Abstract
이 논문에서 저자들은 efficient real-time object detector를 설계하는 것을 목적으로하는데 YOLO series를 넘고자 하죠. 그리고 많은 object recognition task로 확장할 수 있도록 하는 것을 목표로 합니다.가령 instance segmentation과 rotated object detection 등이 있겠죠. 더 efficient한 model architecture를 얻기 위해, 저자들은 backbone과 neck에서 경쟁할 만한 capacities를 가지는 architecture를 explore하는데요. 이 architecture는 lagre-kernel depth-wise convolutions로 구성된 building block으로 만들어져 있죠. 저자들은 나아가 soft labels를 도입하는데, dynmic label assignment 에서 matching costs를 계산할 때 사용되고, 이는 accuracy를 향상시키죠. 더 나아진 training techniques와 함께, RTMDet이라 불리는 detector의 성능은 SOTA 성능을 달성합니다.
Introduction
Optimal efficiency는 object detection에서 최우선적인 고려 대상이었는데요. 특히 real-word perception에서는 더욱 강조되죠. 분야로는 자율주행, 로보틱스, 드론 등이 있겠고요. 이를 위한 많은 연구들이 있었고, YOLO series는 다른 model architectures과 training techniques를 사용하여 one-stage object detector의 efficienciency와 accuracy를 꾸준히 향상시켜왔죠. 이 논문에서, 저자들은 YOLO series의 limits를 극복하는 것을 목표로하고 Real-Time Models for object Detection , 즉 RTMDet 계통으로 기여하고자 하죠. RTMDet는 instance segmentation이나 rotated object detection을 수행하기에도 충분하죠. appealing한 improvements는 dynamic label assignments에서 soft label 를 활용해 더 나은 optimization 과 better representation으로 부터 기인하는데, 이 representation은 large-kernel depth-wise convolutions를 활용하죠.
구체적으로, 저자들은 먼저 large-kernel depth wise convolutions를 사용합니다. 이는 backbon의 basic building block과 neck 에 있죠. 이는 model's의 capability를 향상시키는 데, 이 capability는 global context를 capturing 하죠. depth-wise convolution을 building block에 직접적으로 위치시킨 것은 model의 depth를 증가시키고 따라서 inference speed를 감소시키죠. 따라서 저자들은 building blocks의 수를 줄이는 데 이는 model depth를 감소시키고 model width를 증가시킴으로써 model capacity를 보상하죠. 저자들은 또한 neck 더 많은 parameters를 putting하는 것과 backbone에서 backbone의 capacity를 compatible하게 만드는 것이 better speed-accuracy trade-off를 달성할 수 있다는 것을 발견했죠. 전체 model architectures의 modification이 fast inerecne speed를 가능하게 하는데, model의 re-parameterizations 없이 가능하죠.
저자들은 나아가 training strategies를 되돌아 보죠. data augmentations, optimization, 그리고 training schedules 의 더 좋은 조합으로 dynamic label assignment strategies는 더욱 개선될 여지가 있다는 사실을 알아내죠. 이는 ground truth boxes와 model predictions를 mathcing할 때 hard labels 대신에 soft targets을 도입함으로써 가능하고요. 그런 design은 high-quality matching에 대해 cost matrix의 discrimination을 향상시킬 뿐만 아니라, label assignment의 noise 역시 감소시키죠. 따라서 model의 accuracy를 개선하고요.
RTMDet는 generic하고 instance segmentation과 rotated object detection으로 쉽게 확장될 수 있죠. 쉽게 kernel과 mask feature generation head를 더함으로써 RTMDet는 10%의 additional parameters만을 가지고 instance segmentation을 수행할 수 있죠. rotated object detection에 대해서는, RTMDet는 box regression layer의 dimension을 4에서 5로만 확장하고 rotated box decoder로만 바꿔주면 되죠. 저자들은 또한 general object detection datasets에 대해 pre-training 이 rotated object detection에서 이점이 있다는 것을 발견하죠.
저자들은 많은 실험을 시행했고 RTMDet의 effectiveness를 증명했습니다.
Related work
Efficient neural architecture for object detection
object detection은 scene에서 object를 recognize와 localize하는 것을 목표로 합니다. real-time applications에 대해, 기존 연구들은 anchor-based나 anchor-free one stage detectors를 쓰죠. 이 model efficiency를 향상하기 위해, efficient backbone network와 model scaling strategies 그리고 multi-scale feature enhancement가 사용되었죠. 이들은 handcrafted design을 가지고 있거나 neural architecture search를 통해 결정되었고요. 최근 advances는 model re-parameterization을 사용하는데 이는 inference speed를 향상시키죠. 물론 model deployment 이후에 말이죠. 이 논문에서 저자들은 backbone과 neck에서 compatible capacity를 가진 overall architecture를 contribute 합니다. new basic building block을 가지는데, 이 building block은 large-kernel depth-wise convolutions를 가지고 있습니다. 이는 more efficient object detector를 위함이죠.
Label assignment for object detection
object detector를 향상하기 위해 another dimension은 label assignment와 training loss의 design입니다. Pioneer method는 IoU를 matching criterion으로 사용했는데, 이는 ground truth boxes와 model predictions이나 label assignment에서 anchors를 비교하기 위함이었죠. 후속 연구에서 다른 matching criteria를 사용하는데, object centers와 같은 것들이 있죠. Auiliary detection heads는 training을 안정적이고 빠르게 하기위해서 사용되었고요. Hungarian Assignment에 영감을 받아, dynamic label assignment가 사용되었는데, 이는 convergence speed와 model accuracy를 향상시키기 위함이었죠. 저자들은 soft labels를 제안하는데 high와 low-quality matches 간의 distinction을 enlarge하는 matching costs를 calculating할 때 사용하죠. 그럼으로써 training을 안정화하고 convergence를 accelerating 하죠.
Instance Segmentation
Instance Segmentation은 per-pixel mask를 predicting하는 것을 목표로하죠. 해당 mask는 각 object의 interest이고요. 선행 methods는 이 task를 다루기 위해 different paradigms를 사용하죠. mask classification, 'Top-Down', 'Bottom-Up' approaches 등이 있죠. 최근 시도는 instacne segmentation을 one stage로 수행하는데요. bounding box가 없죠. 이들 attemps의 representative는 dynamic kernels에 기반한다는 겁니다. 이 kernels는 either learned parameters나 dense feature maps로부터 dynamic kernels를 generate하기 위해 학습하죠. 그리고 그들을 mask fueature maps를 활용해 convolution을 시행하기 위해 사용하죠. 이 연구에 영감을 받아, 저자들은 RTMDet를 kernel prediction과 instance segmentation을 수행하는 mask feature heads로 확장합니다.
Rotated object detection
Rotated object detection 은 objects의 orientation을 예측하는 것을 목적으로 하죠. locations와 categories를 포함해서 말이죠. general object detector에 기반한 different feature extraction networks는 object rotations로 인한 feature misalignment를 완화하기 위해 제안되었죠. rotated bounding box regression task를 쉽게하기 위해 사용된 rotated boxes의 다양한 representations가 있죠. 이 논문에서는 general object detector를 최소한의 변형으로 확장합니다. angle prediction branch를 추가하고 GIoU를 Rotated IoU Loss로 바꾸죠. high precision general object detector가 high-precision rotated object detection에서 중요하다는 것 역시 알려줍니다.
Methodology
이 논문에서, 저자들은 RTMDet 계열을 설계합니다. RTMDet의 macro archiecture는 전형적인 one-stage object detector이고 다음 section에 설명되죠. 저자들은 model efficiency를 향상시키는데, large-kernel convolutions를 backbone과 neck에 basic building block에 사용하죠. 그리고 model depth와 width 그리고 resolution을 sec 3.2 를 따라 밸러스 있게 조절합니다. 저자들은 나아가 soft labels를 dynamic label assignment strategies에서 사용하는데 model accuracy를 향상시키는 data augmentations와 optimization strategies를 더 잘 combination 하죠. RTMDet는 versatile한 object recognition framework인데요, instance segmentation과 rotated object detection tasks로 최소한의 변형만을 가지고 확장 될 수 있죠.
3.1 Macro Architecture
저자들은 one-stage object detector의 macro architecture를 backbone, neck 그리고 head에 Fig 2에서 보여주는 것처럼 보여주는데요.

최근 YOLO series의 advance는 전형적으로 CSPDarkNet을 backbone architecture로 적용합니다. 이는 4 개의 stage를 포함하고 각 stage는 basic building blocks로 쌓여있죠. 이는 Fig 3.a에서 볼수 있습니다.

neck은 backbone으로부터의 multiscale feature pyramid를 input으로 취하죠. 그리고 pyramid feature map을 강화하는 bottom-up and top-down feature propogation을 활용해 backbone과 같은 basic building blocks를 사용하죠. 마지막으로, detection head는 object bounding boxes와 their categories를 각 scale의 featuremap에 기반하여 예측하죠. 이런 architecture는 일반적으로 general and rotated objects에 적용됩니다. 그리고 instance segmentation에 kernel 과 mask feature generation heads로 인해 확장될 수 있죠.
macro architectur의 potential을 완전히 사용하기 위해, 저자들은 먼저 powerful한 basic building blocks을 연구합니다. 그런다음 computation bottleneck을 해당 architecture에서 investigate하고 depth, width, 그리고 resolution을 backbone과 neck에서 balance하게 맞추죠.
3.2 Model Architecture
Basic building block
backbone에서 large effective receptive field는 dense prediction task에 이점을가지죠. 예시로는 object detection과 segmentation이 있겠고 이유는 해당 receptive field가 image context를 더 comprehensively하게 model하고 capture하도록 도와주기 때문이죠. 그러나, 이전 attemps( dilated convolution 과 non-local blocks ) 는 computationally 비싸고, 실질적인 활용에 제한이 있죠. 물론 real-time에서요. 최근 연구는 large-kernel convolutions의 사용을 되짚습니다. resonable 한 compurational cost를 가진 receptive field를 강화할 수 있다는 것을 보여주는데, 이는 depth-wise convolution을 통해 가능하죠. 이들 연구에 영감을 받아, 저자들은 5x5 depth-wise convolutions를 CSPDarkNet의 basic building block에 도입합니다. 이는 effective receptive fields를 increase하죠. 이는 Fig 3.b에서 볼 수 있습니다. 이 방법은 more comprehensive contextual modeling을 가능하게 하고 accuracy를 상당히 개선합니다.
some real-time object detectors가 re-parameterized 3x3 convolutions를 basic building block에 사용한다는 것은 언급할 만한 가치가 있죠. 이는 Fig c, d에서 볼 수 있고요. re-parameterized 3x3 convolutions는 inference 동안 accuracy를 개선하는 free lunch를 고려하는데, 이는 slower training speed와 increased training memory와 같은 side effects를 야기하죠. 이는 또한 model 이 lower bits로 quantized된 이후에 error gap을 증가시키는데 이는 re-parameterizing optimizer와 quantization aware training을 통해 compensation을 요구하죠. Large-kernel depth-wise convolution은 더 간단하지만 훨씬 효과적인 option이죠. 왜냐면, 더 적은 training cost를 요구하고 model quantization 이후에 더 적은 error gap을 야기하기 때문이죠.
Balance of model width and depth
basic block에서 layer의 number 역시 증가하는데 이는 additional point-wise convolution 과 뒤따라나오는 large-kernel depth wise convolution 때문이죠. 이는 parallel computation을 방해하는데 inference speed 저하를 야기하죠. 이문제를 해결하기 위해, 저자들은 blocks의 number를 줄이고 적절하게 block의 width를 늘립니다. 이는 parallelization을 증가시키고 model의 capacity를 유지하며 결국에 inference speed를 accuracy의 희생없이 개선하죠
Balance of backbone anb neck
Multi-scale feature pyramid는 object를 다양한 scale에서 detect하는 object detection을 위해 필수불가결하죠. multi-sclae features를 enhance하기 위해, 이전 approaches는 더 많은 parameters를 사용하는 larger backbone을 이용하고 더 많은 connection과 feature pyramid를 따라 fusion을 활용하는 heavier neck을 사용했죠. 그러나 이 시도들은 computation과 memory footprints를 증가시키죠. 그럼우로 저자들은 다른 strategy를 적용하는데, 그는 바로 backbone에서 부터 neck까지 유사한 capacities를 갖도록 하는 neck에서 basic block의 expansion ratio를 증가시킴으로써 computations와 parameters를 더 넣는 전략을 선택하고 이는 computation-accuracy trade-off를 달성하죠
Shared detection head
Real-time object detectors는 higher performance를 위한 model capacity를 강화하는 different feature scales에 대해 separate detection heads를 사용하죠. multiple scales에 걸쳐 detection head를 공유하지 않는다는 말이죠. 저자들은 different design을 선택합니다. scale을 따라 heads의 parameters를 share하도록 하죠. 그렇지만, different Batch Normalization layers를 통합하는 데, 이는 accuracy를 유지하면서 head의 parameter amount를 감소시키죠. BN은 Group Normalization과 같은 other normalization layers보다 더 efficient한데 inference에서 training에서 calculated 된 statistics 직접 사용하기 때문이죠.
3.3 Training Strategy
Label assignment and losses
one-stage object detector를 학습하기 위해, each scale로 부터 dense predictions은 different label assignment strategies를 통해 ground truth bounding boxes와 matched되죠. 최근 advances는 dynamic label assignment strategies를 적용합니다. 이는 mathcing criterion으로 training loss를 활용해 cost functions consistent를 사용하는 것이죠. 그러나, 저자들은 그런 cost calcultion은 몇가지 한계가 있음을 발견합니다. 따라서, 저자들은 dynamic soft label assignment strategy를 제안합니다. SimOTA에 기반하죠. 해당 cost function은 아래와 같이 공식화 되죠

여기서 C_cls, C_center, 그리고 C_reg는 각각 classification cost, region prior cost 그리고 regression cost를 의미하죠. lambda 1 = 1, lambda 2 = 3, 그리고 lambda 3 = 1입니다. 이는 default로 설정된 weights죠. 세 cost의 calculation은 아래서 설명합니다.
이전 methods는 binary labels를 사용하는데, 이는 classification cost C_cls를 계산하죠. 이 방법은 high classification score를 가진 prediction이 가능하게 하지만, low classification cost 가지는 incorrect bounding box를 가지는 prediction을 하게 되죠. 이 문제를 해결하기 위해 저자들은 soft labels를 C_cls에 도입하는 데 식은 아래와 같죠

이 변형은 GFL에서 영감을 받았는데 predictions와 ground truth boxes간에 IoU를 soft label Y_soft로 사용합니다. Y_soft는 classification branch를 학습하죠. soft classification cost는 different regression qualities를 가진 matching costs를 reweights 할 뿐만 아니라 binary labels가 야기하는 unstable matching이나 noisy 역시 피할 수 있죠.
regression cost로 Generalized IoU를 사용할 때, best match와 worst match간의 maximum difference는 1보다 작죠. 이는 high-quality matches와 low-quality matches를 차별화하는 것을 어렵게 하죠. different GT-prediction paris의 match quality를 더 차별화하기 위해 , 저자들은 IoU의 logarithm을 regression cost로 사용합니다. GIoU를 loss fuction으로 쓰는 대신에, lower IoU values를 가진 matches에 대해 cost를 amplifies하는 아래의 loss function을 사용하죠.

region cost C_center에 대해, 저자들은 dynamic cost의 matching을 stabilze하는 soft center region cost를 사용하는데 기존에는 fixed center prior를 사용했었죠. 식은 아래와 같습니다.

여기서 alpha와 beta는 soft center region의 hyper-parameters인데, 저자들은 alpha는 10, beta는 3으로 set합니다.
Cached Mosaic and MixUp
MixUp과 CutMix와 같은 Cross-sample augmentations는 object detectors에 광범위하게 적용되는 데요. 이들 augmentations는 강력하지만 두 가지 side effects를 야기하죠. 먼저, 각 iteration에서, 그들은 training sample을 generate하기 위해 multiple images를 load해야하죠. 이는 더 많은 data loading costs를 야기하고 slow training의 한 원인 되죠. 두 번째, generated training sample은 noisy입니다. 즉 dataset의 real distribution에 속하지 않을 거란거죠. 이는 model learning에 영향을 미치죠.
저자들은 MixUp 과 Mosaci을 개선하는데 data loading을 위한 demand를 감소시키는 caching meching을 활용하죠. cache를 사용해서, training pipeline에서 mixing images의 time cost는 single image를 처리하는 수준으로 상당히 감소될 수 있죠. cache operation은 cache lenght 와 poping method에 의해 controlled 되고 large cache length와 random popping method는 oreiginal non-cached MixUp and Mosaic operations와 동일하게 여겨질 수 있죠. 그러는 동안, small cache length와 First-In-First-Out poppoing method는 repeated augmentation과 유사하게 여겨질 수 있습니다.
Two-stage training
strong data augmentation에 의한 noisy samples의 side effects를 줄이기위해, YOLOX는 two-stage training strategy를 사용합니다. 첫 번째 stage는 strong data augmentation을 사용하고 second stage는 weak data augmentations를 사용하죠. random resizing아니 flipping 과같은 것들이 있죠. strong augmentation은 random rotation이나 shearing을 포함하는데 이는 inputs과 transformed box annotations간에 misalignment를 야기하죠. 그 때문에 YOLOX는 L1 loss를 fine-tune regression branch에 더하는데 이는 second stage에서 적용되죠. data augmentation과 lossfunctions를 decouple하기 위해, 저자들은 이런 data augmentations를 제외합니다. 첫 번째 training stage에서 mixed images를 8개로 로 늘리고 data augmentation의 strength에 대해 충분한 compensate을 주는 280번의 epoch동안 시행하죠. 그리고 마지막 20 epochs는 Large Scale Jittering으로 바꾸는데 이는 real data distributions를 활용해 비슷하게 aligned 된 domain에서 model 을 fine-tuning 하도록 해주죠. training의 stabilize하기 위해, 저자들은 AdamW를 적용합니다. 이는 convolutional object detector에서 드물게 사용되지만 cision transformers에서는 자주 사용되는 optimizer이죠.
3.4 Extending to other task
Instance segmentation
저자들은 RTMDet를 적은 modification을 가지고 instance segmentation이 가능하도록 하는데요. RTMDet-Ins라고 명명합니다. Figure 4에서 볼 수 있듯이, RTMDet를 기반으로하고 additional branch가 더해집니다. kernel prediction head와 mask feature head로 구성되고 CondInst와 유사하죠.
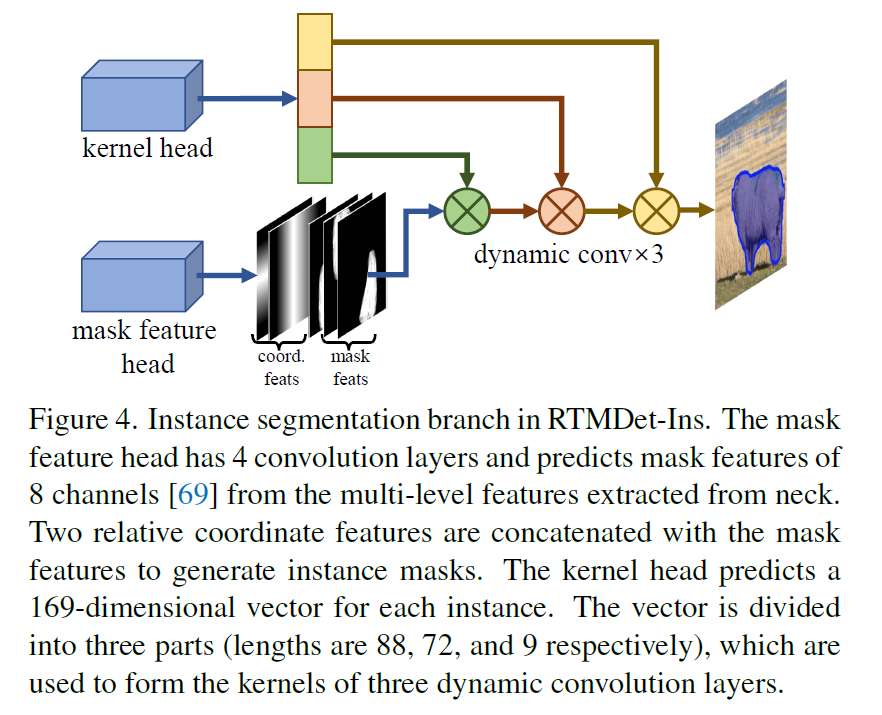
mask feuater head는 4 개의 convolution layers로 구성되는데 mask features를 8 개의 channels를 가지고 multi-level features로 부터 추출하죠. kerenl prediction head는 169 차원 vector를 각 instance 마다 예측하는데, 이는 three dynamic convolution kernels로 나눠지고 각 kernels는 instance segmentation masks를 mask features와 coordinate feature를 통해 instance segmentation masks를 생성하죠. prior information inherent를 mask annotations에서 사용하기 위해, 저자들은 box center 대신에 dynamic label assignment 에서soft region prior를 계산할 때 masks의 mass center를 사용합니다. 저자들은 dice loss를 supervision으로 사용하죠.
Rotated object detection
rotated object detection과 general object detection 간의 inherent similarity 덕분에, 3가지 step을 RTMDet에 적용합니다. 그리고 이는 RTMDet-R로 명명하죠. 1) 1x1 convolution layer를 regression bracnh에 추가하는데 이는 rotation angle을 예측하죠. 2) bounding box coder를 변경하는데 rotated boxes를 support 합니다. 3) GIoU loss를 Rotated IoU loss로 대체하죠. highly optimized model architecture는 RTMDet-R의 high performance 보장합니다. 게다가, RTMDet-R은 RTMDet의 parameters를 공유하죠. RTMDet의 model weights는 general detection dataset에서 pre-trained 되고 rotated object detection을 위해 매우 좋은 initialization의 역할을 합니다.
다음 나오는 내용은 생략할게요



