Abstract
많은 video instance segmentation(VIS) method는 video sequence를 개별 frame으로 나누고 이는 object를 frame by frame으로 detect하고 segment하죠. 그러나 이런 FiFo pipeline은 temporal information을 사용하는 데에 비효율적이죠. 짧은 frame에서 인접한 frame은 문맥적으로 매우 긴밀한 상관관계를 갖는다는 이 사실에 기반하여, 저자들은 one-stage FiFo framework를 clip-in clip-out( CiCo ) framework로 확장합니다. 여기서는 VIS를 clip by clip으로 수행하죠. 구체적으로 spatio-temporal feature cube를 build하는 짧은 video clip에서 모든 frames의 FPN features를 쌓습니다. 그리고 prediction heads(CPH) 와 mask branch의 2D conv layers를 3D conv layers로 바꿉니다. clip-level prediction head( CPH )와 clip-level mask head( CMH )를 만듦으로써 말이죠. 그런다음 instance의 clip-level masks는 CPH로부터의 box-level predictions와 CMH로부터의 clip-level features를 fully convolutional network의 입력으로 넣어줌으로써 생성되죠. clip-level segmentation loss는 생성된 instance masks가 clip내에서 시간적으로 상관성이 있다는 것을 보장하도록 제안됩니다. proposed CiCo 전략은 inter-frame alignment로 부터 자유롭죠. 그리고 쉽게 존재하는 FiFo based VIS 방법에 embedded 될 수 있습니다. generality와 effectiveness를 입증하기 위해, 저자들은 두 가지 FiFo methods에 자신들의 방법을 적용합니다. 두 network는 yolact과 condInst이고 CiCo-Yolact 과 CiCo-CondInst라는 새로운 VIS models의 결과를 내놓죠. 이는 성능면에서 Sota를 기록하게 되죠.
Introduction
VIS는 pixel-level segmentation masks를 individual instance 객체에 대해 얻는 것을 목표로 하죠. 물론 entire video에 걸쳐 모든 class에 대해서 말이죠. 이는 동시에 객체를 classify, detect, sement 와 track하는 것이 필요하고요. VIS의 많은 방식은 FiFo( frame-in frame-out ) 방법인데 먼저 모든 video를 개별 frame으로 나누고 object를 frame by frame으로 segment합니다. 그리고 나서 frame에 걸쳐 예측된 instance masks를 associate하는데 이는 temporal information을 integrating함으로써 이가 가능하죠. 예를 들어, 전형적인 two stage image instance segmentation ( IIS ) 에 기반한 Mask R-CNN, MaskTrack R-CNN은 object의 embedding vector를 예측하는 new branch를 추가하고 frame에 걸쳐 instances를 연결하죠. Fig. 1(a)에서 보여집니다.

Fig 1(a)는 frame-level VIS methods의 일반적인 pipeline을 설명합니다. 그러나, inter-frame alignment가 특징인 이런 pipeline은 더 robust한 classification, detection 그리고 segmentation을 수행하기 위한 temporal information을 사용하는데에 inefficient하고 ineffective하죠.
몇몇 연구가 앞서 말한 문제를 완화하기 위해 제안되었죠. Fig 1(b)에서 보여지는 바와 같이 STEm-seg는 spatio-temporal embedding을 수행하는데 bottom-up paradigm을 활용하죠. 이는 각각에 pixcel에 가까운 같은 object에 속한 pixels을 pull하고, 다른 object의 pixel을 push합니다. 불행히도, bottom-up paradigm은 top-down 방식에 비해 훨씬 낮은 performance의 결과를 도출하죠. VisTR method는 Fig1(c)에 보여지는 바와 같죠. 이 방식은 video에서 모든 frame의 FPN features를 sequence로 바꾸고 Transformer에 입력으로 주어 global spatio-temporla attention을 생성합니다. 그렇게 video에 대해 instance segmentation을 수행합니다. computational and storage overhead를 줄이기 위해 IFC는 최근 개발되었는데 분리된 spatial과 temporal transformers를 사용하고 이는 clip에 대해 attention을 학습합니다. 그리고 SOTA accuracy를 달성하죠.
사실, adjacent frames의 contents는 매우 상관관계가 높습니다. 이는 video에서 ojbect를 segment하고 detect하기위헤 더 좋게 사용될 수 있죠. Fig 3에서 저자들 temporal intersection에 대해 몇몇 statistics를 plot합니다. 이는 bounding boxes와 masks의 union 에 대한 것이고 YouTube-VIS 2019 train set을 사용하죠. 많은 instances의 locations가 인접한 frame에서 거의 일치하다는 사실이 관찰되었습니다. 게다가 multiple frames는 object의 appearance에 대해 comprehensive viewpoints로 제공될수 있죠. 따라서 object tracking을 위한 richer spatio-temporal contextual information을 제공할 수 있죠.
temporal coherence의 이점을 활용해, 저자들은 FiFo one-stage VIS pipeline을 CiCo one으로 확장합니다. 이는 instance masks를 clip by clip으로 생성할 수 있죠. 구체적으로 Fig1(d)에서 보여준바와 같이, all frames의 모든 FAN features를 쌓습니다. 그렇게 spatio-temporalfeature cube를 만들죠. 그리고 2D convlutional layers를 3D conv layers로 바꾸는데 prediction heads와 mask head에 있는 conv layer를 대체하죠. clip-level prediction head( CPH )는 box-level predictions를 학습하는데 class confidences, bounding boxes의 regression coordinates,나 clip에 걸쳐 object에 의해 공유되는 mask parameters를 포함하죠. 반면 CMH는 clip-level feature maps의 set을 생성합니다. 그런 다음, clip을 통해 object의 final clip-level masks 얻을 수 있는데 이는 clip-level prototypes와 그에 해당하는 box-level predictions를 small fully convolution network( FCN )에 넣어줌으로써 얻게되죠. FCN은 dynamic filters를 가지고 있는데 weights와 bias가 mask parameters로 예측되죠. 게다가, 저자들은 clip-level instance segmentation loss를 정의하는데 이 loss는 clip에서 temporal coherence를 유지하도록 예측된 clip-level instnace masks를 push하죠. 마지막으로 CiCo 전략의 effectiveness와 generality를 validate하기 위해 Yolact과 CondInst에 적용하고 VIS performance에서 SOTA를 달성합니다.
Related work
Image instance segmentation ( IIS )
IIS networks는 roughly 하게 bottom-up 과 top-down paradigms로 나눌 수 있죠. bottom-up 방식은 먼저 semantic segmentation을 수행하고 그런다음 각 instance에 대한 specific location을 identify하죠. 반면 후자는, objects를 먼저 detect한 다음 그들은 segment 합니다. Mask R-CNN과 그에 대한 후속 계열은 대표적인 two-stage IIS approaches이죠. 먼저 RoIs를 생성하는데 이는 RPN에 의해 생성되고 RoIPooling아니 RoIAlign을 통해 features를 extract합니다. 이 features는 다음 stage에서 classify 하고 segment하죠. 최근 one-stage top-down approaces ( Yolact 과 CondInst ) 는 instance segmentation을 병렬적인 두 개의 sub-tasks로 나눕니다: image-size mask prototypes의 set을 생성하는 것과 box-level mask coefficients를 예측하는 것이죠. 그런다음 그들은 linearly하게 combining하는데 이는 final instance masks를 얻기 위함이죠. 이는 IIS의 second stage의 필요성을 제거하죠. 그러면서도 accuracy와 speed의 balance는 유지하면서도 말이죠.
Video Instance Segmentation( VIS )
IIS와 비교해서, VIS 는 temporal dimension을 고려합니다. 몇몇의 방법들은 video sequence를 개별적인 frames로 나누고 object를 frame by frame으로 detect하고 segment하죠. 이는 IIS 방법을 활용하는 방법이죠. 그런 다음 새롭게 추가된 tracking branch에 의해 예측된 object embedding vectors를 통해 objects를 최종적으로 associate합니다. MaskProp 와 ProposeReduce는 Mask R-CNN을 확장하는데 key frame으로부터 reference frames으로 예측된 frame-level instance masks를 align하는 branch를 도입하죠. 그들간의 차이는 전자는 instance masks를 하나의 frame으로부터 모든 인접한 frames으로 propagate하고 후자는 instance masks를 weveral selceted key frames를 다른 모든 frames로 propagates한다는 것이죠. mask alignment를 위해 가장 많이 사용되는 techniques은 deformable convolution. non-local block, attention, correlation and graph neural network가 포함되죠. spatio-temporal embedding scheme은 STEm-Seg에서 제안되었습니다. 비록 bottom-up paradigm이 performance에 많은 하락을 가져왔지만 말이죠. attention mechanism에 영감을 받아, VisTR은 Transformer를 도입하는데 이는 global spatio-temporal attention을 생성하고 instance masks를 전체 video에 대해 생성하죠. heavy computational and storage overhead를 완화하기 위해, IFC는 separated spatial and temporal attentions를 적용합니다. 이 연구에서, 저자들은 general strategy를 제안하는데 frame-in frame-out one-stage VIS method를 clup-in clip-out one으로 확장하죠.
Approach
이번 파트에서, 저자들은 먼저 간단하게 FiFo one-stage instance segmentation framework 에 대해 설명합니다. 그런 다음 short-term temporal coherence 에 대해 분석하죠. 그리고 CiCo Vis approach를 제안합니다. 마지막으로 전체 architecture를 보여주고 loss fucntion에 대해 알려줍니다. 저자들을 전체 video를 V로 표기합니다. ( V = [ I^1, ..., I^L ) (R ^LxHxWx3) 여기서 H, W, L은 각각 height, width 그리고 frame의 총 개수를 나타냅니다. I^t는 video 안의 single frame을 표기합니다. 각 video clip은 T= 2delta + 1의 연속된 frames를 포함한다고 가정합니다. 그리고 이는 V^l = [ I^t-delta,...,I^t+delta] 로 표기되며 t는 clip의 central frame index입니다.
Frame-in Frame-out One-stage VIS
Fig 2(a)에서 보여지는 바와 같이, FiFo one-stage VIS framework는 single frame I^t를 backbone과 multi-scale feature map을 얻기 위한 FPN에 inputs으로 넣죠. 먼저, 각 FPN layer의 feature maps는 prediction head에 input으로 넣어집니다. prediction head는 box-level predictions를 obtain합니다. 물론 calss confidences, regression coordinates, 그리고 mask parameters 역시 얻죠. 그런다음 FPN layers의 feature maps는 2D conv layer를 통과합니다. 그리고 p3 layer와 같은 reolution으로 upsampled되죠. 그들은 더해져 image-elvel feature maps( prototypes라고 불리죠 )를 생성하는 mask head의 input으로 주어집니다. 그런다음 frame-elvel mask는 box-level predictions와 image-level prototypes를 dynamix convolutions를 가진 FCN를 통과시킴으로써 얻을 수 있죠. dynamic convolutions의 weights와 bias는 mask parameters로써 예측되고요.
최근 one-stage instance segmentation approaches는 FCN architecture와 instance location embedding에서 주요한 차이를 보입니다. 구체적으로 Yolact는 box-level mask parameters의 linear combination 적용합니다. 이는 bias가 없는 1x1 dynamic conv layer와 동등하죠. 여기서 box-level mask parameters의 수와 image-level prototypes의 channel은 같습니다. 그 과정은 아래와 같이 표현되죠.

여기서 B_i^t는 bounding boxes이고, sigma는 Sigmoid activation fuction입니다. Crop은 instance mask가 bounding box에 의해 cropped 되었다는 것을 의미하죠. 반면 CondInst는 세 개의 1x1 dynamic convlayers를 사용하고 이는 compact FCN을 만들죠. input은 channel은 8이고 P^t에 대한 모든 location으로부터 bounding box의 central point 까지 relative coordinates의 map O^t_i ( R ^ 2h_3 x2w_3 x2 )을 가진 image-level prototypes P^t의 concatenation입니다. box-level mask parameters theta^t_i 는 FCN에서 3개의 filter의 weights와 bias를 포함합니다. 그리고 k' = 169입니다. 이 과정은 아래와 같이 표현될 수 있죠.
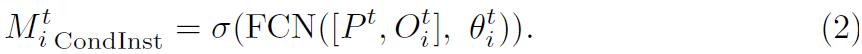
Fig 2(d1)에서 보여지는 바와 같이, 3frame clip이 주어지면 FiFo pipline은 frame by frame으로 instance masks를 생성합니다. 이는 single frame의 spatial information에 기반해 object를 segment하고 detect하며 classify 할 수 있죠. static image와 다르게 segmentation은 더 복잡한 문제가 있죠. uncommon camera-to-object view, motion blur, occlusion, out of focus와 같은 문제가 바로 그것이죠. FiFo methods는 이들 문제를 다루기 challenging합니다. 많은 objects를 놓치게 되죠. 물론 정확하지 않은 masks와 classification을 포함해서 말이죠.
Temporal Coherence
short time에서 adjacent frames의 contents는 매우 상관관계가 높다는 사실은 저자들에게 VIS를 clip by clip으로 수행한다는 영감을 주었죠. temporal coherence를 quantify 하기 위해, 저자들은 temporal bounding-boxes IoU( T-BIoU )와 temporal masks IoU ( T-MIoU )를 아래와 같이 정의합니다.
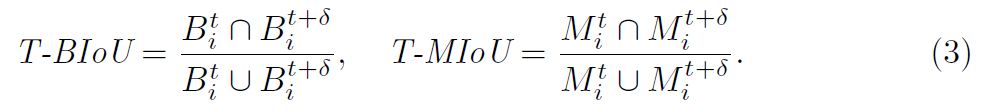
여기서 B^t_i, B^t+delta_i 그리고 M^t_i, M^t+delta_i는 frame t와 t+delta에서 bounding boxes와 i-th instance의 masks입니다. delta는 interval frames의 number입니다. video의 frame t에서 instance에 대해, 만약 object가 t-delta 와 t+delta에서 같은 시간에 나타났다면 T-BIoU 와 T-MIoU는 두 frames 모두에 대해 계산합니다 그런다음 평균을 내죠. 반면, 오직 한 frame에서만 나타난다면 해당 frame 을 계산하죠.
YouTube-VIS 2019 train set에서 모든 videos를 traversing 후에, 저자들은 T-BIoU와 T-MIoU의 histograms를 Fig3과 같이 plot했죠.

여기서 delta는 1부터 4까지 입니다 그리고 bin step은 0.05 입니다. T-BIoU와 T-MIoU가 0.75보다 큰 objects의 proportions은 sub-figures에서 보여줍니다. 놀랍게도, delta = 1인 두 frames의 해당 objects의 proportions는 거의 70%와 55%에 가깝고 delta=2인 두 frames의 해당 objects의 proportions는 58%와 39%에 가깝죠. 이 말은 즉, video는 frame에서 specific location에 object를 볼수 있다면, video가 인접한 frame에서 같은 locationdp 같은 object역시 볼 수 있을 가능성이 높다라는 것이죠. 그럼으로, 3D cov layers를 사용하는 것이 실행가능한 일이라는 말과 같죠. Fig 3은 delta가 증가하면 proportion이 많이 감소함을 보여줍니다. 사실, 이는 temporal coherence가 video의 time interval이 증가하면 감소하기 때문이죠.
Clip-in Clip-out One-stage VIS
clip에서 strong temporal coherence는 naive 3D convlayer가 objects의 spatio-temporal semantic information을 extract하는데 사용될 수 있음을 암시합니다. Fig2(b)에서 보여지는바와 같이, one-stage framework 기반 FiFo 에 많은 추가적인 storage overhead 없이 clip by clip으로 instance masks를 generating하는 capapbility를 부여하기 위해, 저자들은 backbone과 FPN을 바꾸지 않았죠. 이는 즉 multi-scale feature maps를 추출하는데는 변함이 없음을 뜻합니다. 오직 2D conv layers를 3D conv layers로 바꿨다는 것이죠. 이는 spatio-temporal information을 추출하고요. clip-level prediction heads와 clip-levelmask head라고 부릅니다.
Clip-level prediction heads( CPH )
Fig 2(c)에서 보여지는 바와 같이, CPH는 세 개의 branches로 구성되어 있고 각각은 c class confidences, d embedding vectors, 4T bounding box regression coordinates와 k' mask parameters를 예측하죠. 각 branch는 prediction tower로 구성되어 있는데 4개의 conv layers과 final prediction layer를 가지고 있습니다. object bounding box regression과 mask parameter prediction은 location-sensitive하기 때문에, 공유된 prediction tower를 사용하고 prediction tower는 feature consistency를 유지합니다. short-term temporal coherence로부터 Benefiting하기 때문에, short video clip 에 걸쳐 object의 box-level predictions는 temporal consistency를 유지합니다. 따라서, 저자들은 short video clip에 걸쳐 object에 대해 shared box-level predictions를 적용할 수 있죠. 3D conv layers를 가진 CPH에서 이 branches에 대해, 저자들은 all frames의 FPN features를 쌓습니다. 이는 clip에 대해 temporal dimension으로 쌓고 이는 input으로써 spatio-temporal feature를 형성합니다. batch dimension에서 FPN features는 직접 쌓습니다.
Clip-level mask head ( CMH )
CMH의 architecture는 Fig2(c)의 bottom에 보여지죠. 이는 original mask head만을 inflates한 것인데요. 이는 단지 3D conv layers를 도입한 것이죠. CMH는 spatio-temporal features를 embed 되는 3x3x3 filters와 input frame의 1/4로 samling할 deconvolutional layer, channels을 C에서 k로 줄여줄 1x3x3 and 1x1x1 3D conv layers를 가진 3개의 3D conv layers를 포함합니다. CMH의 input은 multi-scale feature maps의 sum이고 resolution은 convolution 이후 upsampling하여 계산합니다. resolution은 FPN layer의 p3과 같습니다. output은 clip-level mask features의 set인데 P^l이고 clip-level prototypes라고 불립니다. temporal coherence 때문에 clip-level prototypes은 temporal dimension을 따라 structural homogeneous하죠.
Clip-level mask generation
object의 bounding boxes는 각각 심하게 overlap되고 locate instances에 사용되기 때문에, 각 single frame에서 bounding boxes를 replace하기 쉽고 그렇게 활용 가능하죠. 저자들은 t frame에서 i-th object의 bounding boxes를 B^t_i = [ x^t_i1, y^t_i1, x^t_i2,y^t_i2 ]로 표기합니다. 앞의 두 element와 뒤의 두 element는 upper-left pixel과 bottom-right pixel입니다. circumscribed boxes는 아래와 같이 계산됩니다.

그런 다음, clip-level instance masks M^l_i 는 l clip의 i-th instance를 뜻하고 box-level predictions와 clip-level prototypes P^l을 compacted FCN에 넣어줌으로써 얻을 수 있죠. FCN은 dynamic convolutions를 가지고 있고 weights와 bias는 mask parameters로 구성됩니다. FCN의 all dynamic convolutions는 1x1x1 filters 입니다. 구체적으로, FiFo approach Yolact의 FCN architecture를 확장하여 clip-level instance masks는 아래와 같이 계산될 수 있으며 Tx 2h_3x 2w_3 의 demension을 가진 i-th instance의 clip-level instance masks는 CiCo-Yolact로 불립니다.
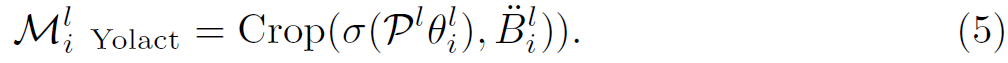
FiFo based approach CondInst를 확장하여 clip-level instance masks는 CiCo-CondInst로 불리며 아래와 같이 공식화 됩니다.
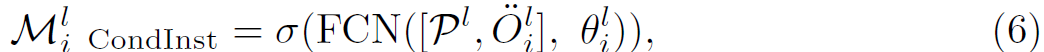
O^l_i ( R ^ Tx 2h_3 x 2w_3 x 2 )는 clip-level circumscribed bounding box의 centeral point (x^l_i,y^l_i ) 로 P^l에 대해 모든 locations로부터 relatvie coordinates의 map을 의미합니다. Figs 2 (d3) 과 (d4)는 clip-level instance mask generation의 schematic diagrams를 보여줍니다. CiCo-Yolact와 CiCo-CondInst 각각말이죠.
Sample matcher
different aspect ratios와 scales를 가진 Several anchors는 anchor-based detectors에 대해 FPN feature의 each position에서 predefined 됩니다. training 동안, anchor와 ground-truth bounding box간의 IoU 가 preset threshold보다 크다면 corresponding anchor는 positive sample이라고 불립니다. anchor와 groundtruth bounding boxes 간의 IoU가 certain threshold보다 작다면 anchor는 background로 할당되고 negative sample이라고 불립니다. adjacent frames의 contents는 매우 coherent하기 때문에 인접한 두 frame 간 object displacement는 매우 작죠. circumscribed boxes를 사용해 postive and negative sample을 match하고 해당 boxes는 richer spatio temporal features에 도달 하는 larger anchors를 선택할 수 있게 되죠. 그러는 동안, objects는 frame interval increases때문에 larger motions를 가지기 때문에 저자들은 그들의 circumscribed boxes를 계산한 current frame, previous frame, 그리고 next frame 의 bounding boxes를 적용합니다.
Overall Architecture
Training
저자들은 delta frames를 연속적으로 sample합니다. query frame 전후로 말이죠. 2delta+1 frames의 clip을 형성합니다. 먼저 그것을 CiCo에 input으로 넣습니다. 그러면 box-level predictions을 CPH로 부터 얻고 clip-level prototypes를 CMH로 부터 얻습니다. 그리고 positive and negative samples를 circumscribed boxes에 의해 match합니다. smmoth L1 loss와 CE loss를 bounding box regreesion과 classification에 각각 적용합니다. 식은 아래와 같습니다.
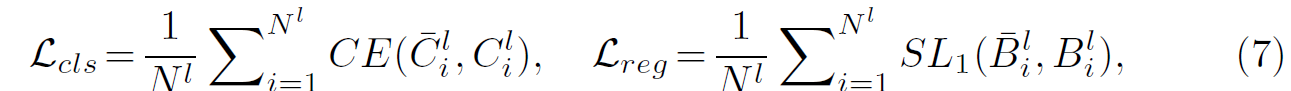
여기서 N^l = N^l_pos + N^l_neg 는 positive and negative samples의 총 수를 말합니다. bar * 는 그에 해당하는 ground-truths items를 나타냅니다. postivie samples에 대해, 저자들은 desired clip-level instance segmentation을 eq 5와 6을 활용해 얻습니다. clip-level instance segmentation loss는 BCE loss에 기반하며 식은 아래와 같습니다.

두 positive samples의 embedding vectors에 대해 consine similarity 에 기반하고 식은 아래와 같습니다.
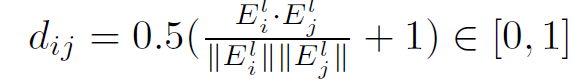
tracing loss는 아래와 같이 쓰여집니다.

마지막으로, total loss funtion은 아래와 같습니다.

Inference
inference 동안, 저자들은 input video를 several clips로 나눕니다. 2delta + 1 frames의 interval을 가지죠. 각 clip의 모든 frames는 CiCo 에 input으로 주어져 box-level predictions와 clip-level prototypes를 얻습니다. detection에서, 저자들은 class confidence 가 0.1보다 작은 object를 filter out하고 clip-level instance segmentation을 eq 5와 6을 활용해 생성합니다. 그들을 class confidence로 sorting한 후에, NMS를 사용해 중복된 object를 제거하고 clips에 걸서 clip-level online tracking strategy에 따라 objects를 link합니다.
Clip-level tracking
clip-level online tracking strategy는 inference 에서 사용됩니다. 처음 clip에 대해, 저자들은 detected instance에 IDs를 할당합니다. Y_ID = {1,...,N^1} 여기서 N^1은 처음 clip에서 detected instances의 number입니다. 따라나오는 clip에서 저자들은 predicted objects를 associate합니다. 이는 previous clip과 current clip간에 objects의 matching socres에 기반하죠. matching score는 cosine similarity와 mask IoU ( MIoU ) 그리고 bounding box IoU ( BIoU )를 합친것이며 식으로는 아래와 같죠

여기서 i,j는 (l-1)-th clip와 l-th clip으로부터 instance IDs를 표기합니다. alpha1, alpha2, alpha3은 hyperparameters입니다. current clip에서 j-th instance에 대해 만약 이전 clip에서 모든 object와 computed 된 its highest matching score가 certain threshold보다 크다면 previous clip에서 해당 instance의 ID가 계승됩니다. 반대의 경우는 새로운 객체로 ID |Y_ID|+1 의 ID를 부여받게 되죠.
여기까지 할게요. 그럼 이만
요즘 개발일정이 빡빡해서 논문을 뜨문뜨문 쓰네요
그럼 다음에 뵈



