여기서는 초록이랑
method만 리뷰하겠습니다.
아이디어가 궁금한것이니까요.
이전 글의 토대가 된 논문이기에
이전 글을 참고하시고 싶으면 아래 링크를 봐주셔도 될것 같아요
[꼼꼼하게 논문 읽기]Hidden Two-Stream Convolutional Networks for Action Recognition ( 2018 )
이제 천천히 action recognition으로 한번 가봅시다 optical flow도 확보되었겠다 시작해볼게요 Abstract human actions의 videos를 Analyzing 하는 것은 video frames 중에 temporal relationships를 이해하는 것..
developer-wh.tistory.com
들어가기에 앞서 뭘하고 싶은거냐
optical flow는 low task죠
action recognition과 같은 high task에 적용하기 위해서는
다른 task들이 필요하죠
어떻게 temporal information을 잡아낼거냐가
행동인식에서 중요하기 때문에 그 아이디어를 얻고자 보는거랍니다.
시작할게요
Abstract
Deep convoluutional networks는 still image에서 visual recogniton에 대해 굉장한 성공이 있어죠. 그러나 action recognition에 대해서는, 충분하지 않습니다. 이 논문은 effective ConvNet architectures를 desing하는 principles를 발견하는 것을 목표로하죠. 저자들으니 contribution 은 temporal segment network입니다. 새로운 frame work로 vidoe-based action recogntion framework죠. long-range temporal structure modeling의 idea가 기반이고요. sparse temporal sampling strategy와 video-level supervision이 enable effeicient 하고 effective learning에 합쳐지죠. whole action video를 사용해서요 ( 이것도 해결해야 겠네요. 제가 할 프로젝트는 frame 단위로 받으니까요 .. ) 다른 contribution은 good practices에 대한 연구라고 하네요. 여튼 이정도 하고 넘어갈게요.
Action Recognition with Temporal Segment Networks
이번 section에서 저자들은 TSN을 가지고 action recognition을 수행하는 descriptions를 상세하게 보여준다고 합니다. 구제척으로, 저자들은 먼저 TSN의 framework에서 basci concept을 보여준다네요. 그러고 난다음 TSN을 가지고 two-stream ConvNets을 학습하는데 있어 good practices를 연구한다고 합니다. 마지막으로 학습된 two-stream ConvNets의 detail을 testing 을 보여준다네요
Temporal Segment Networks
two-stream ConvNet의 obvious problem은 long-range temporal structure을 modeling하는 데 inability 에 있죠. 이것은 temporal context에 limited access 때문이고요. 이는 singe frame에 작동하게 designed 되었기 때문이죠. spatial networks에서는 single frame을 사용하고 temporal networks를 위한 short snippet에서는 frame에서는 single stack을 사용하기 때문입니다. 그러나, complex actions은 long time에 걸쳐 여러가지 단계로 구성되어있죠. 때문에 long-range temporal structures를 사용하지 못하는 것은 큰 손실이죠. 이 문제를 다루기 위해, 저자들은 temporal segment network를 제안하죠. video-level framework로 Fig 1에 보여지죠.
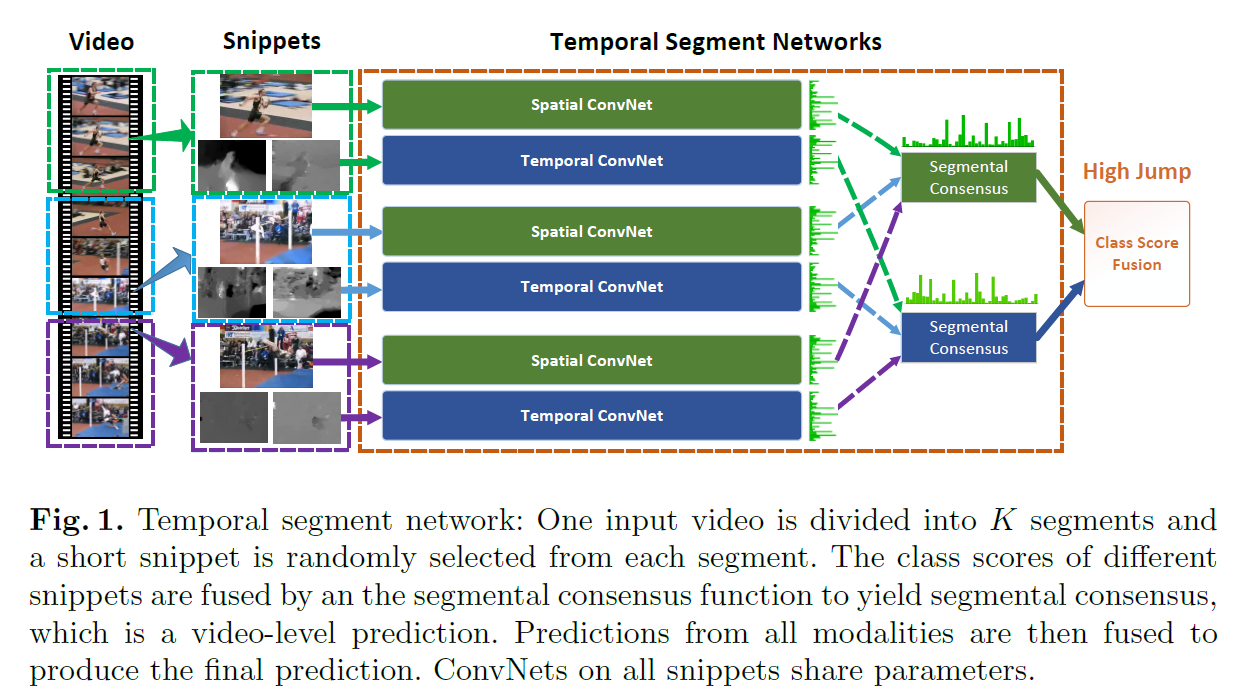
video V가 주어지면, K segment로 나눕니다 ( S1, S2, ..., Sk ) . 그러고 난 다음 temporal segment network는 아래와 같이 snipptes의 seuquence를 models하죠
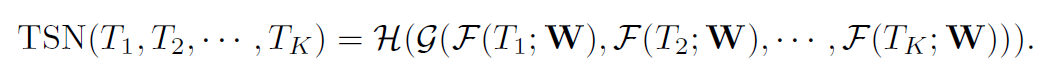
여기서 ( T1, T2, ... , Tk )는 snippets의 sequence입니다. 각 snippet Tk는 corresponding segment S_k로 부터 randomly하게 sampled되죠. F(Tk ; W )는 Tk snippet에 대해 연산되고 all the classes에 대해 class scores를 생성하는 parameter W를 가진 ConvNet이 representing하는 function이죠. segmental consensus function G 는 multiple short snippets 로 부터 얻어지는 outputs를 combine하죠. 이 consensus에 기반해, prediction function H는 각 action class의 probability를 예측합니다. 저자들은 H를 위해 Softmax function을 사용하죠. cross-entropy loss와 결합해 final loss function은 아래와 같습니다

여기서 C는 action classes의 number이죠. y_i는 groundtruth label입니다. 실험에서 snippets K는 3으로 set했습니다. consensus function G의 form은 open question으로 남아있죠. 이 논문에서는 저자드릉ㄴ G의 fomr을 사용하는데요. G_i = g(F_i(T1),...,F_i(TK)). 여기서 class score G_i는 all snippets에 대해 same class의 score로 부터 inferred 되죠. 저자들은 실험을 통해 evenly averaging을 사용하기로 했답니다.
이 temporal segment network은 differentiable하거나 subgradients를 가집니다. 이는 stnadard back-propagation을 통해 parameter W를 최적화하는 multiple snippets를 사용하게 해주죠. back-propagation process에서, model parameters의 gradients W는 loss value L 과 관련되며 아래와 같이 유도될 수 있죠

K는 segments의 수입니다. gadient-based optimization method를 사용할 때, SGD는 parameter update 가 all snippet-level prediction으로부터 유도된 consensus G를 사용한다는 것을 보장해줍니다. 이런 최적화방식에 따라, TSN은 전체 video로부터 model parameters를 학습할 수 있죠. 그러는 동안 all videos에 대한 K를 fixing함으로써, 저자들은 sparse temporal sampling strategy를 assemble합니다. 여기서 sampled snippets는 frames의 small portion을 포함하죠. 이는 computational cost를 drastically 하게 reduces합니다.
Learning TSN
TSN은 video-level learning을 수행하는 solid framework인데요. 몇 가지 practical concerns가 다뤄져야하죠. 가령 training samples의 제한된 수라던가 하는 것들이요.
Network Architectures
Network architecture는 NN design에서 중요요소죠. 몇몇 연구는 깊은 NN이 object recognition performance를 향상시킨다고하죠. 그러나, original two-stream ConNets는 얕은 network structure를 사용했죠. 이 연구에서 저자들은 BN-Inception을 선택하죠. original two-stream ConvNet과 유사하게, spatial stream ConvNet은 single RGB images에서 동작합니다. temporal stream은 optical flow fields의 stack을 input으로 받아들이죠.
Network Inputs
저자들은 TSN의 discriminative power를 강화하는 input modalities를 사용하고자 하죠. two-stream ConvNet에서는 RGB images를 spatial stream에 사용하죠 그리고 stacked optical flow fields를 temporal stream에 사용합니다. 여기서, RGB difference와 warped optical flow fields 에 대해 연구합니다.
single RGB image는 specific time point에 static apperance를 encode하죠. 이는 이전과 다음 frames에 대한 contextual information이 부족하구요. RGB difference는 연속된 frame에 의한 것이며 apperance change를 묘사하죠. 이는 motion salient region과 관련 있고요. 저자들은 RGB difference를 input으로 주고 성능 향상을 관찰했다고 합니다.
temporal stream ConvNets은 optical flow fields를 input으로 받아들이죠. motion information을 capture하기 위함이고요. 그런데 realistic videos에서는 camera motion이 있죠. 즉 human에만 집중하지 못하죠.

Fig 2에서 보여지듯, 주목할만한 horizontal movement가 background에서 강조되고 이는 camera motion 때문이죠. 저자들은 warped optical flow fields를 additional input modality로써 제안합니다. 저자들은 warped optical flow를 homograph matrix을 estimating 함으로 추출하고, camera motion을 compensating하죠. warped optical flow는 background motion을 suppresses 하고 actor에 집중할 수 있게 하죠.
나머지 내용은 skip할게요
음 얻어갈게.. 별로없네요



