안녕하세요. 얼마 전에 review 했던 논문이 있죠?
2022.07.08 - [AI 논문] - [ 꼼꼼하게 논문 읽기 ] Towards Real-Time Multi-Object Tracking
[ 꼼꼼하게 논문 읽기 ] Towards Real-Time Multi-Object Tracking
안녕하세요 WH입니다 오늘은 2019 년도에 나온 논문을 리뷰해볼 생각입니다. 시작하기에 앞서 MOTR 성능이 생각보다 좋더라구요 몇몇을 조금만 건들면 tracking에서는 매우 좋아보였어요 이게 논문
developer-wh.tistory.com
이 논문의 JDE를 활용해
SOTA를 달성한 논문이 바로 이 논문인데요.
리뷰 시작하겠습니다.
Abstract
MOT는 넒은 범위의 활용을 가진 computer vision에 있어서 중요한 문제인데요. MOT를 single network에서 object detection과 re-ID의 multi-task learning으로 formulating 하는 것은 매력적입니다. two task의 joint optimization을 가능하게 해주기 때문이죠. 물론 high computation efficiency 도 말이죠. 그러나, 저자들은 two task 신중하게 다뤄야 할 필요 각 task가 서로 경쟁하는 경향이 있다는 사실을 알게되었다고 해요. 특별히, 이전 연구는 대게 re-ID를 accuracy는 primary detection task에 의해 크게 영향을 받는 secondary task로써 다뤘는데요. 결과적으로, network는 primary detection task에 baised 되는데, 즉 primary task는 re-ID task에 fair 하지 않다고 하네요. 이 문제를 해결하기 위해, 저자들은 FairMOT라 칭한 간단하고 효과적인 approach를 제안하는데요. anchor free object detection architecture CenterNet에 기반했다고 하네요. 그런데 단순히 CenterNet과 re-ID를 합친 것이 아니라고합니다. 대신에, 저자들은 emprical studies를 통해 good tracking results를 achieve하는 데 중요한 detailed designs의 bunch를 제안한다고 합니다. 그래서 SOTA를 달성했다고 말하고 있네요.
Introduction
MOT는 computer vision에서 longstanding goal 이어왔죠. goal은 videos 에 존재하는 interest의 object에 대한 trajectories를 추정하는 것이죠. problem의 successful resolution은 intelligent video analysis, human computer interaction, human activity recognition과 같은 많은 분야에 즉각적으로 도움이 될 수 있죠.
많은 existing methods는 two separate models에 의해 이 문제를 다루고자 했죠. 먼저 detection model이 bounding box로 intrest의 objects를 detect하고 그러고 나서, associaiton model이 해당 bounding box에서 image region으로 부터 re-identification features를 추출하고 detection을 existing track에 연결하거나 feautre에서 정의된 어떤 metrics에 따라 new track을 생성하죠.
object detection과 re-ID( 최근에 독립적으로 overall tracking acuuracy를 boost한 ) 에 대한 놀랄만한 progress가 있었습니다. 그러나, 이 two-step methods는 scalability issues로 고통받았죠. 이 방법들은 real-time inference speed를 달성할 수 없었습니다.( 많은 수의 objects가 있는 환경에서 ) 왜냐하면 two models는 feature를 공유하지 않고, 비디오에서 모든 bounding box에 대해 re-ID model을 적용해야했기 때문이죠.
multi-task learning의 maturity와 함께, single network를 사용해서 objects를 추정하고 re-ID features를 학습하는 one-shot trackers는 더 많은 주목을 받기 시작했죠. 예를 들자면, Voigtlaender 의 연구가 있겠죠. 이 연구에서는 each proposal 에 대해 re-ID feature를 추출하기 위해 re-ID branch를 Mask R-CNN에 추가했죠. 이 branch는 re-ID network에 대해 backbone features를 재 사용함으로써 inference time을 줄였습니다. 그렇지만, performance는 two-step method와 비교해서 놀랄만큼 떨어졌습니다. 사실, detection accuracy는 여전히 좋았지만 tracking performance가 많이 떨어졌는데요. 구체적으로, ID switches의 numbers가 엄청나게 많아졌습니다. 이 결과는 두 task를 합치는 일이 사소한 문제가 아니라 매우 신중하게 다뤄져야하는 문제라는 점을 시사하죠.
이 논문에서, 저자들은 실패에 대한 이유를 조사했고 간단하지만 효과적인 solution을 제안합니다. 이 실패를 설명하는 3 가지 요소가 확인되었다고 합니다. 처음 issue는 anchor에 의해 발생했습니다. Anchor는 object dection을 위해서 design되었죠. 그런데 저자들은 anchor가 re-ID features 추출하는 데에 적합하지 않다는 것을 2가지 이유를 들어 설명합니다. 먼저, anchor-based one-shot trackers는 re-ID task를 간과했습니다. 왜냐하면 object detect하는 anchor가 필요( i.e. RPN에 사용되죠 ) 하고 그러고 난 다음 re-ID features를 detection result에 기반해 추출하기 때문( re-ID features는 detection result가 올바르지 않으면 쓸모없습니다 ) 이죠. 그래서 두 task 간의 competetion이 발생할 때, detection task를 더 우선시하죠. Anchors는 re-ID features를 training하는 동안 많은 ambiguity를 발생시킵니다. 왜냐하면 하나의 anchor가 multiple identies와 연관될 수 있고, 여러 개의 acnhor가 하나의 identities에 연관될 수 있기 때문이죠. 이런 현상은 특히나 crowded scence에서 많이 발생합니다.
두 번째 문제는 두 task간 공유하는 feature에 의해 발생하는 데요. Detection task와 re-ID task는 완전히 다른 두 개의 task이죠. 그리고 두 task는 다른 features가 필요합니다. 일반적으로, re-ID features는 same class의 different instances를 구별하기 위해 더 low-level features를 필요로 합니다. 반면 detection features는 differecnt instances에 대해 유사한 features를 필요로 하죠. one-shot trackers에서 shared features는 feature conflict를 야기하죠. 때문에 각 task의 performance를 감소시킵니다.
세 번째 문제는 feature dimension에 의해 발생합니다. re-ID features의 dimension은 보통 512 정도로 높아야하는 데요. 이는 object detection의 featrues의 dimension보다 훨씬 크죠. 저자들은 dimension 간의 엄청난 차이가 two task의 performance에 좋지 못하다는 것을 발견했습니다. 더 중요하게, 저자들의 실험은 "joint detection and re-ID" network를 위한 low-dimensional re-ID features를 학습하는 것이 높은 tracking accuracy와 efficiency 도달할 수 있음을 보여줍니다. 이것은 또한 MOT task와 re-IDtask 간의 차이를 증명합니다. MOT의 field에서 간과했던 부분이기도 하죠.
이 연구에서, 저자들은 simple approach를 제안하는데요. FairMOT라 칭합니다. 3 가지 issues를 다룬 approach죠. 이는 Figure 1에 설명되어 있습니다. 아래 그림을 보시죠
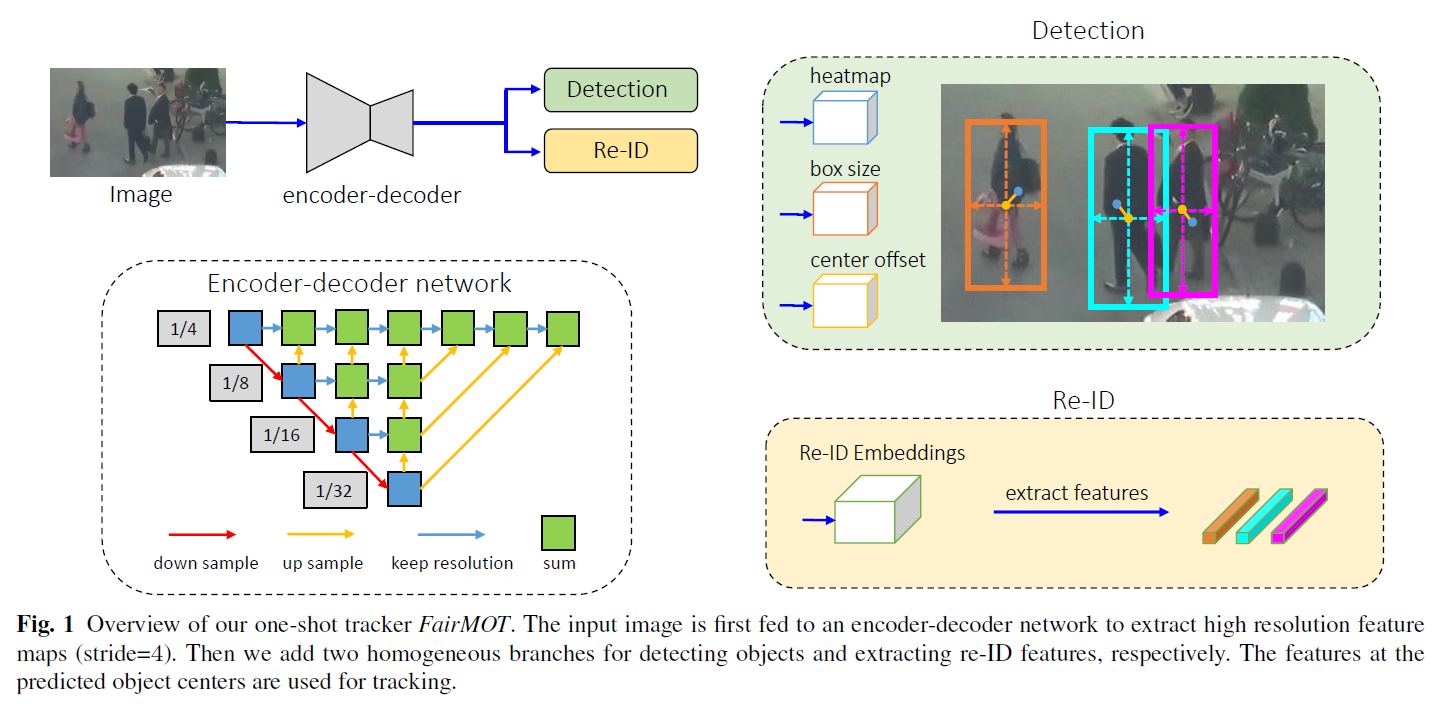
FairMOT 는 CenterNet 위에서 설계 되었습니다. 특히, detection과 re-ID task는 FairMOT에서 동등하게 다뤄지죠. 이것은 "detection first, re-ID secondary" framework 과는 본질적으로 다르죠. FariMOT가 단순히 CenterNetrhk re-ID를 합친것이 아니라 것은 충분히 언급할 만한 가치가 있죠. 대신에 저자들은 empirical studies를 통해 좋은 tracking results에 도달하는 데 중요한 detailed desings의 bunch를 제안합니다.
Figure 1은 FiarMOT의 overview인데요. 간단한 network structure를 가지죠. 이는 두 개의 homogeneous brances를 가지는 데, 이 branches는 각각 object를 detect하고, re-ID features를 추출하죠. 기존 연구들에 영감을 받아, detection branch는 anchor-free style로 구현되었습니다. anchor-free style은 objects의 position-aware measurement maps로써 represented 된 center와 size를 추정하죠. 유사하게, re-ID branch는 pixel에서 centered object를 characterize하기 위해 각 pixcel에 대해 re-ID feature를 추정하죠. two branches 완전히 homogeneous 한데, 이는 detection과 re-ID 를 two-stage cascaded style 로 수행하던 기존 방법과는 본질적으로 다릅니다. 그래서 FairMOT는 Table 1에서 보여주는 것처럼 detection branch의 unfair disadvantage를 제거하고 효과적으로 high-quality re-ID features를 학습하며 detection과 re-ID 간의 good trade-off를 얻습니다.
( 최고를 달성했고 성능이 어떻다는 부분은 건너뜁니다 ) 이 연구는 MOT에서 detection 과 re-ID 간의 관계를 밝힙니다. 그리고 one-shot video tracking network를 designing 에 대해 gudiance를 제공합니다. 저자들의 contribution은 아래와 같습니다.
1. 저자들은 prevalent acnhor-based one-shot MOT architectures가 간과되어 온 효과적인 re-ID 학습의 관점에서 한계
가 있음을 실험적으로 보여주었습니다. 이 문제는 tracing performacne를 severly 제한하죠.
2. fairness issue를 다룬 FairMOT를 제안합니다. FairMOT는 CenterNet 위에 설계되었습니다. 적용된 techniques가 새
로운 것은 아니지만, 저자들은 MOT에 중요한 새로운 발견을 했는데요. 이 new discoveries는 새로우며 가치가 있죠.
3. 저자들은 achieved fairness 는 FairMOT가 detection과 tracking accuracy의 high level을 얻을 수 있도록 하고, 이전
SOTA methods를 뛰어넘는 결과를 보여줍니다.
Related work
best-performing MOT methods는 tracking-by-detection paradiam을 따릅니다. 이 paradiam은 objects를 각 frame에서 먼저 detect하고 나서 시간에 대해 그들을 associate하죠. 저자들은 기존의 연구들을 두 가지 categories로 분류하는 데요. object를 detect하고 association features를 추출하는 데에 single model을 쓰느냐, 나눠진 모델을 쓰느냐가 기준이죠. 저자들은 이 methods의 장단점에 대해 논의하고 자신들의 approach를 그들과 비교한다고합니다.
Detection and Tracking by Separate Models
Detection Methods
MOT17 과 같은 benchmark datasets는 DPM, Faster R-CNN 그리고 SDP 같은 popular methods에 의해 얻어진 detection results를 제공합니다. tracking part에 초점에 맞춘 그런 연구들은 same object detection에 대해 공정하게 비교될 수 있습니다. 몇몇 연구는 VGG-16을 가진 Faster R-CNN detector를 훈련하기 위해 large private pedestrain detection dataset을 사용합니다. 그리고 소수의 연구는 detection performance를 올리기 위해 더 powerful detector를 사용하죠. 현존하는 많은 연구들은 problem의 tracking part에 초점을 맞춥니다. 저자들은 그 연구들을 two classes로 나눕니다. 기준은 association에 사용한 cue의 type입니다.
Location and Motion Cues based Methods
SORT는 이는 tracklet의 future location을 예측하기 위해 Kalman Filter를 처음 사용하고, detection들로 그들의 overlap을 계산한 뒤, Hungarian algorithm을 사용하여 detections를 tracklet에 할당하죠. IOU-Tracker는 이전 frame의 tracklets과 detections의 overlap을 kalmanfilter 없이 직접 계산합니다. 이 approach는 100k fps inference speed를 달성했죠( detection time은 제외합니다 ) 그리고 object motion이 작을때 잘 작동하죠. SORT 나 IOU-Tracker는 간단해서 실제로 많이 사용되죠.
그러나, 위 두 방법은 crowded scenes 나 fast motion의 challenging case에 대해 실패했죠. 몇몇 연구들은 false negatives를 줄이고 accurate object location을 얻기 위해 sophisticated single object tracking methods 사용합니다. 그러나, 이 방법들은 extremely 느리죠. 특히 scene에 많은 사람들이 있는 경우에 말입니다. trajectory fragments의 problem을 해결하기 위해, Zhang 의 연구는 association에 대해 tracklet의 longrange features를 학습하는 motion evaluation network를 제안합니다. MAT은 enhanced SORT인데요. camera motion을 모델링하고 long-range re-association을 위해 dynamic window를 사용합니다.
Appearance Cues based Methods
몇몇 연구는 detections의 image regions를 crop해서 image features를 추출하는 re-ID networks에 입력으로 줄 것을 제안합니다. 그러면 re-ID networks는 tracklet과 detections의 간의 similarity를 re-ID feature에 기반해 계산합니다. 그리고 Hungarian algorithm을 사용해 assignmetn를 완성합니다. 이 method는 fast motion과 occlusion에 robust한데요. 특별히, 이것은 lost tracks를 re-initialize 할 수 있습니다. 왜냐하면 appearance features는 상대적으로 stable하기 때문이죠.
몇몇 다른 연구가 있는데요. appearace features를 enhancing하는데 초점을 맞췄습니다. 예를 들면 Bae의 연구는 appearance variations를 다루기 위해 online appearance learning method를 제안합니다. Tang의 연구는 appearance feature를 강화하는 body pose features를 사용하죠. 몇몇 methods는 더 reliable similarity을 얻기 위해 multiple cues( i.e. motion, apperance and location )을 합친 것을 제안합니다. MOTDT 는 appearance feature가 reliable하지 않을 때, objects를 associate 하기 위해 IoU를 사용하는 hierarchical data association을 제안합니다. 또한 소수의 연구는 group mdoels와 RNNs 와 같은 좀더 complicated association strategies를 사용합니다.
Offline Methods
offline methods ( or batch methods )는 whole sequence에서 global optimization을 수행함으로써 better results를 달성합니다. 예를 들어, Zhang의 연구는 all frame에서 detections를 representing하는 node르 가진 graphical model을 설계했죠. optimal assignment는 min-cost flow algorithm을 사용하여 찾아집니다. Linear Programming보다 optimum에 더 빠르게 도달하는 graph의 specific structure를 사용합니다. Berclaz 의 연구는 data assocciation을 flow optimization tsak로 다룹니다. 그리고 이 problem을 해결하기 위해 K-shortest paths algorithms 를 사용하죠. computation이 상당히 빨리지고 tuned하는 데 필요한 parameters가 줄어듭니다. Milan의 연구는 multi-object tracking을 continuous energy 의 minimization 으로 공식화합니다. 그리고 energy function을 설계하는 데 초점을 맞추죠. energy는 모든 frames에서 all targets의 locations와 motion에 따라 달라지고 physical constraints에 따라서도 달라집니다. MPNTrack 은 detections의 전체 set의 globla association을 수행하는 graph neural network를 제안합니다. 그리고 MOT를 완전히 differentiable하도록 만들었죠. Lif_T 는 MOT를 lifted disjoint path problem으로 공식화합니다. 그리고 long range temporal interactions를 위한 lifted edges를 소개하죠. 이는 id switches와 re-identify lost를 줄여주죠.
Advantages and Limitations
separate models로 tracking 과 detection을 수행하는 methods에 대해, main advantage는 이 methods는 각 task에 각각 가장 적합한 model를 develop할수 있다는 것이죠. 게다가 detected bounding boxes에 따라 image patches를 crop할 수 있고 re-ID features를 추정하기 전에 그 pathches 들을 same size로 resize 할 수 있습니다. 이 methods는 objects의 scale variations를 다루는데 도움이 됩니다. 결과적으로 이 approaches는 public dataset에서 best performance를 도달해왔습니다. 그러나 그들은 대게 느리죠. 왜냐하면 two task는 sharing 없이 각각 행해져야 했기 때문이죠. 그래서 video rate inference를 하기 어려웠죠.
Detection and Tracking by Single Model
multi-task learning의 maturity와 함께, single network를 사용해서 detection 과 tracking을 joint는 research attention을 attrct하기 시작했습니다. 저자들은 그들을 two classes로 분류합니다.
Joint Detection and Re-ID
methods의 첫번 째 class는 object detection과 re-ID feature extraction을 single network에서 수행합니다. 이는 inference time을 줄이기 위해서죠. 예를 들면, Track-RCNN 은 re-ID head를 Mask R-CNN의 위에 추가했습니다. 그리고 각 proposal에 대해 bounding box를 regresses하고 re-ID feature를 extract하죠. 유사하게 JDE는 YOLOv3 위에 설계되었습니다. video rate inference에 근접했죠. 그렇지만 accuracy가 two-setp tracker에 비해 낮았습니다.
Joint Detection and Motion prediction
methods의 두번 째 class는 detection과 motion feature를 single network에서 학습합니다. D&T 는 Siamese network를 제안합니다. adjacent frames의 input이 주어지고 bounding boxes 간의 inter-frame displacements를 예측합니다. Tracktor는 region proposals identities를 propagate하는 bounding box regression head를 직접 사용합니다. Chained-Tracker은 input으로 adjacent frame을 사용하고 same target을 representing 하는 box pair를 generating하는 end-to-end model을 제안합니다. 이 box-based method는 bounding boxes 는 frame 사이에 large overlap을 가정하죠. 때문에 low frame rate vedio에서는 맞지 않습니다. 이 methods와 다르게, CenterTrack는 pair-wise inpus로 object center dispalcement를 예측합니다. 이 point distaces로 associate하죠. tracklet을 additional point-based heatmap input으로 network에 제공합니다 그리고나서 boxes가 더 이상 no overlap 되지 않아도 match가 될 수 있도록 하죠. 그러나 이 방법들은 adjacent frame에서 objects를 associate하죠. 물론 lost track을 re-initializing 하지 않아요. 따라서 occlusion case를 다루기 힘들죠
저자들은 연구는 첫번 째 class에 속합니다. 저자들은 one-shot trackers가 association performacne가 저하되는 이유에 대해 조사했죠. 그리고 이 문제를 해결하기 위해 simple approach를 제안하죠. 저자들은 tracking accuracy는 엄청난 engineering efforts 없이 상당히 개선되었다는 것을 보여줍니다. CSTrack은 features의 관점에서 two task의 conflicts를 alleviate하는 것을 목표로 하죠. 그리고 task-dependent representations를 학습하는 모델을 이용하는 cross-correlation network module을 제안합니다. CSTrack과는 다르게, 저자들의 method는 이 problem을 three perspectives 로부터 systemic way로 다룹니다. 그리고 CSTrack보다 좋은 performance 얻었다고 합니다. CenterTrack은 appearance features 를 추출하지 않습니다. 단지 인접한 frames에서 objects를 연결합니다. 반면에, FairMOT는 long-range associaiton 을 appearance feature를 활용해 수행합니다. 그리고 occlsion case에 대해 다루죠
Multi-task Learning
multi-task learning은 object detection과 re-ID feature extraction tasks를 balance 하는데 사용되는데요. 수 많은 연구가 있죠. Uncertainty는 task-dependent uncertainty를 사용하는데요. single-task losses를 자동적으로 balance하죠. MGDA 는 18년 Sener and Koltun의 연구에서 제안되었는데요. task-specific gradients 중에서 common direction을 찾는 방식으로 shared network wieghts를 update하죠. GradNorm은 multi-task networks의 training을 control하는 데요. task-sepcific gradients가 similar magnitude 되도록 simulate하죠.
Video Object Detection
Video Object Detection은 MOT와 관련이 되어 있는데, VOD 역시 object detection의 performance를 challenging frame에서 향상시기위해 tracking을 사용하죠. 이 methods들이 MOT dataset에서 평가되지는 않았지만, idea의 몇몇은 MOT 분야에 valuable하죠. 그래서 저자들은 VOD에 대해 이 section에서 간단하게 review하는데요. Tang은 videos에서 object tube를 detect하죠. 이는 challenging frames에서 classification score를 enhance하는 것을 목표로 하고요. small objects에 대한 detection rate이 benchmark dataset에서 큰 폭으로 증가했죠. similar ideas는 타 연구들에도 사용되었습니다. 이 tube-based method의 주요한 limitation은 비디오에 많은 객체가 있다면 extremely slow하다는 것이죠
이번 글을 여기서 마칠게요
다음 글에서 이어서 리뷰하도록하겠습니다.



