저번 글에 이어 리뷰하도록 할게요
저번 글이 기억나시 않으시면
아래 글을 참조해주세요
[꼼꼼하게 논문 읽기]FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking 1 ( 2021 )
안녕하세요. 얼마 전에 review 했던 논문이 있죠? 2022.07.08 - [AI 논문] - [ 꼼꼼하게 논문 읽기 ] Towards Real-Time Multi-Object Tracking [ 꼼꼼하게 논문 읽기 ] Towards Real-Time Multi-Object Trackin..
developer-wh.tistory.com
Unfariness Issues in On-shot Trackers
이 section에서는, 저자들은 three unfariness issues 에 대해 논의한다고 합니다. 이 issues는 tracking performances의 degrade를 야기하죠. 이 issues은 existing one-shot trackers에서 발생하죠.
Unfairness Caused by Anchor
existing one-shot trackers ( Track R-CNN and JDE )는 대게 anchor-based 인데요. YOLO나 Mask R-CNN과 같은 anchor-based object detectros로 부터 directly modified 했기 때문이죠. 그러나, 저자들은 anchor-based design은 re-ID ㄹfeatures를 학습하기에 적합하지 않다는 것을 발견했답니다. good detection results에도 불구하고 ID switches가 많이 발생하기 때문이죠. 저자들은 이 problem을 3 가지 관점으로 설명합니다
Overlooked re-ID task
Track R-CNN 은 cascade style로 operate하는 데요. 먼저 object proposals( boxes )를 estimates 합니다. 그리고 나서 해당 re-ID features를 estimate하기 위해 object proposals로부터 features를 pools 합니다. training 동안 re-ID features의 quality는 proposals의 quality에 heavily 의존합니다. ( re-ID feature는 proposals 가 정확하지 않다면 쓸모가 없죠 ) 결과적으로, training stage에서 model은 high quality re-ID features보다 accurate object proposals 을 estimate 하는데 baised 되죠. 그래서 existing one-shot trackers의 표준 " detection first, re-ID secondary " design은 re-ID network가 fairly learned 되지 못하도록 하죠
One anchor corresponds to multiple identities
anchor-based methods는 proposals로부터 features를 extract하기 위해 ROI-Align을 사용합니다. ROI-Align에서 Most sampling locations는 distrubing instances에 속하거나, background에 속할 수 있죠. Figure 2에서 볼수 있다시피 말이죠. 아래 그림에서 확인해보죠

결과적으로 extractied features는 target objects representing 의 관점에서 optimal하지 않은데요. 대신에, 저자들은 이 연구에서 estimated object center과 같은 single point에서 features를 extract하죠.
Multiple anchors correspond to one identity
different image patches에 관한 multiple adjacent anchors는 그들의 IOU가 sufficiently 커질때 까지 same identity를 estimate하도록 강요받는데요. 이것은 training에 대해 severe ambiguity를 야기합니다. Figure 2에 설명이 되어 있지요. 반면에 image가 매우 작은 변화를 격게되면, ( i.e. due to data augmentation ) 같은 anchor는 different identities를 추정하도록 강요받을 수 있죠. 게다가 object detection에서 feature map은 accuracy와 speed를 balance 하기 위해서 대게 down-sampled 되죠 ( 8/16/32 배로 ) 이것은 object detection에 대해 acceptable 하지만 re-ID features learning에 대해서는 too coarse합니다. 왜냐하면 coarse anchors에서 extracted된 features는 object center를 가지고 aligned 되지 못할 수도 있기 때문이죠.
Unfairness Caused by Features
one-shot trackers에서, most features는 object detection과 re-ID task 간에 공유되는 데요. 그러지만 그들이 사실은 best result를 achieve 하기 위해 different layter를 require 한다는 것은 잘 알려진 사실이죠. 특히, object detection은 object class와 positions를 estimate하기 위해 deep features 가 필요하죠. 그러나 re-ID는 same class의 different instances 구별을 위해 low-level appearance features가 요구되죠. 이런 multi-task loss optimization 관점으로부터, detection과 re-ID의 optimization objectives가 conflict를 겪죠. 따라서, two tasks의 loss optimization strategy의 balance하는 것은 중요하죠.
Unfairness Caused by Feature Dimension
previdous re-ID 연구들은 high dimensional features를 학습했습니다. 그리고 pomising results 를 달성했죠. 그러나 저자들은 lower-dimensional features를 학습하는 것이 one-shot MOT 를 위해서는 더 좋다는 사실을 발견했는데요. 3 가지 이유를 들고 있죠. (1) high-dimensional re-ID features는 object detection accuracy에 좋지 않은데요. final tracking acuuracy에 negative inpact를 끼치는 two tasks의 competition 때문이죠. object detection에서 feature dimension은 대게 very low 하다는것을 고려하면, 저자들은 two task를 balance하기 위해 low-dimensional re-ID featrues 를 학습할 것을 제안합니다. MOT task는 consecutive frames 간의 one-to-one matching을 수행하죠. re-ID task는 query를 large numbers of candidates에 match 할 필요가 있습니다. 때문에 더 discriminative 하고 high-dimensional 한 features가 요구되죠. 그런데 MOT 에서 ( performing small number of one-to-one matching ) high-dimensional features가 필요없죠. ( 3 ) low dimensional re-ID feautres를 학습하는 것은 inference speed를 향상시킬 수 있습니다.
FairMOT
이 section에서, 저자들은 FairMOT의 technical details를 보여줍니다. backbone network, object detection branch, re-ID branch 뿐만 아니라 training details까지 포함해서 말이죠.
Backbone Network
저자들은 ResNet-34를 backbone으로 사용합니다. 이는 accuracy 와 speed 간의 a good balance를 맞추기 위함이죠.
Deep Layer Aggregation ( DLA ) enhanced version은 multi-layer features를 합친 backbone을 사용합니다. Figure 1에서 보여지는 것처럼 말이죠. original DLA와 다르게, 이 version은 FPN( Feature pyramid network ) 과 유사하게 low-level과 high-level features간 의 더 많은 skip connections 이 있습니다. 게다가, all up-sampling modules에서 convolution layers는 deformable convolution 에 의해 대체됩니다. 이 convolution layers는 object scales와 poses에 따라 receptive field에 dynamically adjust 될 수 있죠. 이 modifications는 alignment issue를 alleviate하는데 도움이 됩니다. resulting model은 DLA-34라는 이름으로 불립니다. input images의 size는 H_image X W_image로 표기합니다. output feature map은 C x H x W 의 shape을 가집니다. 여기서 H = H_image/4 이고 W = W_image/4 입니다. DLA 더불어, multi-scale convolution features 제공하는 다른 deep network ( HRNet ) detection 과 re-ID에 대해 fair feature을 제공하기 위해 저자들의 framework에 사용됩니다.
Detection Branch
저자들의 detection branch는 top of CenterNet 위에 설계되었죠. 그렇지만 다른 anchor-free methods 에도 사용될 수 있습니다. 저자들은 이 작업을 자체적으로 포함되도록 만드는 이 approach를 설명합니다. 특히, heatmaps, object center offsets 그리고 bounding box sizes를 가각 를 추정하기 위해 DLA-34에 3 개의 parallel heads가 첨가됩니다. 각 head는 3x3 convolution( with 256 channels )를 DLA-34의 output feature에 적용함으로써 구현되는되요. 뒤이어 final targets를 생성하는 1x1 convolutional 가 나오죠.
Heatmap Head
이 head는 object centers의 locations를 estimationg하는데 합리적입니다. representation에 기반한 heatmap 은, landmark point estimation task에 대한 사실상 ( de facto ) standard 인데요, 여기 적용됩니다. 특별히 heatmap의 dimension은 1 x H x W입니다. heatmap에서 location에 response는 하나로 expected 되는데는 ground-truth object center과 함께 collapses 될 경우에 말이죠. 이 response 는 hetmap location과 object center 간의 distance로써 exponentially decay하죠.
image에서 각 GT box는 아래와 같이 표현됩니다.

object center의 표기와 계산은 각각 아래와 같고요.

feature map에 대한 location은 stride로 나누어 얻어질 수 있죠. 식으로는 아래와 같습니다.

그러면 location (x, y)에서 heatmap response는 아래와 같이 계산됩니다.

여기서 N은 number of objects를 말합니다. 시그마_c는 standard deviation을 나타냅니다. loss function은 focal loss를 가진 pixel-wise logistic regression 입니다. 즉 식은 아래와 같죠.

hat M은 estimated heatmap입니다. 알파와 베타는 focal loss에서의 predetermined parameters 죠
Box Offset and Size Heads
box offset head 는 objects를 더 정확하게 localize를 목적으로 하는데요. final feature map의 stride 가 4 이기 때문에, quantization error가 4 pixcel 까지 발생할 수 있습니다. 이 branch는 each pixel에 대해 object center에 상대적인 continuos offset을 estimate합니다. 이는 down-sampling의 impact를 mitigate하기 위함이죠. box size head는 target box의 height 와 width 각 location에서 estimating하기 적합합니다.
size와 offset heads의 output을 hat S 와 hat O 라하면 범위는 아래와 같습니다

각 GT box는 아래와 같겠죠
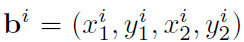
size는 S로 표기합니다. 그리고 식은 아래와 같죠

GT ofsset은 다음과 같이 계산됩니다.

해당 location에서 estimated된 size와 offset은 hat S와 hat O로 표기합니다. 저자들은 l_1 loss를 2 head에 대해 보완했는데 아래와 같습니다.

람다_s는 weighting parameter이고 0.1로 set합니다
Re-ID Branch
Re-ID branch를 objects를 구별할 수 있는 features를 generate 하는것을 목표로 하는데요. 이상적으로, different objects 중에서 affinity는 same objects 간의 affinity 보다 작아야 하는데요. 이 goals를 이루기 위해, re-ID features를 각 localtion 별로 extract하기 위해 128 kernels를 가진 convolution layer를 backbone features에 적용한다고 하네요. resulting feature map 은 E라고 쓰고 아래와 같죠.

( x, y )에서 cetered object의 re-ID feature E_x,y 는 이 feature map으로 부터 추출될 수 있죠.
Re-ID Loss
classification task를 통해 re-ID featrues를 학습하는데요. training set에서 same identity의 All object instances는 same class로 다뤄지죠. 각 GT box 에 대해, heatmap에서 object center를 얻습니다. re-ID vector를 추출하고 fully connected layer와 softmax operation 을 사용합니다. 이는 re-ID vector를 class distribution vector P에 매핑하기 위함이죠. GT class label 의 one-hot representation을 L (k) 라고 표기하는 데요. 저자들은 re-ID loss를 아래와 같이 계산합니다.

여기서 K는 training data에서 number of identities입니다. network의 training process 동안, object centers에 located된 identity embedding vectors 만이 trainin을 위해 사용됩니다. 왜냐하면 저자들은 objectness heatmap 으로부터 object center를 얻을 수 있기 때문이죠.
Training FairMOT
저자들은 detection과 re-ID branches를 losses를 추가함으로써 동시에 train 하는데요. 식으로 나타내면 아래와 같죠

저자들은 uncertainty loss 를 사용합니다. 이는 detection과 re-ID task를 자동적으로 balance하기 위함이죠. 위의 식에서 w_1과 w_2는 learnable parameter입니다. two task의 balance해주죠. 특히, few object와 해당 ID가 있는 image가 주어지면, heatmaps, box off-set and size maps 뿐만 아니라 objects의 one-hot class representation 을 생성합니다. 이것들은 whole network를 train한 losses를 obtain하기 위해 estimated measures와 비교됩니다.
게다가 standard training strategy 에서는, COCO 와 CrowdHuman 같은 image-level object detection dataset에 대해 FairMOT를 train하는 single image training method를 제안하는데요. input으로 consecutive frames를 넣는 CenterTrack과 다르게, 저자들은 single image를 input으로 넣습니다. 저자들은 each bounding box와 unique identity 를 각각 할당합니다. 그리고 dataset에서 separate class로서 각 object instance를 고려합니다. 저자들은 HSV augmentation, rotation, scaling, translation 과 shearing을 포함하는 different transformations를 whole image에 적용하는데요, single image training method는 상당한 empirical value를 가집니다. 먼저, CrowdHuman dataset에 대해 pre-trained model은 tracker 로 직접 사용될 수 있습니다. 또한 MOT dataset에서 acceptable result를 얻을 수 있습니다. 왜냐하면 CrowdHuman dataset은 human detection performance를 boost할 수 있고, strong domain generalizaition ability를 가지고 있기 때문이죠. re-ID features 의 training은 tracker의 association abillity를 강화합니다. 두번 째, 저자들은 다른 MOT dataset에 대해 위 모델을 finetune 할 수 있고 나아가 final performance를 향상시킬 수 있죠.
Online Inference
이번 section에서 저자들은 online inference를 수행하는 방법을 보여줍니다. 그리고 특별히, detections와 re-ID features가 association을 수행하는 방법도 보여줍니다.
Network Inference
1088 x 608 size의 frame이 input으로 들어가는데요. 이는 JDE 와 같죠. predicted heatmap 위에서, 저자들은 peak keypoint를 추출하기 위해 NMS 를 수행합니다. 기준은 heat map score 입니다. NMS는 3 x 3 max pooling operation에 의해 구현됩니다. heatmap scores 가 threshold 보다 큰 keypoint의 locations는 유지됩니다. 그러고 난 다음, 저자들은 해당 bounding boxes를 계산합니다. estimated offsets와 box sizes에 기반해서 말이죠. 저자들은 identity embeddings를 estimated object centers에서 추출합니다. 다음 section에서, 저자들은 re-ID features를 사용해 detected boxes에 associate 하는 지에 대해 설명합니다.
Online Association
저자들은 MOTDT를 따르고 hierarchical online data association method를 사용했는데요. 저자들은 먼저, tracklets의 number를 초기화합니다. 처음 frame에서 detected boxes에 기반해서 말이죠. 그런 다음 따라 오는 frame에서, 저자들은 detected boxes를 existing tracklets에 연결합니다. 이 때, two-stage matching strategy를 사용하죠. first stage에서, 저자들은 initial tracking result를 얻기 위해 Kalman Filter와 re-ID features 사용합니다. 구체적으로, tracklet의 locations를 예측하기 위해 kalmanfilter를 사용합니다. predicted 와 detected boxes 간의 mahalanobis distance를 계산합니다. 저자들은 mahalnobis distance 에 re-ID features에 대해 계산된 cosine distance를 합칩니다. 그러면 distance는 아래와 같죠.

람다 는 weighting parameter고 0.98로 set합니다. JDE를 따라서, 저자들은 large motion을 가지는 getting trajectories를 avoid 하기 위해 threshold 보다 크다면 mahalnobis distance를 infinity로 set합니다. 저자들은 matching threshold = 0.4를 가지고 처음 매칭을 완수하기 위해 hungarian algorithm을 사용합니다.
두 번째 단계에서, unmatched detections와 tracklets에 대해 저자들은 boxes 간의 overlap에 따라 match를 시도합니다. 자세히 말하면, matching threshold 0.5로 set합니다. 저자들은 tracklet의 appearance feature를 각 step에서 update합니다. 이는 appearance variations를 다루기 위해서죠. 마지막으로 저자들은 unmatched detections를 new tracks로 초기화합니다. unmatched tracklet은 30 frame 동안 저장됩니다. 이 경우 후에 다시 나타나게 되죠.
이번 논문은 여기까지 리뷰할게요
밑의 실험 내용은 생략합니다 ㅎㅎ



