매일 그냥 리뷰만 했지만, 오늘은 날도 흐릿하고 간만에 시간이 좀 남기도 하고 해서 이렇게 써보네요. 2d keleton based action recognition의 장점은 배경에 robust하다는 것이죠. 그치만 한 가지 치명적인 단점 역시 포함합니다. 많은 논문에서 밝히고 있지는 않지만, 사실 공간적 정보가 결여 된다는 것이 치명적이죠. 그럼 간단하게 3d를 쓰면 되지 않나요? 맞아요 근데 그건 embedded 에서 realtime으로 구현하기에 연산량이 너무 많죠. 그래서 이번 논문을 리뷰하는 건데요. 얻어갈 아이디어는 공간적 정보를 어떻게 담냐는 거에요. 그 가능성에 대해서 아이디어만 얻어가도 큰 도움이 되겠죠. 여튼 아래 보시죠.
Abstract
voxel-based methods가 multi-person 3D pose estimation에 대해 여러 카메라로부터의 보장된 결과를 보여줘왔지만, computation burdens로부터 항상 고통받아왔죠. 특이 large scenes에서 말이죠. 저자들은 Faster voxelPose를 제안하는데 이는 reature volume을 세 개의 2-dimensional coordinate planes로 re-projecting하고 x,y,z coordinates를 각각 추정함으로써 해당 문제를 해결하죠. 저자들은 먼저 각 person을 localize 하는데 이때 3D bounding box를 사용합니다. 해당 3D bounding box는 xy-plane과 z-axis로 projected된 volume features에 기반해 2D box와 heights를 가지고 추정하고요. 그런 다음, 각 person에 대해, 저자들은 3 개의 coordinate planes로부터 partial joint coordinates를 추정합니다. 그런다음 3D pose를 얻기 위해 fused 되죠. 이 방법은 3D-CNNs로부터 free 하고 VoxelPose의 speed를 10배 개선하죠. 물론 accuracy는 SOTA methods에 비할만하고 real-time application에 잠재성을 보여줍니다.
Introduction
RGB images로부터 3D human pose를 Estimating하는 것은 computer vision에서 근본적인 문제가 있죠. action recognition과 같은 important downstream tasks를 위한 기반이 될 뿐만 아니라 많은 applications를 가능하게 하죠.
많은 연구가 monocular 3D pose estimation을 다뤘지만, 그들의 application은 serious scenarios에서 제한이 있죠. 이는 accuracy 감소 때문이기도 하고요. 게다가, monocular human pose estimation은 occlusion이 발생할때 더욱 어려움을 겪죠. 결과적으로, SOTA 3D human pose estimation results는 대게 multi-camera systems로부터 얻어집니다.
Simple triangulation은 accurate 3D pose estimates를 달성할 수 있는데, 2D pose가 모든 view에서 정확해야한다는 조건이 붙죠. 그러나, 2D pose estimates는 occlusion 이 발생하면 error를 가지게 되죠. 이문제를 해결하기 위해, voxel-based methods는 2D features나 heatmaps를 3D space에서 를 inversely하게 project하고 multi-view features로 fuse하도록 제안되었죠. 결과로 나온 feature volume은 occlusion에 robust하죠. 그런다음 그들은 3D-CNN을 3D positions의 body joints를 estimate하기 위해 사용하죠. 이 방법이 매우 정확한 result가 나오지만 computation complexity가 cubically하게 증가하죠. 결과적으로, real-time inference를 지원할 수 없죠.
이 연구에서, 저자들은 Faster voxelPose를 제안하는데 VoxelPose보다 10배가량 빠르죠. 3D object가 3개의 2D orthographic projections로 분명하게 represented 된다는 technical drawing에 영감을 받아, 저자들은 fused 3D volumetric features를 세 개의 2D coordinate planes로 re-project합니다. 그런 다음, 각 2D plances로부터 3D pose의 partial coordinates를 추정하죠. 그런 다음 xyz를 predict하는 tiny network로 fused 되죠. 이 method의 이점은 3D-CNNs를 2D-CNNs로 대체할 수있다는 것이죠. 그러나 factorization은 2가지 새로운 문제를 야기합니다. 먼저, 3D space에서 멀어진 사람은 some planes 에 re-projection이후 overlap 될 수 있죠. 이는 corresponding features에 심각한 ambiguity를 야기할 수 있죠. 두번 째, estimation results는 inconsistent 할 텐데 contradictory predictions로 aggregate할 strategy가 필요하죠.
저자들은 이 2가지 문제를 다룹니다. 먼저, Fig1에서 보여주듯 Human Detection Networks를 제안하는데 이는 tight 3D box를 estimate합니다. 이 boxes는 features의 other people를 filter out하는데 사용되죠. 반면에, VoxelPose는 loose fixed-size 3D bounding box를 사용하죠. 구체적으로, 저자들은 3D feature volume을 xy plane으로 z axis를 따라 max-pooling하여 re-project 합니다. 그리고 xy plane에서 2D box로 사람들을 localize하는 2D-CNN을 적용하죠. 그런다음, 각 bounding box에 대해, 저자들은 1D "column" feature representation을 얻습니다. 이는 z axis를 따라 box center에서 volume으로 부터 얻어지죠. 그리고나서 1D-CNN을 적용하는데 이는 box center의 vertical postion을 추정합니다.
그런다음 저자들은 joint localization network를 제안하는데 이는 3D pose를 각 3D box에 대해 추정하죠. 저자들은 먼저 volume에서 features를 mask out합니다. 이는 other people의 영향을 감소시키는 outside box를 가리는 것이죠. 이로써 person-specific feature volume을 얻게됩니다. 저자들은 masked volume을 세 개의 coordinate planes로 re-project하고 X, Y, Z coordinate를 추정합니다. 각 coordinate에 대해, 2 개의 plane으로부터 2 개의 predictions를 가지게 되죠. 두 개의 predictions는 contradictory 할 수 있기에 fusion network를 제안하고 이는 각 prediction을 위한 weight를 학습하여 final 3D pose를 위해 2 predictions를 aggregate합니다.
2 Related Work
2.1 Multi-view 3D Pose Estimation
single-person case에 대해 key는 2D pose estimation error를 다루는 것이죠. Iskakov 연구는 differentiable triangulation을 설계했죠. 이는 joint detection condfidence를 각 camera view에 대해 사용하는데, optimal triangulation weights를 학습하죠. Pavlakos의 연구는 3D PSM을 활용하여 CNN을 적용합니다. Qiu 연구는 epipolar lines를 사용하는데 해당 lines는 cross-view feature fusion를 guide 하죠. Epipolar transformer는 dynamic cameras를 다루도록 확장하여 연구합니다. 일반적으로 말해서, single-person 3D pose estimation은 만족할만한 결과를 달성했죠. 물론 이는 every body joint가 적어도 2개의 cameras로부터 보여지도록 보장될때라는 조건이 붙지만요.
Multi-person 3D human pose esitmation은 더 challenging하죠. 왜냐하면 이는 추가적인 2가지 sub-task를 더 해결해야하기 때문이죠. 1) different view에서 joint-to-person association을 identifying 하는 것. 2) crowd 중에 mutual occlusions를 Handling하는 것이죠. 첫 번째 문제를 다루기 위해, 다양한 association strategies가 제안되었고 이들은 re-id features, dynamic matcing, 4D graph cut 그리고 plane sweep stereo에 관한 것이었죠. 그러나, crowded scenes에서 noisy 한 2D pose estimates는 그들의 accuracy에 악영향을 끼치죠. 2 번째 문제를 다루기 위해 , Belagiannis연구는 PSM을 확장하는 multiperson을 위한 PSM으로 확장하죠. Wang의 연구는 transformer-based direct regression model을 제안하는데 이는 projective attention을 활용하고요.
최근, voxel-based methods가 제안되었고 이는 각 camera view에서 decisions를 making하는 것을 피하기 위해 제안되었죠. 대신, 그들은 multi-view features를 3D space 에서 합치고, 그곳에서 decision 하죠. 이런 방법은 camera views의 pair-wise reasoning으로 부터 자유롭습니다. 그러나, computation-intensive 3D convolutions는 이 방법이 real-time이 가능하도록하는 것을 방해하죠. 저자들은 volumetric feature aggregation의 benefit을 활용합니다. 그러면서도 상당히 빠른 방법이죠.
2.2 Efficient Human Pose Estimation
efficient human pose estimators를 설계하는 것은 intensibely하게 실활용을 위해 연구되죠, image로부터 2D pose를 extracting 하는 것에 대해, SOTA methods는 real-time inference speed를 달성했죠. multiview 3D pose estimation의 측면에서는, Bultman의 연구는 efficient system을 사용하는데 이는 edge sensor를 사용하죠. Remelli의 연구와 Fabbri의 연구는 encoder-decoder networks를 적용하는데 이는 computation을 줄이죠. 그러나 그들 모두, multi-person setting에 적용될수는 없죠. 최근, Lin 과 Wang의 연구는 alternative solutions을 제안하는데 volumetric methods 죠.그럼에도 불구하고, 이들 방법은 scalability의 관점에서 제한이되죠. 이는 large scenes에 depolyed 되는 것을 막죠. 저자들의 방법은 SOTA lightweight 2D pose estimators에 견줄만하며, volumetric methods의 speed를 향상시키죠.
3 Method
3.1 overview
loss의 generality 없이, 저자들은 motivation을 simple case에 대해 설명하는데, 오직 한 사람만이 있는 경우이죠. Fig 2 (A) 에서 보여지는 바와 같이, input은 3D feature volume V ( R^K x L x W x H )인데 이는 multiple cameras에서 2D pose heatmaps를 3D voxel space로 back-projecting 에 의해 만들어지죠.

2D pose heatmaps는 images 로 부터 추출되는데 off-the-shelf pose estimation model을 활용하죠. LxWxH 는 space를 이산화하는 voxels의 수를 represents 하고, K는 joint types의 number를 represents 합니다. volume은 body joints의 per-vxel likelihood를 encodes 합니다.
Fig.2 (A)에서는, 저자들은 3D joint의 interest를 보여줍니다. 예를 들자면, shoulder joint이고, P= ( X, Y, Z ) 이죠. 일반적으로, corresponding feature volume은 around P를 따라 distinctive pattern을 가집니다. 이는 expensive 3D-CNNs에 의해 localized 될수 있죠. computation cost를 줄이기 위해, 저자들은 volume을 three coordinate planes로 re-project합니다. xy,yz,xz planes로 말이죠. 이는 3개의 2D feature maps를 가지게 되죠. 저자들은 이들 역시 distinctive patterns를 각 2D feature map의 해당 location에서 가질 것이라고 예상하고 이는 2D-CNNs에 의해 detected 될 수 있을 것이라 생각하죠. 그러면, P의 3D position은 3개의 planes에서 estimated coordinateds로 부터 assembled 될 수 있습니다.
그러나, 이 idea를 multi-person scenario에 적용할때, 저자들은 새로운 challenges를 만나게 되었는데요. different people 의 features가 mixed 될 수도 있다는 겁니다. 이런 현상을 coordinate planes로 projected 된 이후에 발견될 수 있는데, 각각이 3D space에서 멀리 떨어져 있을 때 조차도 발생한다는 겁니다. 이는 pose estimation accuracy를 저하시키죠. top-down 2D pose estimation에서 영감을 받아, 이 문제는 3D space에서 person을 cropping하고 person이 속한 features를 planes로 projecting함으로써 완화할 수 있죠. 그러면 remaining task는 각 person을 3D space에서 효과적으로 detect하는 것입니다. 저자들은 prioir을 사용하는데, people이 z axis를 따라 거의 overlap되지 않은 prior 이죠. 따라서 bird's-eye view에서 Fig 2 (B)에서 보여지다시피 쉽게 detected 될 수 있습니다.
저자들은 two-phase approach를 challenges를 해결하기 위해 취합니다. first phase에서 저자들은 Human Detection Networks를 보여줍니다. 이는 효과적으로 all people을 bird's-eye view로부터 모든 people을 detects하죠. 이는 3D bounding boxes로 나타나며, 오직 person-of-interest features만 다음 phase로 넘어갑니다. second phase는 fine-grained pose estimation을 각 person에 대해 conducts 합니다. 이는 joint Localization Networks를 활용하죠. 이 networks는 굉장히 eased 되는데 occlusion과 distraction이 first phase에서 제거되기 때문이죠. 중요한것은, networks에서 all the operators는 2D나 1D features에서 진행된다는 겁니다. 이는 speed를 boosts 하죠.
3.2 Human Detection Networks
저자들은 먼서 HRNet을 2D pose heatmaps를 multiview images로 부터 얻기 위해 사용하는데, heatmaps를 3D voxel space로 backprojecting함으로써 aggregated feature를 만들죠. people은 대게 ground plane에 있기 때문에 한사람이 다른 사람 바로 위에 있을 가능성을 매우 낮죠. 이는 저자들이 효율적으로 people을 detecting 한것으로부터 feature volume에서부터 2D bird's-eye view representation을 만드는 것에 영감을 주죠.
Detection in xy plane
저자들은 aggregated feature volume을 ground plane으로 re-project 하는데 이는 z direction에 따라 max-pooling을 수행함으로써 re-project하죠. 그렇게 함으로써 F_xy ( R^KxLxW )을 얻죠. 그런다음 저자들은 F_xy를 2D fully convolutional network에 입력으로 넣어주는데 xy plane에서 people의 locations를 탐지하죠. all people의 positions는 2D confidence map hat H( L x W )로 encoded 되는데 hat H_i,j(x,y)는 location(i,j)에서 human presence의 likelihood를 나타내죠. supervision training을 위해, 저자들은 ground-truth( GT ) 2D confidence map H ( xy )를 생성합니다. H (xy)의 value는 GT center point와 Gaussian kernel을 사용한 각 grid point 간의 distance에 의해 compute되죠. 구체적으로, grid point ( i,j )의 confidence value는 아래와 같이 계산됩니다.
여기서 N은 person의 numbers를 표기합니다. 그리고 ( ~i_n, ~j_n )은 person n에 대한 해당 GT position을 나타내고요. 저자들은 multiple people 에 대해 largest scores를 keep합니다. MSE loss는 아래와 같이 계산되죠.
저자들은 나아가 2D box size를 각 person에 대해 추정하는데 이는 loose constant size를 assuming하는 것 대신에 사용하죠. box의 height는 간단하게 2000mm로 set합니다. multiple people의 interference를 isolate 하는것은 매우 중요한데, 특이 crowded scene에서 중요합니다. 저자들의 model은 all grid points에서 box size embedding을 생성하는 데, 이는 hat S ( 2 x L x W )로 표기합니다. 그러나, large confidence를 가진 locations에서만 의미가 있죠. 저자들은 ground-truth size embedding S는 box anntoations에 기반하죠.
training 동안, 저자들은 grid points에 대해서만 losses를 계산합니다. 이는 ground-truth box에 adjacent 하죠. 구체적으로 2D GT box center ( hat x, hat y )에 대해, 저자들은 discretized grid points 에 대해 supervision을 추가합니다. 여기서 l은 single voxel의 length를 나타냅니다. w는 width를 표기하죠. U를 위에 언급된 neighboring points의 set을 표기한다고 하고 N은 image에서 person의 수라고 가정해봅시다. 저자들은 L1 loss를 U에서 각 centerpoint에 대해 계산하고 식은 아래와 같습니다.
게다가, quantization error를 줄이기 위해, 저자들은 local offset을 추정하는데 이는 horizontal plane에서 각 root joint에 대한 것이죠. size estimation과 유사하게, model은 offset prediction을 각 grid point에서 보여줍니다. hat O ( 2 x L x W )로 표기하고요. 저자들은 GT offset prediction O를 생성하는데, L1 loss를 neighboring points에 대해 사용하고 식은 아래와 같죠.

저자들은 간단한 network structure를 사용하는데 3개의 병렬적인 branches를 가지고 있고 heatmap, offset 그리고 size를 각각 추정하죠. Fig 3에서 보여지다시피, 2D bird's-eye features는 fully convolutional backbone network을 통과하고 세 개의 separate branches의 입력으로 주어집니다. 이는 3 x 3 convolution, ReLU 그리고 1 x 1 convolution으로 구성되어있죠.

Detection in z Axis
remaining task는 center height를 추정하는 것이죠. 먼저, 2D heatmap hat H (xy) 에 대해 largest confidences를 P를 활용해 proposals를 얻습니다. 이는 NMS를 적용한 이후를 말하고요. P = 10 으로 설정합니다. 이어서, 저자들은 해당 1D columns를 각 proposal에서 추출하는데 이는 aggregated feature volume V에서 추출하죠. F(z) ( R ^ P x K x H )로 표기합니다. 그리고 이는 1D fully convolutional network에 입력으로 주어지고 heigt를 regress하죠. 2D detection과 유사하게, 저자들의 model은 1D heatmap estimation hat H (z) ( [0,1]^PxH ) 을 생성합니다. 이는 possible height에서 human presence의 likelihood를 나타내죠. 저자들은 GT 1D heatmap H(z)를 계산합니다. 이는 각 proposal에 대해서 계산하고 Gaussian distribution을 사용한 center height에 기반하죠. 저자들은 여기서도 MSE loss를 사용하고 식은 아래와 같습니다.
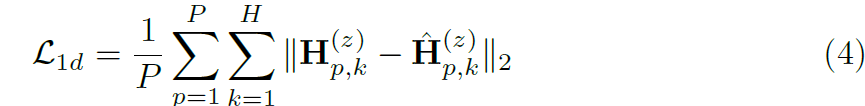
마지막으로, maximum confidence를 가진 height를 선택하고, 2D box center, offset and size와 결합함으로써 3D bounding box를 얻죠. 각 박스에대한 전체적인 confidence score는 2D heatmap의 scores와 1D outputs을 multiplying 함으로써 계산합니다. Gaussian function의 exponential property 에 따라 저자들은 3D Gaussian distribution의 approximate로 여겨질수 있고 저자들은 valid proposals를 선택하는 confidence scores에 대한 threshold를 설정합니다. 위를 요약하여 전체적인 training objective 는 아래와 같습니다.
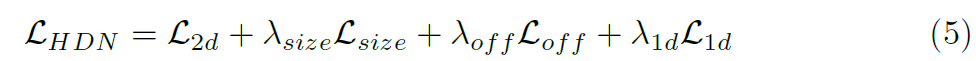
여기서 lambda_size = 0.02, lambda_off = 0.1, 그리고 lambda_1D = 1로 set하죠
3.3 Joint Localization Networks
person-specific Feature Volume
각 person의 bounding box를 가지고, 저자들은 fine-grained feature volume을 construct하죠. volume로 final 3D pose를 예측하고요. 저자들은 먼저 fixed size( 2m x 2m x2m )을 가진 box center에서 중앙화된 V로부터 smaller feature volume V'를 crop합니다. 이는 arbitrary poses를 cover하기에 충분하고 motion space의 relative scale을 유지하죠. space는 L' x W' x H' voxels로 나눠집니다. 이제 key step은 person-specific feature volume V_s를 얻는 estimated bounding box outside의 features를 zero로 만드는 겁니다. 이 masking mechanism은 다른 사람의 distraction을 줄이고 safe volume re-projection을 가능하게 하죠
Joint Localization
computational cost를 reduce하기 위해, 저자들은 V_s를 3개의 직교 2D planes로 re-project 합니다. xy plane, xz plane, yz plane이죠. P (xy) ( R ^ K x L' x W' ), P (xz) ( K x L' x H' ) 그리고 P(yz) ( R x W' x H' ) 이고 이들은 각각 해당 3 개의 plane에 re-projected 된 feature maps를 말하죠. 저자들은 feature projection에 대해 max-pooling을 사용합니다.
뒤이어, 3개의 feature map은 concatenated 되고 2D CNN에 입력으로 주어지며 이는 joint localization을 위한 것이죠. 이는 Fig 4에서 볼 수 있습니다.

저자들은 다른 axes에 대해서 voxels의 same granularity를 설정했는데 이는 parallel estimation이 가능하게 해주죠. 예를 들자면, L' = W' = H' 이죠. 2D CNN 은 joint-wise heatmap estimation을 각 re-projection plane에 대해 생성합니다. P(t)의 같은 shape에서 hat H (t) 로 표기하죠. quantization error를 줄이기 위해, hat H(t)의 center of mass를 계산하는데 이는 maximum response를 계산하는 대신이죠. 구체적으로 estimated positions hat J(t) ( R ^ K x 2 )는 아래와 같이 계산됩니다.
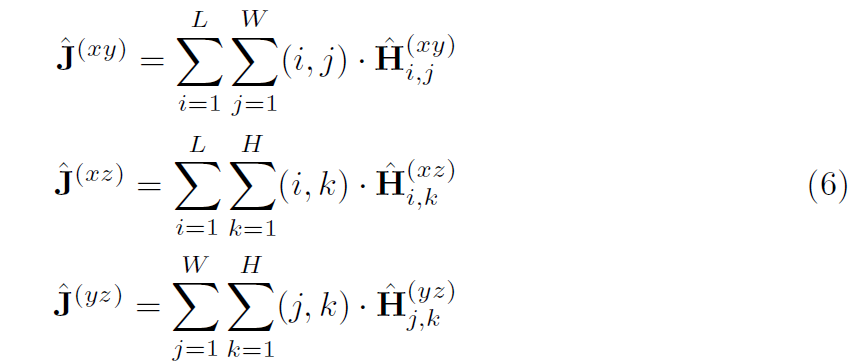
저자들은 각 plane에 대해 ground truth 2D location J(t)을 활용해 estimations를 supervise하고 L1 loss를 아래와 같이 계산하죠.
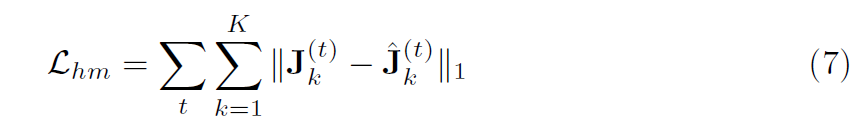
Adaptive Weighted Fusion
P(t)의 quality와 pose estimation의 difficulty는 re-projection plane과 human pose 따라 다양합니다. 따라서 저자들은 model이 different planes에서 자동적으로 estimations를 discriminate하고 balance하는 것을 학습할 수 있기를 바랐죠. 이를 위해, 저자들은 lightweight confidence regression network을 도입합니다. 저자들은 hat H(t)의 pattern이 2D pose estimation의 quality를 반영할 수 있다고 가정하죠. 따라서 estimated heatmaps hat H (t)는 shared confidence regression network에 입력으로 주어집니다. 저자들은 simple design을 confidence regression network에 적용하는데 convolutional layer와 global average pooling layer 그리고 하나의 fully-connected layer로 구성되어 있죠.
이 network는 joint-wise fusion weight을 각 plane에 대해 생성합니다. W(t) ( R^K )로 표기하죠. 저자들은 pair-wise 방법으로 Softmax function을 normalization을 위해 사용하고 final 3D prediction ~J (Kx3)을 얻죠. 구체적으로 joint k 에 대해 최종 estimations는 아래와 같이 계산됩니다.
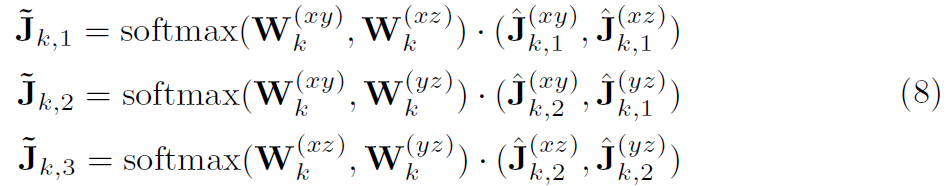
hat J(xy)_k,1 은 hat J(xy)_k의 2D estimated coordinates의 처음 구성요소를 취하는 것을 표기하죠. 말그대로, x-axis의 component입니다. 다른 notations는 유사한 interpretations을 가지죠. J는 GT 3D pose를 표기합니다. 저자들은 L1 loss를 confidence regression network를 학습하는데 사용하며 식은 아래와 같습니다.

JLN의 ovrall training objective는 아래와 같으며 실험에서 lambda_conf = 1로 설정합니다.

이 글을 처음쓴게 일주일 전인거 같은데 이제야 마무리하네요
이번 글을 여기까지 할께요.
요즘 정말 바쁘네요. 논문도 많이 읽고
리서치도 하고 해야하는데.. 참 시간이 많지가 않네요



