action recognition이 high task이다 보니
여러 방면에서 접근이 많네요.
GCN 계열을 많이 봤었는데,
차이점들을 명확하게 할 필요가 있겠네요
각 장,단점도 알아야겠고요
이번에는 GCN 기반이 아닌
논문을 볼게요
Abstract
existing action tubelet detectors는 heuristic anchor design 과 placement에 의존하죠. 이는 computationally expensive 하고 precise localization에 대해 sub-optimal 하죠. 이 논문에서는, 저자들은 conceptually simple 하고 computationally efficient 하며 더 precise action tubelet detection framwork인 MOC-detector를 제안한다고 합니다. MovingCenter Detector의 줄임말입니다. movement information은 action tubelet detection을 simplify 할 수 있고 assist 할 수 있죠. MOC-detector는 3가지 crucial head branch로 구성되어 있습니다. (1) instance center detection과 action recognition를 위한 Center Branch, (2) Moving points의 trajectories를 form하는 adjacent에서 movement estimation을 위한 Movement Branch, (3) 각 estimated center에서 bounding box size를 직접 regressing함으로써 spatial extent detection을 위한 Box Branch. 이 3개의 branches는 tubelet detection results를 generate 하기 위해 함께 동작하죠. 이는 matching strategy를 활용해 video-level tubes를 생성하기위해 linked 될 수 있죠. 저자들의 MOC-detector는 SOTA 성능을 달성했죠.
Introduction
Spatio-temporal action detection은 video understanding에서 중요한 문제죠. 이는 video에 존재하는 all action instances를 recognize하는 것을 목표로 하죠. 그리고 space와 time에 대해 그들을 localize하는 것을 역시 목표로 하죠. 많은 scenarios에서 광범위한 applications를 가지고 있죠. 가령, video surveillance, video captioning, 그리고 event detection 과 같은 분야가 있죠. 기존의 approaches는 action detector를 각 frame에 독립적으로 적용하고 그런 뒤에, detection results를 frame-wise로 liking하거나 time에 따라 하나의 detection result를 tracking함으로써 action tube를 생성했죠. 이 방법들은 frame-level detection을 수행할때 temporal information을 well capture하는데 실패했는데요. 때문에 현실에서 action tubes를 detecting 하는데 덜 effective하죠. 이 문제를 다루기 위해, 몇몇 approaches는 clip-level에서 action detection을 perform하죠. 이 때 short-term temporal information을 사용하고요. 이런 관점에서는, 이 방법들은 frames의 sequence를 input으로 넣고 detected tubelets를 directly output하죠. 이 tubelet detection scheme 은 video-based action detection에 대해 더 principled하고 effetive한 solution을 만들어냈죠. 그리고 standard benchmarks에 대해 promising results를 보여줬고요.
existing tubelet detection methods는 Faster R-CNN 이나 SSD 와 같이 pre-defined anchor boxes의 huge number를 operate 하는 mainstream object detectores와 매우 연관되어 있는데요. 이들은 hyper-arameters에 민감하다거나 densely placed bounding boxes 때문에 덜 효과적이다라는 것 같은 critical issues로 부터 여전히 고통받고 있죠. 이런 문제들은 videos에 anchor-based detection framework을 적용할 때 더 심각해지는데요. 먼저, clip druation이 길어질 때 possible tubelet anchors의 수가 dramtically 하기 증가하죠. 이는 training과 inference에 great challenge를 impose하고요. 둘 째, temporal dimension을 따라 variation을 consider하는 더 sophisticated ancor box placement와 adjustment를 devise할 것을 요구한다는 것이죠. 게다가, 이 anchor-based methods는 space와 time에 걸쳐 cuboid로써 각 action instance를 미리 정의하는 2D anchors를 temporal dimension을 따라 직접 extend 하죠. 이 assumption은 temporal coherence와 adjacent frame-level bounding boxes의 correlation을 well capture하는 flexibility 가 lack합니다.
anchor-free object detectrion의 발전에 영감을 받아, 저자들은 개념적으로 간단하고, 계산적으로 효율적이며 더 정확한, action tubelet detector를 제안하는데요. MovingCenter detector로 MOC-detector이죠. Fig 1. 에서 보여지듯이, MOC-detector는 new tubelet detection scheme을 제안한다고 하네요. 이는 각 instance를 moving points의 trajectory로 다루기 때문에 새로운 것이고요

이 관점에서, action tubelet은 key frame에 있는 center point와 center에 대해 다른 frames의 offsets에 의해 represented되죠. tubelete shape을 결정하기 위해, 저자들은 각 frame에서 moving point trajectory에 따라 bounding box size를 직접적으로 regress하죠. MOC-detector는 fully convolutional onestage tubelete scheme을 생성하죠. 이는 more efficient training과 inference 을 가능하게 할 뿐아니라, more precise detection results를 produce하죠.
구체적으로, MOC-detector는 tubelet detecion의 task를 3 개의 sub-task로 decouple합니다. center detection, offset estimation 그리고 box regression. 먼저, frames를 2D efficient backbone network에 feature extraction을 위해 입력으로 넣습니다. 그러고 난뒤 3 개의 separate branches를 devise하죠. (1) Center Branch: action instance center와 category를 detecting합니다. (2) Movement Branch: its center에 관해 현재 frame의 offsets를 estimating합니다. (3) BoxBranch: 각 frame의 detected center point에서 bounding box size를 predicting합니다. 이 unique design은 3 개의 branch가 tubelet detection results를 generate하기 위해 서로 협력하도록 하는 것을 가능하게 합니다. 마지막으로, 저자들은 이 detected action tubelets를 long-range detection fesults를 생성하기 위해 frames에 걸쳐 detected action tubeletes를 link하죠.
Related Work
Object Detection
Ancor-based Object Detectors
전통적으로 one-stage와 two-stage object detectors는 predifined anchor boxes에 상당히 의존적이죠. Two-stage object detector는 Faster-RCNN 과 Cascade-RCNN 같은 것들이 있고 첫 번째 stage에서 anchors의 set으로부터 RoI를 생성하는 RPN이 devised되어있고 두번째 stage에서 각 RoI의 regression과 classification을 handeled하도록 되어 있죠. 반면, one-stage detectors는 class-aware acnhors를 사용하고 동시에 categories와 objects의 realtive spatial offsets를 예측하죠. SSD, YOLO, RetinaNet이 대표적 예시고요
Anchor-free Object Detectors
몇몇 연구는 anchor-free methods의 performance가 anchor-based detectors에 경쟁력이 있을 수 있고 그런 detectors는 computation-intensive anchors와 region-based CNN을 제거할 수 있다는 것을 보여주죠. CornerNet은 pair of corners로 bounding box를 detected 하고 final detection을 form하기 위해 그들을 group하죠. CenterNet은 bounding box의 center point로써 object를 model 하고 final result를 build하기 위해 width와 height를 regressed하죠.
Spatio-temporal Action Detection
Frame-level Detector
image object detector를 frame-level action detector로써 action detection의 task로 extend 하고자하는 수 많은 노력이 있었죠. frame detection을 getting한 후에, linking algorithm이 final tube를 생성하기 위해 applied 되었죠. Weinzaepfel는 tracking-by-detection method 를 사용했습니다. 비록 flow가 motion information을 capture하는데 사용되지만, frame-level detection은 video's temporal information을 fully utilize하는데 실패했죠.
Clip-level Detector
detection을 위한 temporal information을 model하기 위해, clip-level approaches 나 action tubelet detectors 가 제안되었죠. ACT는 frames의 short sequence를 받아 tubelets를 output하죠. 이는 anchor cuboids로부터 regressed 되고요. STEP 는 large displacement problem을 해결하는 few steps에 걸친 proposals를 refine하는 progressive한 method를 제안했습니다. 몇몇 methods는 tubes proposal 을 generate하는 frames나 tubelet proposals을 linked하고 classification을 수행했죠.
이 approaches는 anchor-based object detectors에 기반합니다. 이는 achor design과 computationally cost에 sensitive하죠. 대신에 저자들은 anchor-free action tubelet dector를 design하죠. 각 action instance를 moving point의 trajectory 다룸으로써 말이죠.
Approach
Overview
Action tubelet detection은 input clip으로부터 bounding boxes의 short sequence를 localizing 하고 its action category를 recognizing는 것을 목표로 하죠. 저자들은 새로운 tubelet detector를 제안하는데 MOC-detector이죠. action instance를 moving points의 trajectory로써 viewing하죠. Fig2에서 볼수 있듯이, MOC-detector에서는 consecutive frames의 set을 input으로 받아들이고 각각 frame level features를 extract하는 efficient 2D backbone 에 던져넣어지죠.

그런다음, 3개의 head branches를 design 하는데 이는 anchor-free 방법으로 tubelet detection을 perform하고요. first branch는 Center Branch인데 center(key) frame에 대해 정의됩니다. 이 Center branch는 tubelet center를 localize하고 its action category를 recognize하죠. secon branch는 Movement branch로 all frames에 대해 정의됩니다. Movement branch는 temporal dimension을 따라 center movement를 예측하는 adjacent frames과 relate하죠. estimated movement는 key frame에서 other frames에 이르기까지 trajectory를 generate하는 center point를 propagate. Third branch는 box branch인데, all frames의 detected center points에 대해 operate합니다. 이 branch는 각 frame에서 detected action instance의 spatial extend를 determing하는데 초점을 맞추죠. 이는 bounding box의 height와 width를 직접 regressing함으로써 수행되고요. 이 3개의 branches는 short clip으로부터 tubelet detection을 생성하기 위해 함께 collaborate하죠. 이는 common linking strategy를 따라 long untrimmed video에서 action tube detection을 form 하기 위해 linked 되죠. backbone의 short description을 먼저 보여주고 three branches의 technical details를 제공한다고 하네요. 그리고 마지막으로 linking algorithm에 대해서 말한다고 합니다.
Backbone
MOC-detector에서 K frames를 input으로 주고, 각 frame은 W x H 의 resolution이죠. 처음 K frames는 2D backbone에 nput으로 던져지고 feature volume f ( R ^ K x W/R x W/R x B )를 생성하죠. R은 spatial downsample ratio고 B는 channel number를 표기합니다. information에서 full temporal 을 keep하기 위해, 저자들은 temporal dimension에 대해 어떤 downsampling도 perform하지 않죠. 구제척으로 DLA-34를 선택했습니다. 이 architecture는 각 frame에 대해 feature를 extract하는 encoder-decoder architecture를 사용하죠. spatial downsampling ratio R 은 4이고, channel number B는 64dlqslek. extracted features는 3 head branches에서 공유되죠.
Center Branch : Detect Center at Key Frame
Center branch는 key frame에서 action instance center를 datecting하고 its category를 extracted video features에 기반해 recognizing하는 것을 목적으로하죠. Temporal information은 action recognition에서 중요하고 그에 따라 action centor를 estimate하고 its class를 recognizing하는 temporal module을 설계했죠. 이는 multi-frame feature maps를 channel dimension을 따라 concatenating함으로써 구현했고요. 구체적으로, video feature representation f ( R^W/R x H/R x (KxB) ) 에 기반하여, center heatmap hat L ( [0 ,1]^W/R x H/R x C )를 key frame에 대해 estimate하는데요. C는 action classes의 number 입니다. hat L_x,y,c 의 value는 location (x,y)에서 class c의 action instance를 detecting의 likelihood를 represents합니다. 그리고 higher value는 stronger possibility를 indicate하죠. 구체적으로, standard convolution operation을 center heatmap을 estimate하는데 사용합니다.
Training
common dense prediction setting을 따라 Center branch를 학습합니다. i_th action instance에 대해, its center를 key frame's bounding box center로써 represent하고 action category에 대해 center's position을 ground truth label (x_ci, y_ci) 으로 사용합니다. ground truth heatmap L ( [0,1]^W/RxH/RxC )를 생성하는데 Gaussian kernel을 사용하고 이 kernel은 soft heatmap groundtruth 를 생성하죠. 식은 아래와 같습니다.

other class( c != c_i )에 대해, heatmap L_x,y,c = 0 으로 set합니다. sigma_p는 instance size에 adaptive하죠. 그리고 same category 의 두 개의 Gaussian이 overlap할 때 maximum을 선택합니다. training objective는 focal loss의 variant이고 아래와 같죠.
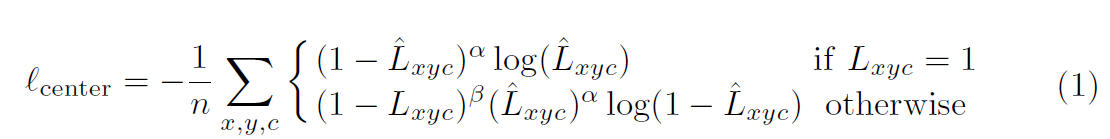
n은 ground truth instances의 number이고 alpha와 beta는 focal loss의 hyperparameters입니다. alpha = 2, beta = 4로 set했죠. focal loss는 imbalanced training issue를 effectively하게 다룰 수 있죠.
Inference
training 후에, Center Branch는 action instance center를 localizing 하고 its category를 recognizing 하기위한 tubelet dectection 에서 deployed 될 수 있죠. 구체적으로 all local peak를 detect하는데 각 class에 대해 estimated heatmap hat L에서 8-connected neighbors보다 greater 하거나 equal 한 peak죠. 그리고 난 다음, top N peak를 tubelet scores와 함께 candidate centers로 all categories로 부터 keep 하죠.
Movement Branch: Move Center Temporally
Movement branch는 adjacent frames를 action instance centoer의 movement를 temporal dimension을 따라 predict 하고자 하죠. CenterBranch와 유사하게, Movement Branch는 key frames와 관련된 current frame의 center offsets를 regress하는 temporal information을 사용합니다. 구체적으로, Movement Branch 는 input으로써 stacked feature representation을 받아들이고, movement prediction map을 output으로 내놓는데요. ( hat M, R^W/R x H/R x ( K x 2 ) ) 2K channels는 key frames로부터 current frames까지 X와 Y directions에서 center movement를 represent하죠. key frame center ( hat x _key, hat y_key ) 가 주어지면 hat M_hat x_key,hat y_key,2j:2j+2 는 j^th frame의 center movement를 encodes합니다.
Training
i^th action instance의 ground truth tubelet은 [( x^1_tl, y^1_tl, x^1_br, y^1_br), ... , (x^K_tl, y^K_tl, x^K_br, y^K_br)] 인데요. subscript tl과 br은 bounding boxes의 top-left와 bottom-right points를 represent합니다. k를 key frame index라고 하면, key frame에서 i^th action instance는 아래와 같이 정의됩니다.
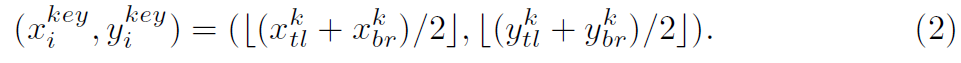
j^th frame에서 i^th instance의 bounding box center ( x^j_i, y^j_i )는 아래와 같이 계산합니다.
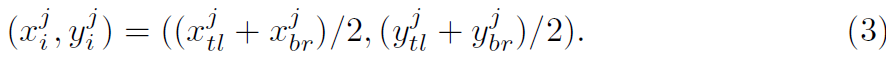
그러고 나면, i^th action instance의 ground truth movement 다음과 같이 계산되죠.
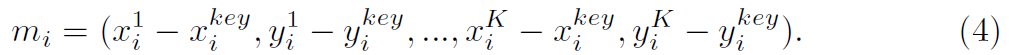
Movement Branch의 training을 위해, key frame center location에서 movement Map hat M을 optimize하고 l_1 loss를 사용하는데 식으로 표현하면 아래와 같죠.
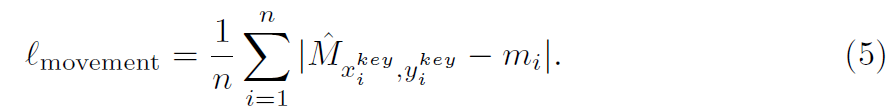
Inference
Movement Branch training 후에, N 개의 detected action centers 가 Center Brach로 부터 주어지면, Movement vector를 all detected action instance에 대해 얻어집니다. Movement Branch와 Center Branch의 결과에 기반해, trajectory set T를 생성할 수 있고, detected action center에 대해, moving points의 trajectory는 아래와 같이 계산됩니다.
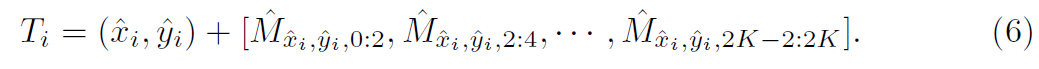
Box Branch: Determine Spatial Extent
Box Branch는 tubele detection의 last step인데요. action instance의 spatial extent 를 determining 하는데 초점을 맞추죠. Center Branch와 Movement Branch와 다르게, box detection은 current frame에만 의존하죠. temporal information은 class-agnostix bounding box generation에 benefit이 없죠. 이런 관점에서, 이 branch는 frame-wise manner로 수행될 수 있는데요. 구체적으로, Box Branch는 single frames's frame f^j ( W/R x H/R x B )가 input으로 들어가고, j^th frame에 대해 bounding box size를 직접 estimate하는 size prediction map hat S^j ( W/R x H/R x 2 )을 생성합니다.
Training
j^th frame에서 i^th action instance의 ground truth bbox는 아래와 같이 represented 되는 데요.
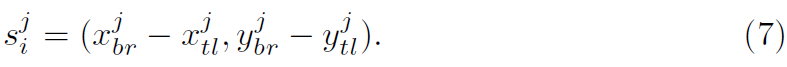
이 ground truth bounding box size를 활용해, l_1 Loss를 가지고 각 tubelet에 대해 all frames의 center points에서 Box Branch를 optimize합니다. 식은 아래와 같고요
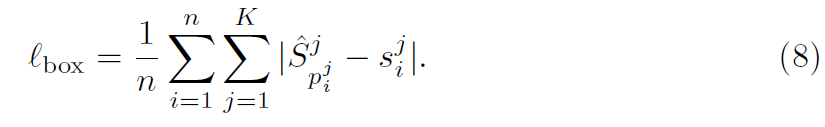
p^j_i 는 j^th frame에서 i^th instance ground truth center입니다. MOC-detector의 overall training objective는 아래와 같죠
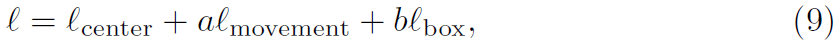
여기서 a = 1, b = 0.1로 set합니다. 자세한 내용은 부록에서 제시한다네요
Inference
tubelet detection results를 생성할 준비가 끝났습니다. Movement Branch로부터 trajectories T과 이 branch에 의해 생성된 각 location에 대한 size prediction heatmap hat S에 기반해서 말이죠. trajectory T_i에서 j^th point에 대해, (T_x, T_y)는 its coordinates를 표기하고 (w,h)는 specific location에서 Box Branch size ouput hat S를 표기하죠. 그러면 bounding box는 아래와 같이 계산됩니다.
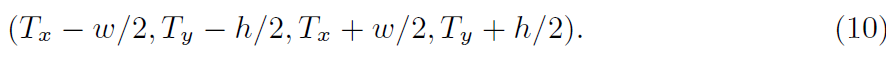
Tubelet Linking
clip-level detection results를 getting한 후에, tubeletes를 time에 따라 final tubes로 link하는 데요. main goal은 new tubelet detector를 propose하는 겁니다. video가 주어지면, MOC 는 tubelets를 extracts하고 top 10을 time에 걸쳐 stride 1을 가진 K frames의 각 sequence에 대해 candidates로써 top 10을 keep합니다. 이는 tubelet manner에 의해 tubelet에서 final tubes로 linked 되죠.
Initialization
첫 frame에서, 모든 candidate는 new link로 starts합니다. 주어진 frame에서, descending ordr of links' score로 이 frame에서 starting하는 tubelet candidates의 하나를 가지고 existing links를 extend합니다. link의 score는 이 link에서 tubelets의 average score입니다. 하나의 candidate는 one existing link에만 assigned 될 수 있습니다. 3개의 conditions를 만족할 때 말이죠. (1) candidate는 other link에 의해 selected 되지 않습니다. (2) link와 candidata 간의 overlap은 threshold T 보다 훨씬 큽니다. (3) candidate t는 highest score입니다.
Termination
existing link는 stop하는데, consecutiv K frames에서 extend되지 않을 때 stop되죠. 각 link에 대해 action tube는 build됩니다. score는 link에서 tubelets의 average score입니다. link에서 각 frame에 대해, 저자들은 frame을 containing하는 tubelets의 bbox coordinates를 average합니다. Initialization과 termination은 tubes' temporal extents를 determine하죠. low confidence를 가진 Tubes와 short duration은 abandoned되죠. linking algorithm이 online이기 때문에, MOC는 online video strema에 applied 될 수 있죠.
여기까지 하겠습니다.
high task... 막막하네요 정말로..
이건 skeleton은 아닌데
여튼 concatnate로 temporal information을 가져가네요
그럼 당연이 correlation보다 성능을 떨어지겠고요
gcn에 비해서도 조금을 떨어지겠네요
temporal information 때문에요.
그치만 진짜 쉽지 않아요
그놈의 하드웨어..하드웨어..edge...임베디드 하...
하.. 조금은 현타가 올라하네요 ㅎㅎ
여튼 여기까지 하겠습니다.



