하죠. DeepSORT는 deep network로부터 appearance features를 가진 SORT 에서 overlap-based association cost 를 augments합니다. 더 최근의 연구는 object association의 robustness를 increasing하는 데에 초점을 맞추죠. Tang et al 의 연구는 person-reidentification features와 human pose features를 사용합니다. Xu et al 연구는 time에 걸쳐 spatial locations를 이용하죠. BeyondPixel은 vehicles를 track하는 데 additional 3D shape information을 사용합니다.
이 methods는 두 가지 drawbacks가 있습니다. 먼저, data association은 image appearance feature를 discards하죠. 두 번째, detection이 tracking으로 부터 separated 되어 있죠. 저자들의 approach는 association은 거의 free합니다. Association은 detection과 함께 learned되죠. 또한 centertrack은 previous tracking results를 input으로 취하고 이는 missing이나 additional cue로 부터 occluded objects를 recover하는 것을 learn할 수 있죠.
Joint detection and tracking
multi-object tracking에서 현재 trend는 existing detectors에서 trackers로 convert 하는 겁니다. 그리고 이 tasks들을 same framework에서 combine하는 것이죠. Feichtenhofer et al은 current와 past frames input으로 siamese network 사용합니다. 그리고 bounding boxes 간의 inter-frame offsets를 예측하죠. Integrated detection은 tracked bounding boxes를 detection을 enhance하는 additional region proposals로써 사용하죠. bipartite-matching-based bounding-box association을 따르고요. Tracktor는 box association을 bounding box regression을 사용해 region proposals의 identities을 직접 propagating함으로써 remove합니다. video object detection에서, Kang et al 연구는 stacked consecutive frames를 network의 input으로 받아드립니다. 그리고 whole video segment 동안 detection을 하죠. And Zhu et al 연구는 inference를 accelerate하는 previous frames로부터 intermediate features를 warp하는 flow를 사용합니다.
CenterTrack이 이 category에 속하죠. 차이는 all of tese works 가 FasterRCNN framework에 adopt ㄷ한다는 겁니다. 여기서 tracked boxes는 region proposal로써 사용되죠. 이것은 bounding boxes는 frames간에 large overlap을 가정합니다. low-framerate regimes에서는 사실이 아닌 가정이죠. centertrack은 tracked predictions를 additional point-based heatmap input으로 network에 제공하죠. 이 network은 box가 더 이상 overlap되지 않더라도 its receptive field 어디서든 object을 reason about할 수 있고 match할 수 있습니다.
Motion prediction
Motion prediction은 tracking system에서 또 다른 important component 인데요. Early approaches는 object velocities 를 model하는 kalman filters를 사용합니다. Held et al은 single-object tracking에 대해 frames 간의 bounding box offset를 위하 4 개의 scalars를 predict하는 regression network 사용합니다. Xiao et al 연구는 optical flow estimation network를 사용하는데 이는 human pose tracking 에서 joint locations를 update하죠. Voigtlaender et al 연구는 object identities를 위해 high-dimensional embedding vetor를 learn하는데 이는 simultaneous object tracking과 segmentation을 위해서죠. 저자들의 center offset은 sparse optical flow와 analogous합니다. 그러나, detection network와 함께 learned 되고 dense supervision을 require하지 않습니다.
Heatmap-conditioned keypoint estimation
model predictions를 additional input으로 model에 입력으로 주는 것은 광범위한 vision tasks에서 사용되죠. 특히 keypoint estimation은 더 그렇고요. Auto-context는 mask prediction을 network에 다시 넣어줍니다. Iterative-Error-Feedback( IEF ) another step을 취하는데, predicted keypoint coordinates를 heatmaps로 rending하는 step이 있고요. PoseFix는 human pose refinement를 위한 test error를 simulate하는 heatmaps를 generates합니다.
저자들의 tracking-conditioned detection framwork은 이들 연구에 영감을 받았죠. prior keypoints의 rendered heatmap 은 두 가지 reason 때문에 tracking에 있어 특히 매력적이죠. 먼저, previous frame에서 information은 freely available합니다. 그리고 detector를 slow down하지 않죠. 두 번째, conditional tracking은 current frame에서 더 이상 볼 수 없는 occluded objects를 reason about 할 수 있습니다. tracker는 prior frame around로 부터 이런 detections를 keep하는 것을 simply하게 learn 할 수 있죠.
3D object detection and tracking
3D trackers는 monocular images나 3D point clouds로부터 3D detection을 가진 standard traking systems에서 object detection component를 replace 합니다. Tracking은 그런 다음 off-the-shelf identity association model을 사용하죠. 예를 들면, 3DT 는 2D bounding boxes를 detects하고, 3D motion을 estimate한 다음 depth와 matching을 위한 order cues를 사용하죠. AB3D는 SOTA performance를 달성했는데, Kalman filter 에 accurate 3D detections를 combining했죠.
Preliminaries
CenterTrack은 CenterNet detector를 기반으로 합니다. CenterNet은 single image I ( R^W x H x 3 )를 input으로 취하죠. 그리고 각 class c ( { 0, ... , C-1 } )를 위한 detection의 set( { (p_i, s_i) }^N-1_i=0 ) 을 produce합니다. CenterNet은 각 object를 its center point p ( R^2 )를 통해 identifies 합니다. 그리고 나서 object's bounding box의 height와 width s ( R^2 )로 regress합니다. 구체적으로, centernet은 downsampling factor R=4를 가진 low-resolution heatmap hat Y ( [ 0, 1 ] ^ W/R x H/R x C )와 size map hat S ( R ^ W/R x H/R x 2 )를 produce합니다. heatmap hat Y에서 각 local maximum hat P ( R^2 ) ( peak는 로 불리며, peak's response는 3 x 3 neighborhood 에서 strongest 하죠 )는 confidence hat w = hat Y_hat p와 object size hat s = hat S_hat p 를 가진 detected object의 center에 해당하죠.
annotated objects의 set를 가진 image가 주어지면, CenterNet은 focal loss에 기반한 training objective를 사용합니다 식은 아래와 같죠
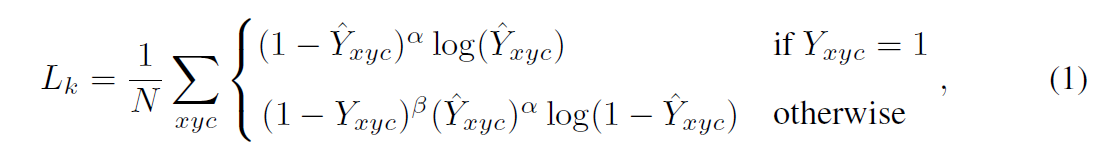
여기서 Y ( [ 0, 1 ] ^ W/R x H/R x C ) 는 ground-truth heatmap 인데 이는 annotated objects에 해당하죠. N은 objects의 number이고 alph = 2, beta = 4로 focal loss의 hyperparameters입니다. class c의 center p에 대해 , 저자들은 Gaussian-shaped peak를 Y_:, :, c 로 render하는데 rendering function Y = R ( { p0, p1, ... }) 을 사용하죠. 식으로 표현하면, position q에서 rending function은 아래와 같이 정의되죠
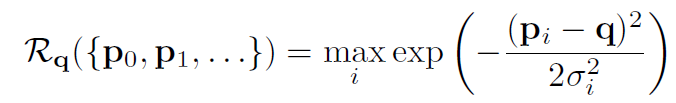
Gaussian kernel alph_i는 object size의 function입니다.
size prediction은 center locations에서 supervised됩니다. s_i를 location p_i에서 i-th object의 bounding box size 라고 하면, Size prediction은 regression에 의해 learned 됩니다.

CenterNet 은 anlogous L1 loss L_loc를 사용해 refined center local location으로 regress합니다. CenterNet의 overall loss는 all three loss term의 weighted sum입니다: focal loss, size and location regression.
Tracking objects as points
저자들은 tracking을 local perspective로부터 approach합니다. object가 frame에 leaves 하거나 occluded 나 reappears 할 때, new identity 가 assigned 됩니다. 저자들은 따라서 tracking을 consecutive frames에 걸쳐 detection identities를 propagating의 problem으로 다루죠. 즉, temporal gaps에 따라 associations를 re=establishing하는 과정이 없죠.
time t에서, current frame I^(t) ( R^W x H x 3 )의 image가 주어지고 previous frame I^(t-1) ( R^ W x H x 3 )와 previous frame에서 tracked objects T ^(t-1) = { b^(t-1)_0, b^(t-1)_1, ...}_i 가 주어집니다. 각 object b = ( p, s, w, id ) 는 its center location p (R^2), size s (R^2), detection confidence w ( [ 0, 1 ] ) 그리고 unique identity id ( I ) 로 표현되죠. 목표는 objects T^(t) = { b^(t)_0, b^(t)_1, ... }를 current frame t 에서 detect하고 track하는 겁니다. 그리고 both frames에서 consistent id로 appear하는 objects를 assign하는 것이죠.
여기에는 두 개의 main callenges가 있습니다. 먼저 every frame에서 all objects를 finding 하는 것인데 이는 occluded 된 object를 포함하죠. 두 번째 callenge는 these object를 time에 따라 associating 하는 것이죠. 저자들은 이 두문제를 single deep network를 통해 다루며, 이는 end-to-end로 trained 되죠. Section 4.1에서는 tracking-conditioned detector에 대해 설명하는데 이는 tracked detection을 previous frame으로 부터 leverages하죠. previous frame은 current frame에서 detection을 improve합니다. section4.2에서 simple offset prediction scheme을 present합니다. 이는 time에 따라 detecions를 link할 수 있죠. 마지막으로, sections 4.3과 4.4dptjsms 이 detector가 video나 static image data로부터 train 하는 방법을 보여줍니다.
Tracking-conditioned detection
object detector로써, CenterNet은 이미 tracking을 위한 거의 모든 required information 을 infer합니다: object locations hat p, thier size hat s, = hat S_hat p 그리고 confidence measure hat w = hat Y_hat p. 그러나, current frame에서 직접 볼 수 없는 objects를 find 할 수 없고, detected objects는 temporally coherent 하지 않죠. temporal coherence를 increase하는 하나의 natural way는 past frames로부터 additional images input을 가진 detector를 provide하는 겁니다. CenterTrack에서는, two frames를 input으로 가진 detection network를 제공합니다: current frame I^(t) 와 prior frame I ^(t-1) 이죠. 이는 network가 문맥상 change를 estimate하도록 합니다. 그리고 visual evidence 로부터 time t-1에서 potentially하게 occluded objects를 time t에서 recover하게 하죠.
CenterTrack은 prioir detections { p^(t-1)_0, p^(t-1)_1, ... } 을 additional input으로 취합니다. network에 easily하게 provided 되는 form에서 이 detections가 어떻게 represented 될까요? 저자들의 tracklets의 point-based nature은 helpful 합니다. each detected object는 single point로 represented 되기 떄문에, 저자들은 conveniently하게 all detections를 class-agnostic single-channel heatmap H^(t-1) = R ( {p^(t-1)_0, p^(t-1)_1, ...} )에서 render할 수 있죠. false positive detections의 propagation을 reduce하기 위해, 저자들은 threshold tau 보다 큰 confidence score를 가진 objects만을 render하죠. CenterTrack의 architecture는 CenterNet과 같습니다. Figure 2에서 볼 수 있듯이 4 개의 additional input channels를 가지고 있죠.

Tracking-conditioned detection은 detected objects의 temporally coherent set을 provides 합니다. 그러나, 이는 these detections를 time에 걸쳐 link하지 않죠. 다음 section에서 point-based detection에 space와 time에 걸쳐 objects track하는 additional output을 add하는 방법을 보여준다고 하네요.
Association through offsets
detections를 time에 따라 associate하기 위해, CenterTrack은 2D displacement를 두 개의 additional output channels로 predicts합니다. ( hat D ( R^ W/R x H/R/ 2 ). location hat p^(t)에서 각 detected object를 위해, displacement hat d^(t) = hat D^(t)_hat p^(t) 는 current frame hat p^(t)와 previous frame hat p^(t-1) 에서 object의 location에서 difference를 captures하죠: hat d^(t) = hat p^(t) - hat p^(t-1) . 저자들은 이 displacement를 size 나 location refinement와 같은 regression objective를 사용하여 learn합니다.

p^(t-1)_i 와 p^(t)_i는 ground-truth objects를 tracked 합니다. Figure 2에서 offset prediction의 example을 보여줍니다.
sufficiently good offset prediction을 가지고, simple greedy matching algorithm은 objects를 time에 걸쳐 associate할 수 있죠. position hat p에서 각 detection을 위해, 저자들은 이것을 hat p - hat D_hat p position에서 closest unmatched prior detection과 greedily하게 associate합니다. 만일 radius kappa 안에서 unmatched prior detection이 없다면, new tracklet을 spwan하죠. kappa를 각 tracklet을 위한 predicted bounding box의 width와 height의 geometric mean으로 정의합니다. greedy matching algorithm의 precise description은 supplementary material에 있다고 하네요. 이 greedy matching algorithm의 simplicity는 points로써 object를 tracking하는 이점을 다시한번 highlights합니다. simple displacement prediction은 objects를 time에 따라 link하기에 sufficient합니다. complicated distance metric 이나 graph matching이 필요하지 않죠.
Training on Video data
CenterTrack은 object detector이고 object detector와 같이 trained되죠. CenterNet 에서 CenterTrack으로 architectural changed는 minor합니다: four additional input channels와 two output channels 가 변했죠. 이것은 CenterTrack을 pretrained CenterNet detector로부터 fine-tune할 수 있게 해주죠. current detection pipeline과 관련된 모든 weights를 copy합니다. additional inputs나 outputs에 관한 all weights는 randomly하게 initialized됩니다. CenterNet training protocol을 따르고 all predictions를 multi-task learning으로써 train합니다. offset regression L_off의 addition을 가지고 same training objective를 사용합니다.
CenterTrack을 training하는데 있어서 main challenge는 realistic tracklet heatmap H^(t-1)을 producing하는서 발생하는데요. inference time에, 이 tracklet heatmap은 missing tracklets, wrongly localized objects, or even false positive에 대한 임의의 개수를 포함하죠. 이런 errors는 training 동안 provided되는 ground-truth tracklets 에는 present되지 않습니다. 저자들은 대신에 training 동안 이 test-time error를 simulate합니다. 구체적으로, 저자들은 세 종류의 error를 simulate합니다. 먼저, prior frame으로 부터 각 center에 Gaussian noise를 adding함으로써 each tracklet p^(t-1)을 locally하게 jitter합니다. 즉, 저자들은 p'_i = ( x_i + r x lambda_jt x w_i, y_i + r x lambda_jt x h_i ) 를 만들죠. 여기서 r은 Gaussian distribution으로부터 sampled됩니다. lambda_jt = 0,05를 사용합니다. 둘째로, 저자들은 false positives를 ground-truth object locations 근처에 add합니다. 이는 probability lambda_fn을 가진 spurious noisy peak p'_i 을 rendering함으로써 실현하고요. 세번 째, 저자들은 false negatives를 probaility lambda_fn dot lambda_fp을 활용해 detections를 randomly하게 removing함으로써 simulate합니다. 그리고 lambda_fn은 baseline model의 statistics에 따라 set합니다. 이 three augmentations는 robust tracking-conditioned object detector를 train하는데 sufficient합니다.
실험적에서, I^(t-1) 는 time t-1로부터 immediately preceding frame이 될 필요는 없습니다. same video sequence에서 different frame이 될 수 있죠. 실험에서, 저자들은 randomly하게 frames를 sample 하죠. t 근처에서 말이죠. 이는 framerate에 overfitting을 피하기 위해서이고요. 구체적으로 all frame k로부터 sample하는데 | k-t | < M_f 이고 M_f=3 이며 hyperparameter입니다.
Training on static image data ( 매우 흥미로운 부분이네요 )
labeled video data 없이 CenterTrack은 prior frame I^(t-1) 이나 tracked detections { p^(t-1)_0, p^(t-1)_1, ... } 에 acceess 하지 못합니다. 그러나 저자들은 standard detection benchmarks에 대해 tracking을 simulate 할 수 있습니다. single images I^(t) 와 detections {p^(t)_0, p^(t)_1, ... } 만이 주어졌을 때 말이죠. idea는 simple합니다. previdous frame을 current frame을 randomly scaling하고 translating함으로써 simulate하죠. 이는 상당히 효과적이었다고 하네요.
End-to-end 3D object tracking
monocular 3D tracking을 perform하기 위해, 저자들은 CenterNet의 monocular 3D detection form을 adopt합니다. 구체적으로, 저자들은 object depth, rotation, and 3D extext를 predict하는 output head를 train합니다. 3D bounding box의 center의 projection이 object's 2D bounding box의 center를 활용해 align되지 않기 때문에, 2D-to-3D center offset을 predict합니다.
이 글은 여기까지 할게요.
실험은 언제나 그랬듯 생략합니다.



