Abstract
Two-branch network architecture는 efficiency와 effctiveness를 real-time segmentation tasks에서 보여 왔죠. 그러나, low-level details와 high-level semantics의 직접적인 fusion은 detailed features가 contextual information을 둘러싸임으로 인해 쉽게 압도되어지는 현상을 야기할 수 있죠. 이 현상을 overshoot이라고 이 논문에서 부르는데요, 이는 존재하는 two-branch models의 acuuracy의 improvement를 제한하죠. 이 논문에서, 저자들은 CNN 과 PID ( proportional-Integral-Derivative) 간의 connection을 이어줍니다. 그리고 two-branch network가 proportional-Integral ( PI ) controller에 불과하다는 것을 알아내죠. 이는 본질적으로 overshot과 유사한 문제로 골머리를 썩고요. 이 문제를 완화하기 위해, 저자들은 새로운 three branch network architecture: PIDNet을 제안합니다. PIDNet은 세 개의 branches를 갖는 데, 각각 detailed, context 와 boundary information을 분석하는 역할이죠. 그리고 detailed 와 context branches를 마지막 stage에서 fusion하도록 이끄는 boundary attention을 사용합니다. PIDNets의 family는 inference speed와 accuracy 간의 best trade-off를 달성하죠. 그리고 test accuracy는 SOTA를 이룩합니다.
1. Introduction
propotional-Integral-Derivative ( PID ) controller는 전통적인 concept인데요 지난 세기에 제안되었고 modern dynamic systems나 robotic manipulation, chemical process, power system 같은 processes에 광범위하게 사용되어왔죠. better control performance를 가진 많은 advanced한 control strategies 최근에 개발되어 왔음에도, PID controller는 여전히 많은 industry applications에서 가장 먼저 선택되죠. 이는 PID controller가 간단하지만, robust한 특성이 있기 때문이고요. scientific 분야에서 classic한 concept은 다른 많은 분야로 확장될 수 있었죠. 예를 들어보면, PID의 underlying methodology 는 image denoising, stochastic gradient decent 그리고 numerical optimization에 도입되었고 original methods를 뛰어넘는 엄청난 향상을 달성했죠. 이 논문에서, 저자들은 deep neural network architecture를 design하죠. 이는 real-time semantic segmentation task를 위한 network고 PID controller의 기초적인 concept을 사용하죠. 이 새로운 model의 성능은 이전 모든 network를 능가합니다. 더불어 best trade-off를 달성하죠. 이는 아래 Fig 1에 나와있고요.

Semantic segmentation은 visual scene parsing을 위한 기본적인 task인데 목적은 specific class label을 each pixel에 할당하는 것이죠. 인공지능의 점진적인 수요 증진과 함께, accurate semantic segmentation은 자율주행, medical imaging diagnosis 그리고 remote sesing imagery와 같은 다양한 분야에 기초적인 perception component가 되었죠. FCN을 시작으로 deep learning approaches는 점진적으로 semantic segmentation field를 장악했고 많은 대표적인 models들이 제안되었죠. 이 learning models의 development는 satisfactory segmentation performance를 가진 network architectures는 large scale에서 important detailed information의 손실 없이 pixels 간의 contextual dependencies를 학습하는 capability를 반드시 가져야한다는 것을 알려줬죠. 이 models가 encouraging segmentation accuracy를 달성했지만, 너무 많은 space와 time complexity가 필요하죠. 이는 real-time case에 적용하는 데 상당한 제약이 있죠.
real-time이나 mobile requirements를 만족하기 위해, researchers은 efficient하고 effective한 models들을 생각해냈죠. 구체적으로, ENet은 inference speed에서 엄청난 향상을 달성했는데 lightweight decoder와 초기 stages에서 feature maps를 downsampling 함으로써 달성했죠. ICNet은 small-size input을 semantics를 분석하는 complex하고 deep path 에서 encoded 합니다. 그러고 나서 large-size inputs으로부터 details를 encode하는 shallow하고 simple path를 사용했죠. MobileNetv2는 traditional convolutions를 depthwise separable convolutions로 대체 했는데, depthwise separable convolutions는 전체 model complexity를 줄여주죠. MobileNetv2 는 regularization effect를 완화해주는 inverted residual block 역시 제안했죠. 이런 초기 연구는 latency와 memory 사용을 줄이는 데 거대한 공헌을 했죠. 그러나 너무 낮은 accuracy는 real-word application에 제약이 되었죠. 최근 two-branch network에 기반한 models가 제안되었고 SOTA performance를 달성했죠. 물론 속도와 정확도 역시 모두 고려되었고요.
이 논문에서, 저자들 tow-branch networks를 PID controller의 관점으로 깊게 분석했고 two-branch network는 단지 PI controller에 불과하다는 것을 지적하죠. 그리고 two-branch network는 본질적으로 overshoot issue로 부터 골머리를 썩죠. 이는 Fig2에서 설명합니다.
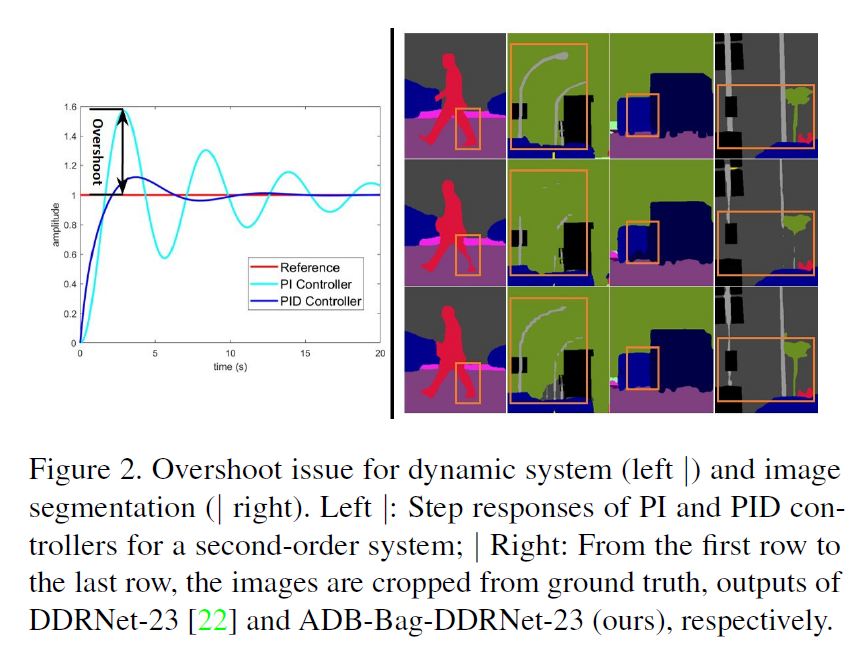
이 문제를 완화하기 위해, 저자들은 새로운 three-branch network architecture를 설계했고, PIDNet으로 부르죠 ( Proportional-Integral_derivative Network). 이 network는 boundary detection을 위한 추가적인 branch를 가지죠. 저자들은 PIDNet의 performance를 STOA models들과 비교했고 우월함을 보여주었죠. 저자들이 한 기여를 3가지로 요약해보자면,
1. 저자들은 PID controller를 가진 deep learning models 간에 다리를 놓고 PID controller architecture에 기반한 three branch networks를 제안합니다.
2. selective-learning-based connction, fast context aggregation module, 그리고 boundary-guided fusion module을 PIDNets의 성능을 boost하기 위해 제안하죠.
3. SOTA 성능을 달성했습니다.
2. Related Work
real-time과 ordinay cases 에 대한 network design 철학이 상당히 다르기 때문에, 저자들은 두 case에 대해 간략하게 소개한다고 하네요
2.1. High-accuracy Semantic Segmentation
semantic segmentation에 대한 초기 deep learning approaches 중 대다수는 encoder-decoder architecture에 기반했죠. encoder는 점진적으로 receptive field를 strided convolutions나 pooling operations를 cascading 함으로써 확대해 나가고 decoder는 detailed information을 high-level semantics로부터 deconvolutions나 upsampling을 사용해 recovers하죠. 그러나, spatial details는 encoder-decoder network에 대해 downsampling의 process에서 쉽게 ignored 될 수 있죠. 이 문제에 대해, dilated convolution이 제안되었죠. 이는 field-of-view를 spatial resolution 감소 없이 증가시킬 수 있죠. 이에 기반해, DeepLab series는 different dilation rates를 가진 dilated convolutions을 활용해 엄청난 성과를 이뤘죠. DeepLabs에 대해 critical problem은 dilated convolution이 current hardware에 적합하지 않은데 이는 수 많은 non-contiguous memory accesses 때문이죠. 이 문제를 해결하기 위해, PSPNet은 Pyramid Pooling Module ( PPM )을 도입합니다. 이는 multi-scale context information을 분석하죠. HRNet은 multiple paths를 적용합니다. 더불어 different scale representations를 fuse하고 학습하는 bilateral connections 역시 적용하죠. self-attention mechanism의 context aggregation power로 부터 영감받아, non-local operation이 computer vision에 도입되었고 의미있는 많은 연구를 야기했죠.
2.2. Real-time Semantic Segmentation
inference speed와 accuracy 간의 best trade-off를 달성하기 위해, researchers 들은 network architectures를 redesign 하는데 많은 노력을 기울였죠. 이를 요약해보면, lightweight encoder 와 decoer ( convolution factorization or group convolution ), multi-scale input 과 two-branch network 로 요약되죠. 구체적으로 SwiftNet은 high-level semantics를 obtain하는 하나의 low resolution input과 sufficient details를 lightweight decoder에 제공하는 다른 high-resolution을 사용합니다. DFANet은 light-weight backbone을 도입하는 데, 이는 Xception의 architecture를 변형한 것이죠. depth-wise separable convolution을 기반으로 하고 더 빠른 inference speed를 위해 input size를 줄이죠. ShuffleSeg 는 ShuffleNet을 적용합니다. channel shuffling과 group convolution을 combined했죠. 이는 computational cost를 reduce하는 backbone으로 사용하기 위함이었고요. 그러나 이들 network의 대다수는 여전히 encoder-decoder architecture이고 information flow가 deep encoder를 지나 decoder를 통과하여 돌아오기를 요구합니다. 이런 모델들은 much latency가 존재하죠. 게다가, GPU에서 depthwise separable convolution 에 대한 optimization이 mature하지 않기 때문에, traditional convolution 이 faster speed를 보여주죠. 물론 traditional convolution이 more FLOPS와 parameters 를 가짐에 불구하고 말이죠. ( 음.. 제가 이 분야에 있어서 느낀바지만 사실 이래서, parameter와 FLOPs를 기준치로 제시하는 것은 올바르지 않아요. 하드웨어에 따라 최적화된 layer의 존재 여부가 더 중요하죠 )
2.3. Two-branch Network Architecture
이전 section에서 설명한 바와 같이, contextual dependency는 large receptive field로 부터 extracted 될 수 있죠. 그리고 spatial details는 precise boundary delineation과 small-scale object recognition을 위해 필수적이죠. 이런 고려사항을 활용해, BiSeNet은 two-branch network architecture를 제안합니다. 이는 context embedding과 detailed information과 context를 fuse하는 Feautre Fusion Module ( FFM ) 가지고 detail parsing 을 위한 다른 depth를 가지는 two branches를 가지죠. 그런 다음, 몇몇 연구는 이 architecture에 기반하는데 그들은 BiSeNet의 representation ability를 증가시키거나 model complexity를 감소시키는 방향으로 연구되었죠. 특히, DDRNet은 bilateral connextions를 도입하는데 이 connections는 context와 detailed branches간의 information exchange를 강화하죠. 그리고 SOTA를 real-time semantic segmentation에서 달설하게 됩니다. 그럼에도 불구하고 detailed branch 를 위한 output size는 DDRNet에 포함된 context branch에 8배나되죠. ( BiSeNet은 4배입니다. ) 그리고 그들의 direct fusion은 필연적으로 object boundary가 surrounding pixels에 의해 쉽게 뭉개지고 small-scale object가 인접한 large objects에 의해 overwhelmed 되는 현상이 발생하고 이 논문에서는 해당 현상을 overshoot이라 표현하죠. overshoot issue를 완화하기 위해, 저자들은 PID concept을 빌려오는데 이는 automation engineering field에서 사용되죠. 따라서 PIDNet은 3개의 branch로 구성된 network achietecture입니다. 간략하게 보충해 설명하자면 boundary extracion을 위한 additional branch를 도입하고 context와 detailed features의 fusion을 supervise하는 boundary를 사용하죠.
3. Method
PID controller 는 three componets를 포함합니다. 이는 상호보완적인 capabilities를 가지죠. Proportional( P ) controller 는 current error를 represents하죠. Integral( I ) controller는 previous error를 acuumulates합니다. Derivative( D ) controller는 error의 future change를 predicts하죠. 이는 Figure 3에서 볼 수 있습니다. Figure 3에서 설명하지만, P, I , D 는 각각 detailed, context, boundary branch를 각각 의미하죠.

따라서, PID controller의 output은 entire time domain에서 error에 기반해 생성되죠. 대게, PI controller는 setpoint contorl scenarios를 대부분 만족할 수 있죠. 그렇지만 본질적으로 overshoot issue를 겪습니다. dynamic response를 위해, researchers는 Derivative controller를 도입하는 데, 이는 overshoot이 일어나기 전에 control output을 적용하고 prediction을 make하죠. two-branch network에서, context branch는 pixcels간의 long-range dependencies를 parse하는 strided convolution이나 pooling layers를 cascading함으로써 semantic information을 aggregate local에서부터 global area까지 constalntly하게 aggregate하죠. 반면에 detailed branch는 high-resolution feature maps를 유지하는데 이는 each pixel에 대한 semantic과 localization information을 preserve 하죠. 따라서, detailed와 context branch는 spatial domain에 대해 Proportional과 Integral controllers로 볼 수 있죠. segmentation의 overshoot issue를 합리적으로 설명됩니다.
3.1. PIDNet: A Novel Three-branch Network
overshoot issue를 mitigate하기 위해, 저자들은 Auxiliary Derivative Branch를 provide 하기를 제안하죠. PID controller를 spatial domain에 대해 완전히 모방하죠. 각 object 안의 pixels을 위해 semantics는 consistant하고 dlswjq object의 boundary를 따라서만 inconsistant하죠. 따라서 semantics의 derivative는 object boundary에서만 오직 nonzero입니다. 그리고 ADB의 function은 boundary detecion 이어야 하죠. 따라서 저자들은 three-branch real-time semantic segmentation architecture를 설계합니다. 이는 Figure 4에서 볼 수 있죠.

PIDNet은 three branches를 가지죠 이는 상호보완적인 responsibilities를 가집니다: Proportional ( P ) branch는 detailed information을 high resolution feature map에서 preserve하고 parse하죠; Integral ( i ) branch는 context information을 locally하고 golbally하게 aggregates하는데 long-range dependencies를 parse하죠; Derivative( D ) branch는 high-frequency features를 extracts하는 데 이는 boundary regions를 predict합니다. 전체 network는 기존 연구를 토대로 개발되었고, cascaded residual blocks가 backbone으로 적용되었죠. 이는 hardware-friendly 한 architecture이고요. 게다가, P, I 그리고 D branches에 대한 depths 는 moderate, deep and shallow하게 scheduled되는데 이는 해당 task를 위한 complexity를 고려하는 효율적인 implementation이죠. 또한, PIDNets의 family는 deepning하고 widening한 모델로 generated됩니다.
저자들은 semantic head를 first Pag module의 output에 위치 시키는 데, 이는 extra setman loss l0를 생성하고 전체 network의 더 좋은 optimization을 위함이죠. dice loss 대신에, weighted binary cross entropy loss l1이 boundary detection의 imbalanced한 problem을 다루기 위해 적용됩니다. coarse bounday는 bounary region을 highlight하길 preferred 되고 small objects에 대해 features를 enhance하기 때문이죠. l2와 l3는 CE loss를 represents합니다. 반면 저자들은 boundary-awareness CE loss를 l3에 대해 사용합니다. 이는 semantic segmentation을 조정하는 Boundary head의 ouput과 boundary detection tasks에 사용됩니다. 또한 Bag module의 funtion을 enhance하죠. 식은 아래와 같습니다.

여기서 t 는 predefined thresold 를 뜻하고, b_i, s_i,c 그리고 hat s_i,c는 boundary head의 output, segmentation ground-truth 그리고 i-th pixel에 class c에 대한 prediction result를 각각 의미하죠. 그럼으로 PIDNet에 대한 final loss는 아래와 같이 요약되죠.

실험적으로, 저자들은 PIDNet의 training loss를 위해 parameter를 다음과 같이 set합니다. lambda_0 = 0.4, lambda_1 = 20, lambda_2 = 1, lambda_3 = 1 그리고 t = 0.8 이죠
3.2. Pag: Selective Learning High-level Semantics
lateral connection은 differenct feature maps간의 information transmission을 enhances하죠. 또한 models의 representation ability를 improve합니다. PIDNet에서 , 풍부하고 정확한 sematntic information은 I branch에 의해 제공되는데 이는 다른 두 개의 branch에대한 backup의 역할을 하죠. 두 branch에 필요한 정보를 제공함으로써 말이죠. 제공된 feature mpas를 직접적으로 더해주는 D branch와 다른점은. Pixel-attention-guided fusion module ( Pag )를 도입했다는 겁니다. 이는 Figure 5에서 확인 할 수 있죠.

overwhelmed없이 I branch로 부터 useful semantic features를 선택적으로 학습하는 P branch를 볼 수 있습니다. 기본적으로 Pag를 위한 기본적인 concept은 self-attention mechanism에서 빌려왔는데요. Pag는 real-time requirement를 만족하기 위해 locally하게 attention을 compute하죠. P branch( v_p)와 I branch( v_i )에 의해 제공되는 feature maps에서 해당 pixels을 위한 vector를 정의하면 sigmoid funcion의 output은 아래와 같죠.

여기서 sigma는 두 pixels가 같은 object로부터 나왔을 확률을 represents하죠. sigma가 높다면, v_i 를 더 신뢰하는데, 이는 I branch가 semantically 하게 정확하기 때문이죠. 따라서 Pag module의 output은 아래와 같이 쓸수 있죠.

3.3 PAPPM : Fast Aggregation of context
이전 construction 보다 더 낳은 결과를 위해, Spatial Pyramid Pooling( SPP ) 가 SwiftNet에 적용되었고 이는 global dependencies를 parse하죠. PSPNet은 Pyramid Pooling Module ( PPM )을 도입하는데, 이는 local and global context representations를 만들어주는 multiscale pooling map을 convolution layer 전에 concatenates합니다. Deep Aggregation PPM ( DAPPM )은 PPM의 context embedding ability를 더욱 향상시켰고, 뛰어난 성능을 보였죠. 그러나, DAPPM의 computation은 depth를 고려하면 parallelized 될 수 없죠. 이는 time-consuming을 의미하고 DAPPM은 각 scale에 너무 많은 channels를 가지고 있죠. 따라서 저자들은 DAPPM을 조금 바꿔 paralelized될수 있도록 했죠. 이는 Figure 6에 나타나 있습니다.

이는 각 scale을 위한 channels의 수를 128에서 96으로 줄였죠. 이 새로운 context harvesting module은 Parallel Aggregation PPM ( PAPPM )이라 부릅니다. 이는 PIDNet-m과 PIDNet-s에 적용되었고 speed 향상에 일조하죠. PIDNet-L에서는 여전히 DAPPM을 사용하지만 channels의 수가 128에서 112로 줄죠.
3.4. Bag: Balancing the Details and Contexts
ADB에 의해 추출된 boundary features가 주어지면, 저자들의 proposal은 detailed ( P )와 context ( I ) representations의 fusion을 guide하는 boundary attention을 사용하죠. 그럼으로, 저자들은 Boundary-attention-guided fusion module ( Bag )을 설계하는데 이는 three branches로부터 제공된 features를 fuse하죠. context branch는 semantically rich하고 더 acuurate semantic을 나태날 수 있죠 그러나 너무 많은 spatial 과 gemoetric details를 잃어버리고 특히 boundary region과 small object에 대해서는 더욱 두드러집니다. detailed branch 덕분에, spatial details를 더잘 보전합니다. 저자들은 model이 boundary region을 따라 detailed branch를 신뢰하도록 하고 object 내부를 채우는 context feature를 사용하죠. 이는 Figure 7의 Bag릁 통해 성취됩니다.

Figure 7에 대해 vectors를 정의하면, (a) Bag의 구현과 (b) Light-Bag의 구현이 module로 보여지죠. P, I 그리고 D는 각각 detailed, context 그리고 boundary branches의 output을 나타내죠. sigma는 Sigmoid function의 output을 표기합니다.
P,I 그리고 D braches 에서 해당 pixels는 각각 v_p, v_i, 그리고 v_d로 표기되죠. 그러면 Bag과 LIght-Bag에 대한 각각의 Sigmoid의 outpus은 아래와 같이 나타나죠.

f는 convolutions, batch normalizations 그리고 ReLUs 의 composition을 나타냅니다. 비록 저자들이 3 x 3 convolution을 두 개의 1 x 1 convolutions로 Light-Bag에서 바꾸지만, Bag과 Light-Bag의 functionalities는 유사하죠.
뒤의 부분은 생략합니다.
많은 논문을 리뷰해드리고 싶은데
한 3 달간 진짜 이게맞나 싶을 정도로 바쁘네요.
그럼 다음글에서 뵙겠습니다.


