참..caffe를 사용해서
pwcnet 학습이 드디어 끝났네요
torch좀 쓰지 꼭 caffe가 필요하다해서..
진짜 말그대로 개고생했습니다ㅋㅋ
3090에 cudnn8을 쓰기때문에 빌드부터 학습까지
쉽지가 않았네요. 뭐 우선은 끝냈으니까
다시 오랜만에 논문이나 읽어봅시다
오늘은 action recognition에 관한 논문입니다
3D CNN이라..못쓰겠네요..하
Abstract
Spatiotemporal action localization은 information의 two sources를 designed architecture에 incorporation 해야 하죠. 두 information이란 (1)이전 frame으로부터 temporal information과 (2)key frame으로터 spatial information을 말하죠. Current SOTA approaches는 이 informations 대게 추출하는데 separate network를 가지고 추출하죠. 그런 다음 detection을 얻게 해주는 fusion을 위한 extra mechanism을 사용합니다. 이 연구에서는, 저자들은 YOWO를 보여주는데요. real-time spatiotemporal action localization을 위한 unified CNN architecture죠. YOWO는 single-stage architecture인데요. 두 개의 branches는 temporal 과 spatial information을 동시에 추출하죠. 그리고 bounding boxes와 action probabilities를 video clips으로 부터 one evaluation에서 예측합니다. whole architecture가 unified 하기 때문에, end-to-end로 optimized가 가능합니다. YOWO architecture는 빠릅니다. 16-frames input clips에서 34 FPS, 8-frames input clips에서 62 FPS가 나오죠. 당시까지 최고의 성능이라고 합니다. J-HMDB-21과 UCF101-24에서도 SOTA라고 하네요. 뭐 single-stage architecture임 역시 강조하고 있네요.
Introduction
spatiotemporal human action localization의 topic은 최근에 spotlighted되고 있죠. action의 occurrence를 recognize할 뿐만아니라 time과 space에서 action을 localize 해야하죠. 이런 task에서, 정지된 images에서 object detection과 비교해보면, temporal information은 매우 중요한 역할을 하죠. spatial 뿐만 아니라 temporal fetures를 aggregate하는 efficient strategy를 Finding하는 것은 더 어려운 challenging problem을 야기하죠. 반면에 real-time human action detection은 vision application에서 점점 더 중요해지고 있죠. human-computer interaction( HCI ) systems, unmanned aerial vehicle( UAV ) monitoring, autonomous driving 그리고 urban security system 같은 곳에서 그 중요도가 더 올라간다고 하네요. 때문에, 이 문제를 다루는 더 효과적인 framework을 사용하는 것은 가치가 있죠.
Faster R-CNN에서 영감을 받아, 대부분의 SOTA 연구는 two-stage network architecture는 action detection으로 확장되었죠. 첫 번째 stage에서 proposal이 생상되고 난 뒤, classification과 localization refinemnet가 두 번째 stage에서 수행되죠. 그러나 이 two-stage pipelines는 3 가지 결점이 있죠. 먼저, frame에 걸쳐 bounding boxe로 구성되는 action tube의 생성은 2D case보다 더 복잡하고 time-consuming하다는 겁니다. classification performance는 극단적으로 이 proposals에 의존하죠. 이 proposals에서 detected bounding boxes는 following classification task를 위한 sub-optimal을 수행합니다. 두번 째로, action proposals는 video에서 humans의 features에만 집중한다는 점입니다. background의 som attributes와 humans 간의 relataionship을 무시하죠. 이는 action predictions을 위한 crucial context information을 제공할 수 있음에도 불구하고 말이죠. 세번 째 문제는 region proposal network과 classification network을 따로 training하는 것은 global optimim을 찾을거란 확신을 주지 못한다는 겁니다. 대신에, two stage의 combination으로부터 local optimum은 찾아질 수 있겠죠. training cost 역시 single-stage networks에 비해 크죠. 따라서 더 긴 시간과 더 많은 memory가 요구되죠.
이 논문에서, 저자들은 새로운 single-stage framework, YOWO를 제안하는데요. spatiotemporal action localization을 위한 framework이죠. YOWO는 위에 언급한 3 가지 결점을 예방하죠. single-stage architecture니까요. YOWO의 직관적인 idea는 human's visual congnitive system에서 따왔죠. 예를 들어보자면, 우리가 TV 앞에서 드라마의 스토리를 받아들일 때, 각 시간에 우리 눈은 single frame을 capture하죠. artist가 수행하는 각각의 action을 이해하기 위해, 우리는 current fame information( 2D features from key frame)을 우리 기억에 (3D features from clip) 저장된 이전 frames로부터 obtained kownledge를 relate해야하죠. 그 후에, 두 종류의 features는 reasonable conclusion을 우리에게 제공하기 위해 합쳐지죠. 이 설명을 그림 1에 표현했다고 하네요. 아래서 확인해 보시죠.

YOWO architecture는 두 개의 branches를 가지는 single-stage network 인데요. One branch는 key frame의 spatial features를 2D-CNN을 통해 추출합니다. 반면 다른 branch model은 이전 frames로 구성된 clip의 spatiotemporal features를 3D-CNN을 통해 추출하죠. 이를 위해, YOWO는 causal architecture이죠. 들어오는 video streams에 대해 online으로 operate가 가능하다고 하네요. 이 2D-CNN과 3D-CNN features를 smoothly aggregate하기 위해, channel fusion과 attention mechanism이 사용됩니다. 이는 inter-channel dependencies를 최대한으로 활용하기 위함이죠. 마지막으로 저자들은 fused features를 사용해서 frame-level detections를 생성합니다. 그리고 action tube를 생성하기 위해 linking algorithm을 제공합니다.
real-time capability를 유지하기 위해, 저자들은 YOWO를 RGB modality에서 사용합니다. 그러나, YOWO architecture는 RGB modality에서만 돌아가는 것이 아님을 강조하네요. Different branch는 different modalities를 위해 YOWO에 삽입될수 있는데요. optical flow, depth 같은 것들이 있겠죠. 게다가, 2D-CNN과 3D-CNN branches에서 어떤 CNN architecture라도 desired run-time performance에 따라 사용될 수 있습니다.
YOWO는 최대 16 frames input을 계산하죠. short clip lengths는 spatiotemporal action localization을 위한 faster runtime을 achieve하기 위해 필수적이죠. 그러나, 이런 small clip size는 temporal information을 accumulation하기 위한 limiting factor죠. 따라서 저자들은 trained 3D-CNN을 사용하여 whole videos에 대해 겹치지 않는 8-frame clips 에 대해 3D-CNN을 활용해 features를 추출함으로써 long-term feature bank를 사용합니다. YOWO의 Training은 normally 수행됩니다. 그러나 inferance time에 저자들은 key-frame을 중심으로하는 3D features 평균합니다. 이는 성능 향상에 도움이 되었다고 하네요.
Contributions
(1) 저자들은 real-time single-stage framework 을 제안했습니다. vedio stream에서 spatiotemporal action localization을 위한 것이죠. YOWO이라 불리고 end-to-end로 high efficiecency로 훈련될 수 있죠. 2D-CNN과 3D-CNN에 의해 추출된 features에 대해 bounding box regression을 달성한 첫번째 연구라고 하네요. 이 두 종류의 features는 서로에게 상호 보완적 효과를 가집니다. action calssification과 final bounding box regression에 대해 말이죠. 게다가, 저자들은 channel attention mecanism을 사용했죠. 이는 features를 smoothly aggregate해줍니다. 저자들은 실험적으로 channel-wise attention mechanism이 concatenated feature 를 가지고 inter-channel relationship을 models하죠. 그리고 더 합리적으로 features를 fusing함으로써 performance를 significantly하게 boost하죠.
(2) 저자들은 YOWO architecture에 대해 detailed ablation study를 수행했죠. 저잗르은 3D-CNN, 2D-CNN 그들의 aggregatation 그리고 fusion mechanism의 효과를 실험했습니다. 게다가 저자들은 다른 3D-CNN architectures와 different clip lengths를 실험했죠. 이는 precision과 speed 간의 trade-off를 활용한 것이죠.
(3) YOWO는 AVA dataset에서 평가되었습니다. YOWO는 SOTA와 비교해서 경쟁력을 갖춘 single stage architecture의 선구자죠. 게다가, YOWO는 causal architecture인데요 ( i.e. future frames가 사용되지 않았죠 ) 따라서 online으로 operate 할 수 있죠.
(4) YOWO를 J-HMDM-21과 UCF101-24에서 평가했습니다. 그리고 SOTA를 달성했죠. 게다가, YOWO는 16-frame input clips에 대해 34 FPS, 8-frame input clips에 대해 62 FPS로 동작하죠. spatiotemporal action localization task에서 가장 빠른 속도라고 하네요
Related Work
Action recognition with deep learning
deep learning은 image recognition에서 상당한 향상을 야기했기 때문에, 많은 최근 연구는 videos에서 action recognition을 위해 deep learning을 확장하고자 노력했죠. action recognition을 위해, 각 개별 image에서 spatial features를 추출하는 것 외에도, 이 frames에 걸친 temporal context 역시 고려되어야 할 필요가 있죠. Two-strema CNN은 효과적인 strategy이죠. spatial 과 temproal features를 각각 추출하고 합치기에 말이죠. 이 연구들은 optical flow를 바탕으로 합니다. optical flow는 추출하기에 상당한 computational power가 들어가죠. 이는 time-consuming process의 원인이 되죠. CNN features를 시간동안에 integrate하는 다른 대안은 recurrent networks를 구현하는 것이죠. 그렇지만 성능면에서 만족스럽지가 않습니다. 3D-CNNs는 video analysis task에서 최근 많이 사용되고 있죠. 3D-CNN은 spatial과 temporal dimension 모두로 부터 features를 학습합니다. 3D-CNN는 처음으로 spatiotemporal features를 추출하기위해 사용되었죠. 후에, 많은 3D-CNN architectures가 action recognition task를 위해 제안되었습니다. C3D, I3D, P3D, R(2+1)D, SlowFast 등이 있죠. 한 연구에서 성능에 대해 dataset size의 효과가 몇몇 3D-CNN architectures에 대해 조사했죠. 3D-CNN archtectures는 2D-CNNs 와 비교하여 훨씬 많은 parameters를 가지고 있고, 이는 computationally expensive하게 만들죠. 또 다른 연구에서는, 몇몇 유명하고 resource efficient한 CNN architectures의 3D version에 대해 조사했는데요. resource efficiency를 위해, 몇몇 연구는 2D-CNN을 이용해 single images로 부터 2D features를 학습하는데 초점을 맞췄습니다. 그런 다음 3D-CNN을 활용하여 temporal features를 학습하는 features를 2D features를 합쳐 만들었죠.
Spatiotemporal action localization
images에서 object detection을 위해, R-CNN series는 region proposals를 추출하죠. 이때 selective search나 Region Proposal Network을 사용하고요. 그리고 이 potential regions에서 objects를 classify하죠. Faster R-CNN이 SOTA results를 object detection에서 달성했음에도 불구하고, real-time task에 사용하기 어려웠죠. 2 stage였기 때문이죠. 그러는 반면, YOLO와 SSD는 one stage로 이 작업을 간단하게 하는 것을 목표로 했죠. 그리고 뛰어난 real-time performance를 달성했습니다. videos에서 action localization을 위해, R-CNN series의 성공 떄문에, 많은 approaches는 먼저 사람을 각 프레임에서 detecting하고 다음에 action tube로써 합리적으로 bounding boxes를 linking 할 것을 제안했죠. Two-stream detectors는 optical flow modality를 위한 original classifier에 기초하여 additional stream을 도입했죠. 또 다른 연구는 clip tube proposals를 3D-CNN을 활용하여 생성하고 해당 3D features에서 regression과 classification을 달성했습니다. 따라서 region proposal은 해당 연구에서는 필수적이죠. 최근 연구에서, 해당 연구의 저자들은 3D capsule network를 제안했는데요. vedio action detection을 위한 것이죠. 3D capsule network는 pixel-wise action segmentation을 수행합니다. action classification을 포함해서 말이죠. 그러나 omputational complexity와 parmeters 수의 관점에서 너무 expensive하죠. 왜냐하면 이 network는 3D-CNN을 기반으로한 U-Net이기 때문이죠.
Attention modules
Attention은 long-range dependencies를 capture하는 효과적인 mechanism이죠. 그리고 image classification과 scene segmentation에서 performance를 boost하는 CNNs에 활용하고자 시도 되었습니다. Attention mechanism은 spatial-wise와 channel-wise로 구현되었는데요. spatial attention은 features 중에서 inter-spatial relationship을 다룹니다. 반면에 channel attention은 중요한 channels를 강화하고 나머지를 약화시키죠. channel-wise attention block 떄문에, Squeeze-and-Excitation module은 적은 computational cost를 가지고 CNN's의 performance를 향상시키는데 이점을 가지고 있죠. 반면에, video classification tasks를 위해, non-local block은 spatio-temporal information을 고려했죠. frames에 걸친 features의 dependencies를 학습하기 위해서 말이죠. 이것은 self-attention strategy로 볼 수 있죠.
이전 연구들과는 다르게, 저자들은 새로운, unified framework을 제안합니다. YOWO는 spatio-temporal action localization을 위해 제안됩니다. 저자들은 단 한번의 clip을 사용하고 key frame에서 해당 actions를 detect하죠. 그러나, optical flow computation의 complex를 피하기 위해, 저자들은 key feature의 2D features와 clips의 3D features를 함께사용합니다. 후에, 이 두 가지 features는 하나로 합쳐집니다. 이는 attention mechanism을 적용하죠.
Methodology
이 section에서, 저자들은 먼저 YOWO's architecture를 상세하게 설명합니다. 2D feature를 key frame으로 부터 추출하고, 3D features를 input clip으로부터 동시에 추출하죠. 그리고 그들을 aggregates 합니다. 다음으로 channel fusion과 attention mechanism의 구현에 대한 논의합니다. 이것은 performance boost를 위해 굉장히 중요하죠. 마지막으로 저자들은 training process에 대해 상세하게 설명합니다. 그리고 untrimmed videos에서 action tube의 생성을 위한 improved bounding box linking strategy에 대해서도 상세하게 설명합니다.
YOWO architecture
YOWO architecture는 Fig 2에 설명되어 있죠. 2 part로 나누어져 있는데, 3D-CNN branch, 2D-CNN branch, CFAM 과 bounding box regression parts로 나눠져 있죠. 아래서 함께 확인하시죠.

3D-CNN Branch
human action understanding을 위해 contextual information이 중요하기 때문에, 저자들은 spatiotemporal features를 추출하는 3D-CNN을 사용합니다. 3D-CNNs는 motion information을 capture할 수 있죠. convolution operation을 space dimension 뿐만 아니라 time dimension에 적용함으로써 말이죠. 기초적인 3D-CNN architecture는 3D-ResNext-101인데요. Kinetiecs dataset에서 high performance를 가지기 때문이죠. 3D-ResNext-101에 더해, 저자들은 다른 3D-CNN models를 ablation study에서 실험했죠. 모든 3D-CNN architectures에 대해, 마지막 conv layer 후에 모든 layers는 버려집니다. 3D network에 input은 video의 clip인데요, 이는 시간 순서에따러 연속적인 frames로 구성됩니다. CxDxHxW의 shape을 가집니다. 반면에 마지막 conv layer는 C'xD'xH'xW' shape의 feature map을 출력하죠. 여기서 C=3, D는 input frames의 수, H와 W는 input images의 height와 width입니다. C'는 output channels의 수, D'=1, H'=H/32 , W'=W/32 입니다. output feature map의 depth dimension은 2D-CNN의 output feature map 과 match하기 위해 output volume이 [C'xH'xW']로 압축되기 위해 1로 줄여집니다.
2D-CNN Branch
spatial localization problem을 다루기 위해, Key frame의 2D features는 병렬적으로 추출되는데요. 저자들은 Darknet-19를 basic architecture로 사용했다고 하네요. 이유는 accuracy와 efficiency의 좋은 밸런스 때문이라네요. key frame은 C x H x W 모양을 가지고 있고 input clip의 가장 최근 frame 이라고 합니다. 따라서 additional data loader가 필요하지 않죠. Darknet-19의 output feature map은 C'' x H' x W' 인데요. C = 3이고 C''는 output channels의 수 입니다. H' = H/32, W' = W/32 로 3D-CNN case와 유사하죠.
YOWO의 중요한 특징은 2D-CNN과 3D-CNN branches에서 architectures가 임의의 CNN architecture로 바뀔 수 있다는 점입니다. 이것은 YOWO를 더 flexible하게 만들죠. YOWO는 models를 switch하기에 간단하고 노력 절감 가능하도록 설계되었습니다. YOWO는 2개의 branches랄 가지고 unified architecture고 end-to-end로 학습 가능함을 다시 한번 말하네요.
Featrue aggregation: channel Fusion and Attention Mechanism ( CFAM )
저자들은 3D와 2D network의 outputs은 이 두 feature maps가 쉽게 fused 하기 위해 마지막의 두 deimseion을 같은 shape으로 만들죠. 저자들은 두 개의 feature maps를 concatenation을 사용하여 합칩니다. 이는 features를 channels에 따라 간단하게 쌓는 방법입니다. 결과적으로 합쳐진 feature map은 motion과 appearance information을 모두 encodes 합니다. 그리고 encodes 된 feature map은 CFAM module의 input으로 전달되죠. CFAM module은 inter-channel dependencies를 map하는 Gram matrix에 기반합니다. 비록 attention mechanism에 기반한 Gram matrix가 style transfer와 segmentation task에 사용되긴 하지만, 그런 attention mechanism은 다른 sources로 부터 유래된 features를 합리적으로 fusing하는데 이점을 가지고 있죠. 이런 합리적인 fusing은 performance를 상당히 향상시킵니다.
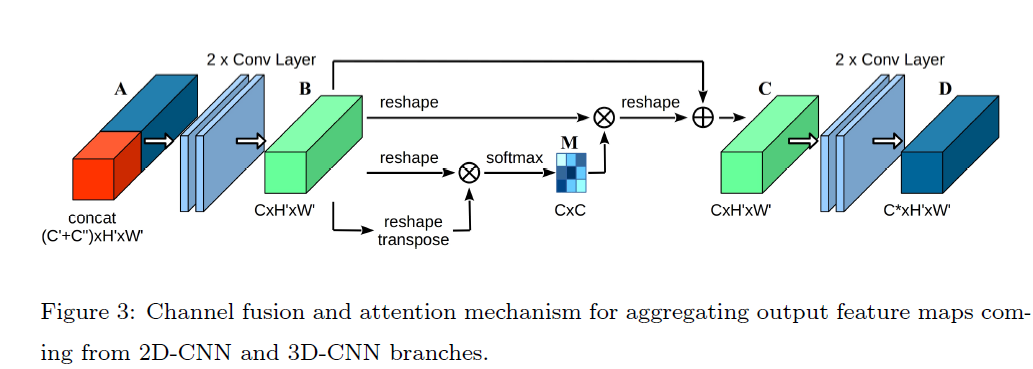
Fig.3 은 사용된 CFAM module을 설명합니다. concatenated feature map A 는 (C'+C'')xHxW 의 region에 포함됩니다. A는 2D와 3D information의 abrupt combination으로 여겨지죠. 즉 A는 2D와 3D information간의 내부 상관관계를 무시합니다. 그럼으로 저자들은 A를 새로운 feature map B( C x H' x W' )를 생성하는 two convolutional layers에 input으로 넣어줍니다. 그런 다음, 몇몇 operations가 feature map B에 수행되죠.
F는 C x N의 region을 가지는데요. F는 feature map B로 부터 나온 reshaped tensor입니다. N = H x W 이고 F가 모든 single channels에서 features는 one dimension으로 vectorized 됨을 의미하죠. 이를 보기 좋게 표현하면 아래와 같습니다.

그럼 F와 transpose F^T( shape is NxC) 간의 matrix product는 Gram matrix ( shape is C x C )를 생성하기 위해 수행됩니다. 이는 channels 간의 feature correlations를 나타내죠. 이를 도식화 하면 아래와 같습니다.

Gram matrix G에서 G_ij의 각 element는 vectorized feature maps i 와 j 간의 inner product를 나타냅니다. Gram matrix을 계산 후에, softmax layer는 channel attention map M ( shape is C x C )을 생성하기 위해 적용되어지죠. M은 아래와 같습니다.
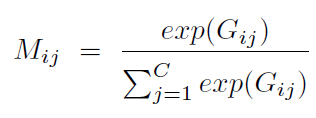
여기서 M_ij는 j^th channel가 i^th channel에 미치는 impact를 측정하는 score 입니다. 따라서 M은 feature map이 주어지면 features의 inter-channel dependency라고 요약될 수 있습니다. attention map이 original features에 impact를 perform하기 위해, M과 F 간의 matrix multiplication이 수행되죠. 그 결과는 3-dimensional space( C x H x W )로 다시 reshape 됩니다. 이는 input tensor와 같은 shape이죠. 이를 식으로 표현하면 아래와 같습니다.

channel attention module C ( C x H x W )의 output은 original input feature map B에 이 result를 합치는데요. 이 때 element-wise sume operation을 사용하고 학습가능한 scalar parameter alpha를 가지고 있죠. alpha는 0에서 부터 weight을 점진적으로 학습하죠. 이를 식으로 표현하면 아래와 같습니다.

Eq 6은 각 channel의 final feature가 all chnnels와 original features의 weighted sum이라는 것을 보여주죠. feature mapes 간의 long-range semantic dependencies를 모델링하는 것으로도 볼 수 있죠. 마지막으로 feature map C ( C x H' x W' )는 CFAM module의 output feature map D ( C* x H' x W' )를 생성하기 위해 두 개의 convolutional layer의 input으로 들어갑니다. CFAM module의 시작과 끝에 있는 두 개의 convolutional layers가 가장 중요한데요. 그들은 다른 backbones으로 부터 나와 possibly 다른 분포를 가지는 features를 mix하도록 도와주기 때문이죠.
이런 architecture는 channels 중에 inter-dependencies 라는 관점에서 feature representativeness를 promotes 하죠. 그리고 따라서 다른 branches로 부터의 features는 reasonably 그리고 smoothly aggregated 될 수 있죠. 게다가, Gram matrix은 모든 feature map을 고려하죠. 여기서 두 개의 flattened feature vectors의 dot product는 그들 간의 relation에 대한 information을 나타냅니다. larger product는 이 두 channels 에서 features가 더 correlated라는 것을 나타냅니다. 반면 smaller product는 그들이 서로 다르다는 것을 나타내죠. 주어진 channel에 대해, 저자들은 더 영향력을 끼치고 더 correlated가 된 other channels에 많은 weights를 부여합니다. 이 mechanism의 의미를 통해, contextual relationship은 emphasized 되고 feature discriminability는 향상되죠.
Bounding box regression
저자들은 YOLO의 guidelines를 따랐다고 합니다. bounding box regression을 위해서 말이죠. final convolutional layer는 1x1 kernels를 가지고 있고 output channels의 desired number를 생성하기 위해 적용됐죠. H'xW'에서 각 grid cell에 대해, 5 prior anchors가 YOWO의 final output size를 만들어주는 ( (5 x ( Numcls + 5 )) x H' x W' ) NumCls class conditional action socres, 4 coordinates 그리고 confidence score 를 가진 해당 datasets에서 k-means technique에 의해 선택되죠. bounding boxes의 regression은 이 anchors에 기반해 refined 되죠.
저자들은 224 x 224 resolution을 training과 testing time에 사용한다고 합니다. 다른 resolutions를 가지는 multi-scale training을 적용하는 것은 성능 향상을 볼 수 없었다고 합니다. loss function은 original YOLOv2 network와 유사하다고 하는데요. 다른 점은 localization을 위해 beta=1을 가지는 smooth ㅣ_1 loss를 적용했다고 합니다. 그 loss 는 아래와 같습니다.

여기서 x 와 y는 network prediction과 ground truth를 각각 의미하죠. Smooth L_1 loss는 MSE loss 보다 outliers에 덜 민감합니다. 그리고 몇몇 case에서 exploding gradients를 예방하죠. 저자들은 confidence score를 위해 MSE loss를 적용했습니다. MSE loss는 아래와 같죠
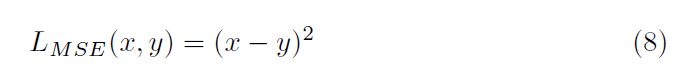
final detection loss는 x, y, width와 height에 대해 개별 coordinate losses의 summation이 됩니다. ( 즉 confidence socre loss입니다 ) 이는 아래와 같죠.

저자들은 focal loss를 classification을 위해 사용하는 데요, 그 식은 아래와 같죠

여기서 x는 softmaxed network prediction 입니다. y 는 ( 0,1 ) 사이의 값이고 ground truth class label입니다. 감마는 modulating factor입니다. 이는 high confidence( i.e. easy samples )를 가지는 samples의 loss를 줄여주죠. 그리고 low confidence ( i.e. hard samples ) 를 가지는 samples의 loss를 늘려줍니다. 그러나, AVA dataset은 multi-label dataset인데요. ava dataset에서는 각 person이 하나의 pose action을 수행합니다. ( i.e. walking, standing, etc ) 그리고 multiple human-human 이나 huuman-object interation action 도 수행하죠. 그럼으로, 저자들은 classes를 pose하기 위해 softmax를 적용하고 interaction actions에 sigmoid를 적용합니다. 게다가, AVA는 unbalanced dataset인데요. modulating factor 감마는 dataset imbalance를 다루기에 충분하지 않습니다. 따라서 저자들은 focal loss의 alhpa-balanced variant 사용합니다. alpha term에 대해, 저자들은 class sample ratios의 exponential을 사용합니다.
YOWO architecture의 optimization에 사용되는 final loss는 detection과 classification loss의 summation인데요. 식으로는 아래와 같습니다.

여기서 람다 0.5가 실험에서 가장 best했다고 합니다.
Implementation details
저자들은 3D와 2D network parameters 각각 initialize 했다고 하는데요: 3D part는 Kinetics에서 pretrained models로 2D part는 PASCAL VOC에서 pretrained models로 initialize 했다고 하네요. 2D-CNN과 3D-CNN branches로 구성되어 있지만, parameters는 함께 updated 된다고 하는데요. 저자들은 mini-batch stochastic gradient decent algoritm을 선택했습니다. loss fuction을 optimize하는 momentum과 weight decay 역시 가지고 있죠. learning rate는 0.0001로 initialized됩니다. 30k, 40k, 50k, 60k iterations 이후에 0.5의 factor로 줄어딥니다. dataset UCF 101-24에 대해, training process 는 5 epochs 후에 completed 됩니다. 반면에 J-HMDB-21은 10 epochs 이후에 completed 되죠. complete architecture는 implemented 되고 single Nvidia Titan XP GPU를 사용하여 PyTorch에서 end-to-end로 학습됩니다.
training 때에, J-HMDB-21의 적은 sample 수 때문에, 저자들은 모든 3D conv network parameters를 freeze했습니다. 따라서 빠르게 수렴하고 over-fitting risk는 줄어들죠. 게다가, 저자들은 training time에 clip에서 flipping images horizontally, random scaling 그리고 sandom spatial cropping와 같은 several data augmentation techniques를 deploy 하죠. testing 동안, threshold 0.25 보다 큰 confidence score를 가진 detected bounding box만이 선택되고 그러고 나서 UCF101-24와 J-HMDB-21 datasets에 대해 threshold 0.4를 가지는 NMS 로 post-processed 됩니다. ( AVA는 0.5 입니다 )
Linking Strategy
저자들은 이미 frame-level action detections를 얻었죠. 다음 step은 UCF101-24와 J-HMDB-21 datasets에 대해 action tube를 construct하는 이 detected bounding boxes를 link하는 것입니다. 저자들은 다른 연구에서 사용한 linking algorithm를 사용합니다
R_t와 R_t+1dms 연속된 frames t와 t+1로부터 나오는 두 개의 regions이라고 가정하고 action class c를 위한 linking score는 아래와 같이 정의됩니다.

S_c(R_t), S_c(R_t+1)은 regions R_t와 R_t+1의 class specific scores입니다. ov는 two regions의 intersection-over-union입니다. 알파와 베타는 scalars입니다. 파이(ov)는 overlap이 존재하면 1로 설정되는 constraint입니다(ov > 0). 그 밖의 파이(ov)는 0입니다. 저자들은 아래의 extra element를 가지고 linking score definition을 확장합니다. extra element는 아래와 같습니다.

이 extra element는 연속된 frames 간의 score의 dramatic changes를 고려하죠. 그리고 실험에서 video detection의 performance를 향상시킬 수 있죠. 모든 linking score가 계산된 후에, Viterbi algorithm은 action tubes를 생성하는 optimal pth를 찾기 위해 deployed 됩니다.
Long-Term Feature Bank
YOWO's inference가 online이고 small clip size를 가지는 causal 하지만, 16-frame input은 action understanding을 위해 필요한 temporal information을 제한하죠. 따라서, 저자들은 long-term feature bank( LFB ) 사용합니다. LFB는 다른 timestamps에서 3D backbone으로 부터 나오는 features를 contains하죠. inference time에, key-frame을 centering하는 3D features는 averaged되죠. resulting feature map은 CFAM block의 input으로 사용됩니다. LFB features는 non-overlapping 8-frame clips로부터 pretrained 3D ResNeXt-101 backbone을 사용하여 추출되는데요. 그래서 64 frames가 inference time에 사용되죠. LFB의 사용은 action classification performance를 증가시킵니다. clip accuracy와 video accuracy간의 차이와 유사하죠. 그러나, LFB의 도입은 resulting architecture가 non-causal하게 만듭니다. 3D features가 inference time에 사용되기 때문이죠.
역시나 실험 부분은 생략하도록할게요
3D conv를 대체할 방법을 찾아봐야겠네요..
이게 쉽지가 않은데 하 오늘은 여기까지 하겠습니다.



