시작하기에 앞서
action recognition는 conv를 사용하는 부류와 transformer를 사용하는 부류가 있죠
그 중에서 conv를 사용하는 줄기는 다시
3 줄기의 stream로 나뉩니다.
3D conv를 사용하는 stream,
temporal과 spatial을 나누는 stream
그리고 GCN을 이용하는 stream이죠
위에서 언급한 stream들은 현재 하드웨어에서
사용이 불가능해요..
해당 하드웨어사의 API로만으로 가속기에 mapping할 수가 없거든요
여튼 이번글에서는 GCN과 관련된 stream을 보도록하죠
Abstract
Graph convolutional networks는 skeleton-based action recognition에 광범위하게 사용되죠. 이는 non-Euclidean data의 ability를 excellent하게 modeling한다는 점이기 때문이고요. graph convolution은 local operation이기 때문에, short-range joint dependecies와 short-term trajectory에만 사용될 수 있죠. distant joints relations나 various actions를 구별하는데 필수적인 long-range temporal information을 model하는데 실패했죠. 이 문제를 해결하기 위해, 저자들은 multi-scale spatial graph convolution ( MS-GC )와 multi-scale temporal graph convolution ( MT-GC ) module 을 제안합니다. 이들은 spatial 과 temporal dimensions에서 receptive field를 풍부하게 하죠. 구체적으로 MS-GC 과 MT-GC module는 corresponding local graph를 subgraph convolution의 set으로 분해합니다. 이는 hierarchical residual architecture를 foming함으로써 가능하고요. additional parameters의 도입없이, features는 sub-graph convolutions의 series를 활용해 처리되죠. 각 node는 multiple spatial and temporal aggregations를 그들의 neighborhoods를 활용해 complete하죠. 최종 equivalent receptive field는 accordingly enlarged 됩니다. sort- and long-range dependecies 모두를 capturing할 수 있죠. 이 두 modules를 coupling함으로써, 저자들은 multi-scale spatial temporal graph convolutional network( MST-GCN )을 제안합니다. action recognition을 위한 motion representations를 효과적으로 학습하는 multiple blocks를 쌓은 network이죠. MST-GCN은 NTU RGB+D, NTU-120 RGB+D 그리고 kinetics-Skeleton benchmark datasets에서 놀랄만한 성능을 달성했다고 합니다.
Introduction
Human action recognition은 다양한 분야에서 많은 집중을 받고 있죠. 가령 video surveillance, human machine interaction, virtual reality, video analysis 등에서 말이죠. human action recognition에 대한 current studies는 RGB video based 와 skeleton based로 나눌 수 있는데요. RGB video based methods와 비교해서, skeleton based methods는 computationally efficient하죠. skeleton data 는 human structure를 2D나 3D coordinates를 가지고 represents하기 때문이죠. 게다가, skeleton data는 human actions을 위한 high-level information을 convey하죠. 이는 appearance variation과 environmental noises에 stronger robustness를 보여주죠. 가령 background clutter, illumination changes 같은 것들에 더 robust하죠. 그럼으로 skeleton data를 활용한 human action recognition 더욱 집중받아 왔고요.
skeleton-based action recognition 을 위한 discriminative spatial and temporal features를 extract하기 위해, 많은 연구가 있어왔죠. joints의 spatial configuration과 temporal dynamics에 embedded 된 pattern을 학습하기 위해서 말이죠. conventional deep-learning-based methods는 human action representations를 CNNs와 RNNs를 활용해 학습하죠. 이 방법들은 manually pseudo-image나 coordinate vectors와 같은 grid-shape 종류로써 skeleton sequence를 construct하죠. skeleton은 naturally, non-Euclidean geometric space에서 graph로써 structed되기 때문에, 이 methods는 human joints 간의 inherent relationships를 explore하는데 실패하죠. 최근, GCN-based method이 drawbacks를 다뤘고 joint를 활용해 spatial temporal skeleton graph를 constructed 했죠. graph nodes 와 human body와 time 모두에 대해 natural connectivities를 graph edge로 활용해서 말이죠. 그럼으로 human joints 간의 spatial temporal relations는 skeleton graph의 adjacency matrix에 well embedded 되죠.
이어 나온 연구는 GCN의 수 많은 effective variants를 제안해왔죠. 그러나 그들은 대게 short-range connections를 고려했죠. 그러나, long-range dependencies는 action recognition을 위해서 중요하죠.

예를 들면, Fig 1에 설명 되어있는 것처럼, (1) " walking "은 balance를 maintain하는 whole body의 coordination을 요구하죠. 반면에 " hand waving " 은 hand에 의해 accomplished될 수 있고요. different actions 가 different body parts의 coordination을 요구하기 때문에, different range joints를 capture하는 multi-scale feature extractor를 design 하는 것은 매우 중요합니다. (2) " Jumping up " 과 " cheering up " 은 다소 애매모호 할수 있죠. leg parts의 movement 만 본다면 말이죠. 그럼으로, action의 essential contextual information을 capturing하는 것은 large receptive field를 요구하고, jump가 단지 " jumping up " 이나 "cheering up"을 위한 jump 인지를 판단하는 데 도움을 주죠. (3) "Wearing on glasses" 와 "taking off glasses"는 short period에서 매우 ambiguous합니다. 이는 long-range temporal information과 spatial domain에서 distant joints relations을 capture하는 algorithm을 요구하죠. 요약하면, short-range joints dependencies와 spatial domain에서 distant joints relations 모두를 capturing 하는 것과 short-term trajectory와 long-range temporal information을 considering 하는 것이 skeleton-based action recognition에서 필수적이라는 겁니다. 이 문제를 다루는 많은 연구들이 있었지만, 이 문제는 해결되기에는 멀었죠.
short-range joints dependencies와 distant joints relations 모두를 capture하기 위해, 저자들은 MS-GC module을 제안합니다. 이는 multi-scale spatial features를 extracting할 수 있죠. MS-GC는 spatial graph convolution opertion을 adjacent subsets 간에 residual connections를 활용한 hierarchical structure을 formulate한 sub-graph convolution을 대체합니다. feature가 module을 통과할 때, features는 neighboring nodes와 multiple information exchanges 했음을 깨닫게 되죠. 그리고 equivalent spatial receptive field는 distant joints간의 relations를 cature하기 위해 increased 되죠. multi-scale temporal modeling을 위해, 저자들은 MS-GC를 temporal domain으로 확장합니다. 그리고 multi-scale temporal graph convolution module을 제안하죠. MS-GC module과 비슷한데, MT-GC module은 distant frames 간의 long-range temporal relationship을 modeling할 수 있죠. 이 두 modules는 complementary하며 network에 multiscale spatial 과 multi-scale temporal modeling abilities를 부여하는데 일조하죠. 저자들은 이 두 modules을 basic block으로써 combine하는 two approaches를 고안합니다. 그리고 multi-scale spatial temporal graph convolution network ( MST-GCN )을 multiple blocks를 쌓음으로써 제안하죠. 3 가지 lage-scale datasets에 대한 실험은 얻어진 model의 effectiveness를 증명하죠. contributions는 아래와 같이 요약되죠.
- multi-scale spatial graph convolution module은 local joints connectives와 spatial modeling을 위한 non-local joins realtions 모두를 capture하죠
- multi-scale temporal graph convolution module은 long-range temporal dynamics를 위한 temporal receptive field를 효과적으로 enlarge하죠
- MS-GC와 MT-GC modules를 integrating함으로써, MST-GCN을 제안하죠.
Related Works
Neural Networks with Graph
Graph neural network는 social networks나 human skeleton와 같은 graph structue data 효율적인 representation 때문에 많은 관심을 받고 있죠. GCN-models는 두 가지 flow로 나눠지는데요 : spectral-based methods와 spatial-based methods죠. spectral-based GCNs는 grah signals를 eigen-decompositions 기반 graph spectral domains로 transform하죠. 그리고 convolution 을 graph spectral domain에서 수행하죠. 이는 eigen-decomsition에 의해 야기되는 heavy computation cost 때문에 computational efficiency 관점에서 제한되죠. 반면에, spatial-based GCN은 Euclidean space부터 non-Euclidean space까지 convolutional network의 generalization 이죠. 이는 graph nodes와 spatial domain에서 그들의 neighbors에 대해 convolution operation을 직접적으로 구현합니다. 이 연구는 spatial-based method를 따르죠.
Skeleton-Based Action Recognitoin
RGB video에 대해 alternative data source로써 skeleton data는 action recognition에서 광범위하게 사용되죠. backgrounds의 variations에 robustness하니까요. skeleton-based human action recognition에 대한 methods는 two flow로 나뉩니다. hand-crafted-based 와 deep-learning-based 입니다. hand-crafted-based methods는 joints angles, distances 그리고 kinematic features와 같은 physical intuitions에 기반한 handcrafted features를 designing 하는데 초점을 맞추죠. 그러나, manually features는 designing 하는 것은 많은 energy를 요구하죠. 그리고 action과 관련된 all factors를 고려하기 어렵습니다. deep learning의 development를 활용해, data-driven approaches는 action patterns를 automatically 학습하는데 그렇기에 더 많은 관심을 끌었죠. 몇몇 RNN-based models는 skeleton data를 coordinate vectors의 time sequences로써 model했죠 그리고 consecutive frames 간의 temporal dynamics를 cpature하죠. bi-RNNs나 deep-LSTMs 그리고 attention-based model 같은 것들이 있죠. CNN-based models는 motion patterns를 skeleton image로 embed하고자 하죠. 놀랄만한 결과역시 달성했고요.
최근, graph-based methods는 더 많은 관심을 끌었습니다. body joints간의 relations를 model하는데 우월하기 때문이죠. Yan, Xiong, 그리고 Lin은 spatial temporal graph convolutionla network( ST-GCN )을 제안했죠. 이는 graph structure과 같은 skeleton data를 직접 model하죠. distant joints 간의 relations를 capture하기 위해, 몇몇 data-dependent methods가 제안되었죠. different joints 간의 relation을 adaptively 학습하는 additional mechanism이 도입되었습니다. 반면에 몇몇 연구들은 multi-scale structural features를 추출하는데 skeleton adjacency matrix의 higher-order polynomials를 통해 추출하죠. multiple-hop modules를 도입했고 이는 one-order approximation이 야기하는 representational capacity의 한계를 깨부셨죠. 그들 mehods와 다르게, 저자들은 sub-graph convolutions의 series를 사용하죠. 이는 short-range joints dependencies와 distant joints relations 모두를 capture하는 residual connections에 의해 cascaded 되고요. multiscale temporal modeling을 위해, Liu et al은 regular temporal modeling을 multi-scale learning을 활용해 강화하고 parallel 3x1 kernel sizeds를 temporal receptive fields를 enlarge하는 different dilation rates를 활용해 deployed합니다. 반면 저자들의 model은 temporal receptive field가 single block에서 enrich 하고 short- and long-range temporal information을 hierarchical architecture를 통해 aggregates하죠.
Methodology
이 section에서, 저자들은 간략하게 ST-GCN을 review합니다. 그리고나서 저자들은 skeleton-based action recognition을 위한 MST-GCN을 상세하게 설명하죠
Basic Graph Convolution
human skeleton graph는 아래와 같이 정의되죠

V = { v_ti | t=1, ... , T, i = 1, ... ,V } 는 skeleton sequence에서 모든 joints를 포함합니다.

intra-skeleton과 inter-frames edges의 set을 뜻합니다. T는 frames의 수이고 V는 nodes의 수입니다.
spatial domain에서, samling function은 아래와 같이 정의됩니다.

spatial graph convolution의 region range를 결정하죠. 여기서 d( v_tj, v_ti )는 shortest path를 표기하는 데 v_tj부터 v_ti까지의 path죠. parameter D는 spatial range를 controls하고 neighbor graph에서 포함됩니다. human skeleton에서 direct natural connections는 spatial adjacency matrix A_s( R^V x V ) 에 의해 represented 됩니다. A_S_ij = 1입니다 ( i 와 j 가 connected 라면 아니라면 0 이죠 ). refined location inforamtion을 capture하기 위해, spatial configuration labeling funtion이 ST-GCN에서 제안되었는데요. neighbor set을 3 개의 subsets로 나눕니다. (1) root node itself; (2) root node 보다 gravity의 center가 가까운 neighboring node를 포함하는 centripetal subset; (3) root node 보다 gravity의 center가 먼 neighboring node를 포함하는 centrifugal subset. 따라서 A_s는 A^root_S, A^centripetal_S 그리고 A^centrifugal_S 로 나눠지죠. 저자들은 3개의 다른 subsets를 가지고 있습니다. P = { root, centripetal, centrifugal }
temporal dimension을 위해, sampling function은 아래와 같이 정의됩니다.

gamma는 temporal scales를 aggregate하는 parameter 입니다 . temporal adjacency matrix은
A_T( R ^ T x T ) 로 정의되고 consecutive frames 간의 joints의 trajectories를 represent하죠. simple labeling function은 temporal sequence에 기반하고, temporal adjacency matrix은 gamma parts로 나눠지죠 식은 아래와 같고요
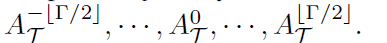
정의된 graph를 활용해, refined sampling과 labeling function, v_ti node에 대한 grah convolution operations는 아래와 같이 공식화 되죠
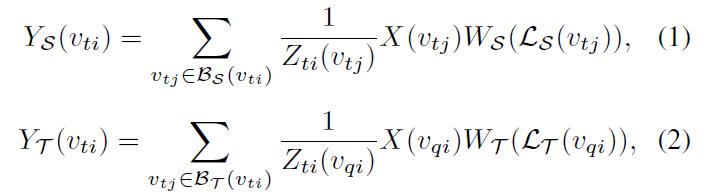
여기서 X( dot )은 node의 feature입니다. W_S( dot ) 과 W_T( dot )은 weight functions 이고 weights의 set으로부터 label L_S( v_tj) 와 L_T( v_qi )에 의해 indexed 된 weight를 allocate하죠. Z_ti ( dot ) 은 corresponding subset의 수이고 feature representations를 normalize하죠. Y_S( v_ti )와 Y_T( v_ti )는 node v_ti에서 각각 spatial graph convolution 과 temporal graph convolution 을 나타내죠.
Implementation
spatial graph convolution의 implementation은 starightforward 하지 않은데요. 구체적으로 network의 feature map은 X ( R^C x T x V )로 표기하죠. C는 channels의 number입니다. ST-GCN을 구현하기 위해 Eq1은 아래의 식으로 변형됩니다.


식 (3) 아래의 식은 p subset의 spatial configuration에서 normalized adjacency matrix입니다.

이 식은 degree matrix이고 alpha는 0.001로 set됩니다. 이는 empty rows를 피하기 위함이고요. W^(p)_S ( R^C_out x C_in x 1 x 1 ) 은 1x1 convolution operation의 trainable weight vector입니다. M^(p) ( R^ N x N ) 은 mask map 이고 각 joint의 importance를 나타내죠. W와 M 사이의 연산자는 dot product입니다. dot multiplication operation은 adding new edges 없이 existing edges의 importance만을 change 할 수 있죠. 그럼으로 저자들은 dot product operation을 additional operation을 활용해 대체합니다. Eq3은 아래의 식으로 변형됩니다.
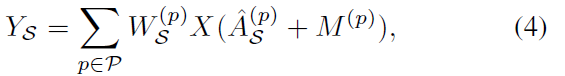
spatial temporal graph의 consistency와 temporal dimension에서 video를 고려하여, 저자들은 temporal graph convolution을 classical convolution operation을 활용하여 구현했죠. Eq2는 아래와 같이 나타납니다.
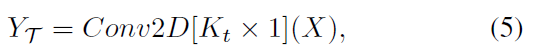
여기서 Conv2D[K_t x 1]는 classic 2D convolutional operation이고 kernel size는 K_t x 1 이죠.
ST-GCN에서 D는 1로 K_t는 9로 set됩니다. 이는 limited spatial temporal receptive field와 flexibilty의 부재에 기인하죠. 이들 문제를 해결하기 위해 저자들은 MS-GC와 MT-GC module을 제안합니다.
Multi-Scale Spatial Graph Convolution Module
최근 연구는 short-range nodes와 long-range nodes 간의 dependencies capturing 하는 것이 skeleton based human action recognition에서 필수적이라는 것을 보여주죠. 그러나, 이들 methods는 different nodes 간의 relationship을 adaptively 학습하기 위한 additional modules를 도입하거나 skeleton adjacency matrix의 higher-erder polynomials를 사용하죠. 이 방법들은 performance와 parameters 간의 balance를 well control 하는 데 실패했죠. 이 논문에서는, 저자들은 MS-GC module을 제안합니다. 이 모듈에서 spatial features와 corresponding local graph convolution은 subset의 group으로 split 됩니다. main idea는 Res2Net에 영감을 받았는 데, 해당 논문은 image processing의 many fields에대해 굉장한 영향을 끼쳤죠. 저자들은 Res2Net을 skeleton data를 활용한 GCN-based action recognition에 transfer 합니다. 제안된 MS-GC module의 architecture는 Fig2에서 볼 수 있죠.
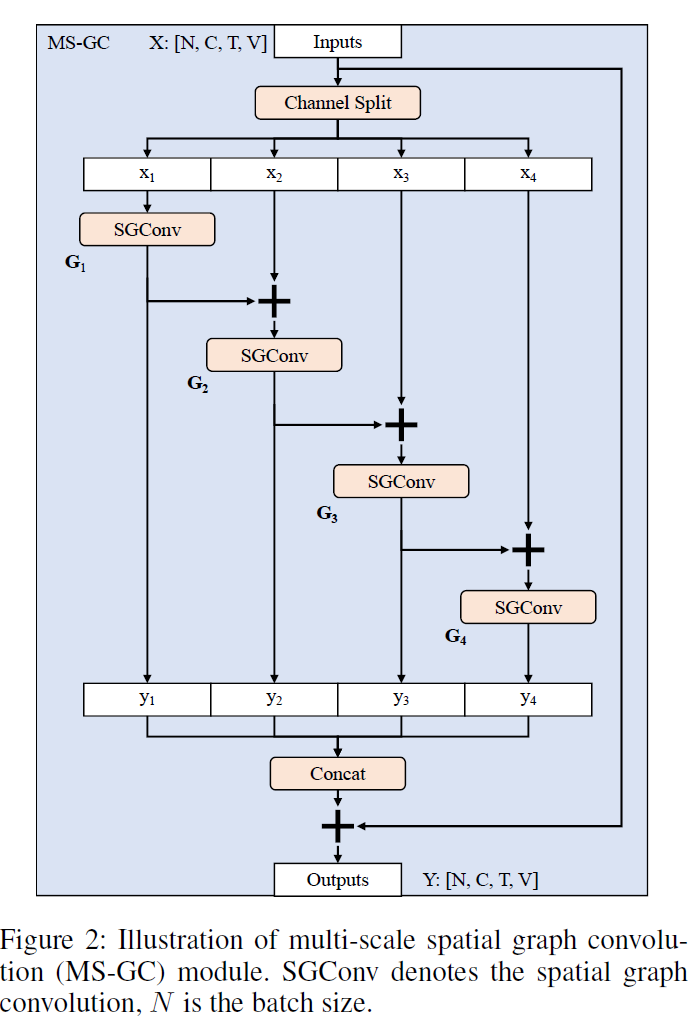
subsets은 hierarchical residual architecture로 formulated되죠. 그래서 features는 hierarchically하게 processed 됩니다. spatial dimension의 equivalent receptive field는 enlarged되고 model은 those distant joints 간의 relations를 capturing 할 수 있죠.
구체적으로, shape 이 [C, T, V]인 input feature X가 주어지면, 저자들은 feature를 channel dimension을 따라 s fragemnets로 나눕니다. x_i로 표기되고 i 는 { 1, 2, .... , s } 이죠. 각 fragment의 shape은 [ C/s, T, V ]입니다. 각 fragment x_i는 corresponding spatial graph convolution을 가지는 데, Eq 4를 사용해 구현되죠. G_i로 표기되고요. 각 sub-spatial graph convolution은 original ones와 비교해 channels의 1/s number를 가집니다. 그리고 accordingly original ones의 1/s^2 parameters만을 가지죠. 게다가, residual connection은 two adjacent fragments 간에 위치하는데, local과 non-local joints 간의 dependencies를 capture하는 receptive fields의 diversity를 enrich하게 하죠. 식으로 보면 아래와 같죠.

여기서 y_i ( R ^ C/s x T x V )는 i_th sub-spatial graph convolution의 output입니다.
이 module에서 s fragments는 다른 receptive fields는 가지죠. 예를 들자면, D는 1로 set 되고 이를 가진, G1 은 1-hop neighbors로부터 information을 aggregate할 수 있죠. 반면 G2는 potentially y1에서 information을 aggregating함으로써 2-hop neighbors로부터 feature information을 receive할 수 있죠. 따라서 last fragment y_s의 equivalent receptive field는 몇 차례 enlarged 되죠. 마지막으로, 모든 fragments는 concatenated 되죠. 그리고 entire module을 위한 additional residual connection이 model converge를 돕기 위해 adopted 되죠. MS-GC module의 outputs는 아래와 같이 계산됩니다.
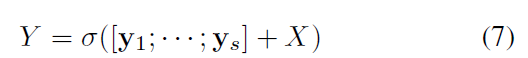
sigma는 activation function입니다. obtained output feature Y는 typical approaches에서 single local graph convolution을 사용해 얻어진 local spatial representations 보다 우월한 different distances에서 nodes 간의 spatial feature representation을 capturing하는 것을 포함하죠.
MS-GC module은 efficient 합니다. complexity와 s를 adjusting함으로써 model의 multi-scale representation ability 간의 balance를 control 할 수 있죠. additional parameters와 time-consuming operations의 도입 없이, module은 short- and long-range joints 간의 dependencies를 capture 할 수 있죠.
Multi-Scale Temporal Graph Convolution Module
Temporal modeling은 action recognition에서 필수적이죠. long-range temporal modeling이 기존 연구에서 무시되었지만요. Long-range temporal dependence는 temporal information을 통해 actions 간의 ambiguity를 reduce할 뿐만 아니라, spatial temporal features를 더 잘 학습하도록 돕는 global information을 제공하죠. 많은 기존 연구는 architecture 전반에 걸처 fixed kernel size를 가진 temporal convolutions를 사용해 temporal modeling을 수행했죠. long-range temporal relationship은 deep networks에서 local temporal graph convolutions를 repeated stacking을 함으로써 간접적으로 modeled되었죠. 그러나 local convolution operations의 large numer 후에, distant frames 로부터 useful features는 이미 weakened 하게 되고 well captured 될 수 없었죠.
이 problem을 address 하기 위해, 저자들은 MS-GC module을 temporal domain으로 extend하는데요. proposed MT-GC module은 MS=GC 와 similar sturcture를 가집니다. 그러나 additional residual connections는 도입되지 않았죠. local temporal graph convolution을 sub-temporal graph convolutions로 대체하는데 hierarchical residual-like connections를 활용해 construced되었죠. temporal graph convolution은 각 subset에서 같습니다. 그러나, input이 다르죠. MS-GC module과 유사하게, spatial temporal features 가 MT-GC module을 통과할 때, cascaded temporal graph convolution operations의 series가 temporal receptive field를 enlarge하는 corresponding fragments에 applied 되죠. 마지막으로, simple concatenation strategy가 fragments에 adopted 됩니다. 그럼으로, final output은 multi-scale temporal representation을 가지게 되죠. short-range와 long-range temporal relationships가 well captured 되고요.
Multi-Scale Spatial Temporal Graph Convolution
SOTA methods의 fair comparison을 위해, 저자들은 자신들의 multi-scale spatial temporal graph convolution network를 construct하는 데 ST-GCN과 same method를 follow 했죠.

ST-GCN backbone은 Fig3(a) 에서 볼 수 있고, data를 normalize하는 1 batch normalization layer 그리고 spatial 과 temporal features를 extract하는 10 ST-GC blocks으로 구성되어있죠. 각 ST-GC block은, Fig 3(b)에 설명되어 있고, spatial graph convolution과 spatial and temporal feature를 alternately extract하는 foolowed temporal graph convolution을 포함하죠. global average pooling operation은 spatial temporal information을 aggregate하기 위해 adopted되고 final prediction results는 softmax layer를 가진 fully connected layer를 통해 도출됩니다.
저자들의 연구는 discriminative spatial and temporal feature를 extracting하는데 초점이 맞춰져 있죠. 여기에는 MS-GC와 MT-GC를 결합하는 두 가지 modes가 있습니다. first method에서, 저자들은 MS-GC를 가진 spatial graph convolution unit을 대체합니다. 그리고 temporal graph convolution은 MT-GC module로 대체되죠. 두 번째 method는, single block안에서 sub- spatial and temporal graph convolution을 concatenating 함으로써 STR-GC ( spatial temporal residual graph convolution을 construct하는 겁니다. 이는 Fig 3 (c)에 나와있죠. 편의를 위해, 저자들은 sub-temporal graph convolution을 T_i로 표기합니다. 이 module에서 spatial and temporal features는 각 subset에서 alternately하게 updated됩니다. 그리고 corresponding spatial 과 temporal recptive field는 combined explosion effect에 때문에 enlarged되죠. 식으로 표현하면 아래와 같습니다.

first module은 multi-scale temporal feature 과 spatial feature를 extracting 하는데 있어 model의 continuity를 maintain 할 수 있죠. 반면 latter 는 first one 보다 lighter하죠. 그리고 spatial temporal joint learning 에 더 convenient 하다고 합니다. 이 연구는 후속 연구로 할 거라고 하네요. 이 two module의 comparison은 ablation study에 포함될거라고 합니다.
간만에 재미있게 읽었네요.
이유는 막혀 있던 문제를 해결할 아이디어를 얻었기 때문이랄까요
그 문제란
3D conv, transformer, GCN을 못쓰는 경우에
temporal information을 뽑아내는 방법이죠.
해봐야겠지만 여튼 간만에 재밌었습니다.
다음 논문은
ST_GCN을 보도록 할게요.
간단히 다뤘지만 그렇기에 더 쉽게 다가올테니까요 그럼이만



