Abstract
Test-time domain adaptation은 source pretrained model을 target domain에 source data 없이 adapt하는 것을 목적으로 합니다. 현존하는 연구는 주로 target domain이 static한 경우를 고려합니다. 그러나, real-world machine perception systems는 non-stationary 으로 동작하고 target domain distribution이 시간에 따라 지속적으로 변하죠. 현존하는 모델은 대게 self-training과 entropy regularization에 기반하는데 이런 non-stationary한 환경으로부터 어려움을 겪습니다. target domain에서 시간에따라 distribution이 바뀌기 때문에, pseudo-labels는 믿을만하지 않게되죠. 이 noisy pseudo-labels는 error accumulation과 catastrophic forgetting을 야기할 수 있습니다. 이 문제들을 다루기 위해, 저자들은 continual test-time adaptation approach( CoTTA )를 제안하는데 두 개의 부분으로 구성되어 있죠. 먼저, 저자들은 error accumulation을 weight-averaged and augmentation averaged prediction을 사용함으로써 줄일 것을 제안하죠. 이는 대게 더 정확하고요. catastrophic forgetting을 피하기 위해서 저자들은 long-term관점에서 source knowledge를 보존하는데 도움을 주는 source pre-trained weights 로 neuron의 small part를 각 iteration 동안 stochastically하게 restore합니다. 제안된 방법은 long-term adaptation을 가능하게 하죠. CoTTA는 구현하기 쉽고 off-the-shelf pre-trained models에 쉽게 incorporated 될 수 있습니다. 저자들은 자신들의 방볍을 4 개의 classification tasks와 하나의 segmentation tasks에서 effectiveness에 대해 보여주었습니다. 결과는 현존하는 방법들을 뛰어넘었죠.
Introduction
Test-time domain adaptation 은 unlabeled test data로부터 inference time 동안 학습함으로써 source pretrained model을 adapt 하는 것을 목표로 하는데요. source training data와 target test data간의 domain shift 때문에, 좋은 성능을 위해서 adaptation이 필수불가결하죠. 예를 들면, semantic segmentation model이 clear weather에서 학습되었다고 했을 때, 눈이오는 밤의 환경에서 심각한 성능 저하가 있을 수 있죠. 유사하게, pre-trained image classification model은 sensor degradation으로부터 도출된 corrupted images에서 test하게 되면 심각한 성능저하를 겪을 수 있습니다. privacy concerns나 legal constraints 덕분에, source data는 inference time동안 사용할 수 없는 것으로 고려되는 것이 일반적이죠. 이는 unsupervised domain adaptation보다 문제를 더 challenging하게 만들고 더 realistic하게 만들죠. 많은 시나리오에서, adaptation은 online fashion으로 수행될 필요가 있죠. 따라서 test-time adaptation은 domain shift가 발생하는 환경에서 real-world machine perception의 성공에 필수적이죠.
현존하는 연구는 대게 source domain과 fixed target domain간의 distribution shift를 다루는데 이는 model parameters를 pseudo-labels나 entropy regularization을 사용해 업데이트함으로써 다루죠. 이런 self-training methods는 test data가 same stationary domain에서 도출되었을때 effective하다는 것이 증명되어왔죠. 하지만, 이들은 target test data가 지속적으로 변하는 환경으로부터 나왔을때는 불안정할 수 있죠. 이런 부분은 두 가치 측면 때문인데. 먼저, 지속적으로 변화하는 환경에서, pseudo-labels는 noisier나 mis-calibrated가 될수 있는데 distribution shift때문이죠. 두 번째로, model이 continually하게 new distribution에 adapted되기 때문에 source domain으로부터의 knowledge는 보존되기 어렵고 이는 catastrophic forgetting을 야기하죠.
지속적으로 변화하는 환경 속에서 이들 문제를 다루는 것을 목적으로 하기 때문에, 이 연구는 online continual test-time adaptation의 practical problem에 초점을 맞춥니다. Figure 1에서 보여지다시피, 목적은 off-the-shelf source pre-trained model으로부터 시작해서 current test data에 그것을 지속적으로 adapt하는 것이죠.

이런 환경에서, 저자들은 target test data는 지속적으로 변화하는 환경으로부터 나온다는 것을 가정합니다. prediction과 updates가 online으로 수행되죠. 그러는 동안 model은 source data나 full test data에 접근하지 않고 오직 current stream에만 접근하죠. 제안된 방법은 real-world machine perception systems와 관련이 있는데요. 예를 들어보자면, 주변 환경이 지속적으로 변화하는 자율주행과 같은 것들이 있겠죠. 그런 환경에서는 갑작스럽게 환경이 변할 수도 있죠. 갑자기 터널에 들어간다거나 하면요. perception model은 스스로 adapt해야하죠.
pre-trained source model이 변화하는 test data에 효과적으로 adapt 하기 위해서, 저자들은 continual test-time adaptation approach를 제안합니다. 이는 현존하는 모델의 두가지 한계점에 대해 다루고 있습니다. 첫번째는 error accumulation을 완화하는 것인데 pseudo-label quality를 self-training framework환경에서 두가지 방법으로 향상시킬 것을 제안합니다. mean teacher prediction이 standard model보다 대게 높은 quality를 가진다는 사실에 영감을 받아, weight-averaged teacher model을 사용하는데 더 정확한 predictions을 제공하죠. larger domain gap으로부터 어려움을 겪는 test data에 대해. 저자들은 augmentation-averaged prediction을 사용하는데 이는 psedo-labels의 quality를 boost하죠. soucre knowledge를 보존하고 forgetting을 피하기 위해 저자들이 제안한 방법은 pre-trained source model로 돌아와 network에서 neurons의 small part를 stochastically하게 restore하는 겁니다. error accumulation을 줄이고 knowledge를 보존함으로써 CoTTA는 long-term adaptation을 변화하는 환경에서 가능하도록하죠. 그리고 network의 모든 parameters가 학습 가능하도록 만들고요. 반면 현존해나는 연구들은 batchnorm parameters만 학습가능하죠.
저자들의 방법이 쉽게 구현가능하다는 것은 짚고 넘어갈 만합니다. weight-and-augmentation-averaged strategy와 stochastic restoration은 그 어떤 off-the-shelf pre-trained model과도 쉽게 통합될수 있고 여기에는 re-train할 필요가 없다는 것이 특징이죠. 저자들은 저자들의 방법의 effectiveness를 보여주기위해 4개의 classification tasks와 segmentation task에 대해서 보여주었고 현존하는 방법들을 뛰어넘었죠. 저자들의 기여를 요약하면 아래와 같습니다.
- 저자들은 continual test-time adaptation approach를 제안하는데 off-the-shelf source pre-trained models가 지속적으로 변화하는 target data에 effectively하게 adpat할 수 있게 합니다.
- 특히, 저자들은 error accumulation을 줄이는 데 weight-averaged and augmentation-averaged pseudo-lables를 사용합니다.
- long-term forgetting effect는 source model로부터 knowlede를 보존함으로써 완화됩니다.
- 제안된 방법은 continual test-time adaptation performance를 classification and segmentation benchmarks에서 상당히 향상시킵니다.
Related Work
Domain Adaptation
Unsupervised domain adaptation ( UDA )는 labeled source domain과 unlabeled target domain 간의 domain shift가 존재하는 상황에서 target model performance를 향상시키는 것을 목표로합니다. training 동안, UDA mehthods는 두 dominas간의 feature distributions을 discrepancy loss나 adversarial training을 사용해 align합니다. alignment는 input sapce에 수행됩니다. 최근, self-training이 유망한 결과를 보여줘 왔는데, network를 학습하는 gradually-improving target pseduo-labels를 사용한 결과이죠.
Test-time Adaptation
Test-time adaptation은 source-free domain adaptation 이라고도 불립니다. domain adaptation과는 다르게 test-time adaptation methods는 source domain의 어떤 data도 요구하지 않습니다. 몇몇 연구는 generative models를 사용하는데 source data가 없는 상황에서 feature alignment를 support하죠.
Another popular direction은 source model을 domain alignment를 수행하지 않고 finetune하는 겁니다. Test entropy minimization( TENT )는 pre-trained model를 가지고 test data에 adapt 하는데 entropy minimization을 사용하죠. Source hypothesis transfer ( SHOT )는 entropy minimization과 diversity regularizer를 사용하는데 adaptation을 위한 것이죠. SHOT은 weight normalization layer를 활용한 label-smoothing techinque을 사용하는 specialized source modle 을 train하는 source data를 사용하길 요구합니다. 따라서, 이는 임의의 pre-trained model을 사용하는 것을 support할 수 없습니다. 또 다른 연구에서는 input transformation module과 결합된 diversity regularizer를 적용할 것을 제안하고 이는 성능 향상으로 이어지죠. 한 연구는 separate normalization convolutional network를 사용합니다. 이는 새로운 domain으로부터 test images를 normalize 하죠. 또 다른 연구는 inference 동안 final classification layer를 pseudo-prototypes를 사용해 updates합니다. 다른 연구에서는 Bayesian perspective로 문제를 분석하고 test-time adaptation에 regularized entropy minimization procedure을 제안하는데 이는 training time에 density를 approximating하기를 요구하죠. target data를 사용하는 Batch Normalization layer에서 statistics를 updating하는 것은 또다른 스트림이죠. 현존하는 많은 방법들이 image classification에 초점을 맞추는 반면, 몇몇 연구는 test-time adaptation을 semantic segmentation으로 확장하죠. Standard test-time adaptation은 offline scenario를 고려하죠. 이 scenario들에서는 test data의 full set에 접근하고 training을 위해 제공되죠. 이는 online machine perception applications를 위해서는 비현실적입니다. TENT 를 제외한 현존하는 많은 방법들은 source model의 re-training을 요구하는데 이는 test-time adaptation을 support하기 위함이죠. 따라서 그들은 off-the-shelf pretrained model을 직접 사용할 수 없습니다.
Continuous Domain Adaptation
standard domain adaptation과 다르게, continuous domain adaptation은 지속적으로 변화하는 target data를 가진 adaptation problem을 고려합니다. Continuou Manifold Adaptation (CMA)는 domains를 evolving하는 adaptation을 고려하는 연구이고 Incremental adversarial domain adaptation( IADA ) 는 지속적으로 변화하는 domains에 source와 target feature를 aligning함으로써 adapts합니다. 한 연구는 source training data로부터 retaining없이 seen domain에 대해 forgeting하는 것을 완화하면서 unseen visual domain을 지속적으로 adapt하는 것을 목적으로 연구가 되었고 다른 연구는 gradually varying domains 간에 continuity assumption을 사용해서 gradually changing domains를 적용하였죠. 현존하는 continuous domain adaptation 방법은 source와 target domain모두로 부터 data에 access 해야할 필요가 있는데 이는 distributions를 align하기 위해서죠.
이 논문의 초점은 continual test-time adaptation인데 testtime에서 source data에 accessing없이 adaptation을 추가적으로 고려합니다. 이는 현실에서 machine qerception systems를 위해 realistic scenario이지만, 이런 scenario에 관한 연구는 거의 없죠. 이론적으로, TENT의 online version이 이 setup에 적용될수 있습니다. 이는 BN parameters를 entropy loss를 통해 updating함으로써 가능하고요. 그러나, 이는 error accumulation 때문에 골치를 썩는데 mis-calibrated predictions 때문이죠. Test-time training ( TTT ) 역시 지속적으로 feature extractor를 update하는데 ratation prediction auxiliary task로 부터 supervision을 사용하죠. 그러나, 이는 source model의 re-training을 요구합니다. auxiliary task를 학습하는 source data를 사용해야하죠. 그럼으로, 이는 source-free로 고려될 수 없고, off-the-shelf source pre-trained models를 support할 수 없습니다.
Continual Learning
Continual learning과 lifelong learning은 continuous adaptation problems와 관련이 있는데요. 이는 catastrophic forgetting에 대한 potential cure로써 관련 있죠. Continual learning methods는 replay-based 와 regularization-based methods로 분류되는데요, 후자는 다시 learning without foregetting( LwF) 와 같은 data-focused method와 elastic weight consolidation( EWC )와 같은 prior-focused mehods로 나눠지죠. continual learning으로부터의 Ideas는 continuous domain adaptation approaches에서도 적용됩니다.
Domain Generalization
이 연구는 domain generalization과도 관련이 있는데요. 변화하는 target domains에 대해 성능을 향상시킨다는 공통된 목표를 가지고 있죠. 많은 연구가 data augmentation이 model robustness와 generalizability를 향상시킬수 있다는 것을 보여줬죠. Domain randomization은 가장 인기있는 methods인데 model generalizability를 향상시켜주죠. 이는 동일 환경의 different synthesis parameters 학습함으로써 실현합니다. domain generalizable neural network과는 다르게 이 연구는 pre-trained neural networks를 unlabeled online data를 사용해 test-time 동안 performance를 향상시키는 데에 초점을 맞추죠.
Continual Test-Time Domain Adaptation
Problem Definition
f_theta_0(x) pre-trained model이 주어집니다. 이 model은 source data (X^s, Y^s)에대해 trained된 parameters theta를 가지고 있죠. 이 모델에 대해 inference time동안 performance를 향상시키는 것이 목표인데, target domain은 지속적으로 변하고 그 어떤 source data에 접근 없이 online fashion으로 향상시키는 것을 목표로 하죠. Unlabeled target domain data X^T는 sequentially하게 제공되고 model은 현재 step의 data에만 접근할 수 있습니다. time step t에 target data x^T_t 는 input으로 주어지고 model f는 prediction를 만들고 futrue inputs에 스스로 adapts되야합니다. data distribution은 지속적으로 changing됩니다. model은 online predictions에 기반해 평가됩니다.
이 setup은 지속적으로 변화하는 환경에서 machine perception applications의 needs에 동기를 부여받았죠. 예를 들면 처한 환경이 자율 주행과 같을 경우 location, wether, time등이 지속적으로 변하는 환경을 들 수 있겠죠. perception decision은 online으로 결정되어야 하고 models가 adapted되야합니다.
저자들은 자신들의 online continual test-time adaptation setup과 존재하는 adaptation setups의 주요한 차이를 list했고 그는 Table 1에서 볼 수 있습니다.
기존 setup과 비교하면, 저자들의 방법은 지속적으로 변화하는 환경에서 long-term adaptation을 고려했다는 것을 알 수 있죠.
Methodology
저자들은 online continual test-time adaptation setup을 위한 adaptation method를 제안합니다. 제안된 방법은 off-the-shelf source pre-trained model을 취해서 그것에 지속적으로 변화하는 target data에 adapt 합니다. error accumulation은 self-training framework에서 key bottleneck이라는 점에 영감을 받아 weight-andaugmentation-averaged pseudo-labels 를 사용하는데 이는 error accumulation을 줄이죠. 게다가 forgetting을 줄이는 것을 돕기위해, source model로부터 inforamtion을 preserve할 것을 제안합니다. 제안된 방법의 overview는 Figure 2에 나타나있습니다.
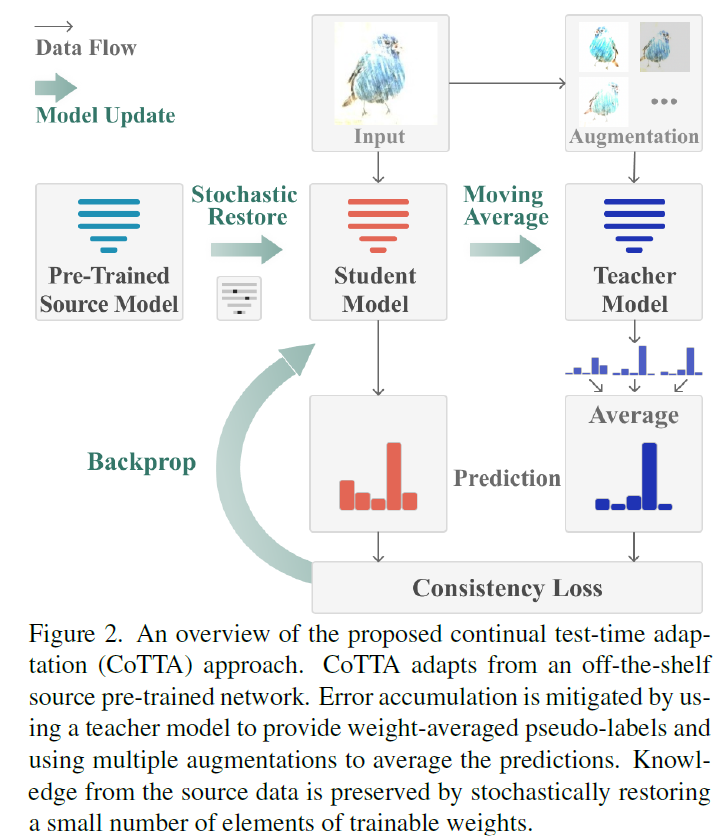
Source Model
현존하는 연구는 source model의 triaining process에서 sepcial treatment를 요구합니다. 이는 domain generalization ability를 향상시키고 adaptation을 facilitate하게 하죠. 예를 들면, source training 동안, TTT는 additional auxiliary rotation prediction branch를 가집니다. 이는 target adaptation supervision을 facilitate하기 위한 train을 하는 branch죠. 이는 souce data에대해 retraining을 요구합니다. 그리고 이는 pre-trained model이 reuse하는 것을 불가능하게 하죠. 제안된 test-time adaptation method에서 저자들은 이 burden을 남겨 놓습니다. 그리고 architecutre의 modification을 요구하지 않죠. additional source training process역시 요구하지 않습니다. 그럼으로, 어떤 pre-trained mdoels도 source에 대해 re-training 없이 사용될 수 있죠. 저자들은 실험에서 저자들의 방법이 다양한 범위의 pre-trained networks에서 동작하는 것을 보여줍니다.
Weight-Averaged Pseudo-Labels
target data 와 model이 주어지면, test-time objective는 prediction과 pseudo-label 간의 cross-entropy consistency를 최소화합니다. 예를 들면, model prediction 그 자체를 직접 pseudo-label로 사용하는 것은 training objective of TENT을 야기합니다. 이런 방법들은 stationary target domain에 대해서 잘동작하는 반면, continual changing target data에 대해서는 pseudo-labels의 quality 가 굉장히 떨어질 수 있는데 distribution shift 때문이죠.
weight-averaged model이 더 정확한 model을 제공한다는 관찰에 영감을 받아 저자들은 weight-averaged teacher model을 사용하는데 이는 pseudo-labels를 생성하죠. step t= 0 에서, teacher network는 source pre-trained network와 똑같이 초기화됩니다. time-step t에서 pseudo-label은 teacher에 의해 처음 생성됩니다. student는 crossentropy loss에 의해 updated 되는데 해당 loss는 student와 teacher predictions 간의 loss입니다. 식은 아래와 같습니다.

여기서 hat y'은 class c의 probability이고 teacher model's soft pseudo-label prediction에 대한 것이죠. hat y는 student 로부터의 prediction 입니다. loss는 teacher와 student predictions 간에 consistency를 적용합니다.
student model의 update 후에, teacher model을 update하는데 exponential moving average에 의해 update되고 student weights를 사용합니다.
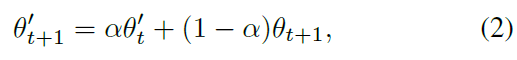
alpha는 smoothing factor입니다. final prediction은 hat y에서 highest probability를 가진 class입니다.
weight-averaged consistency의 이점은 두 가지입니다. 더 정확한 pseudo-label을 사용하기 때문에 error accumulation에 영향을 덜 받습니다. 그리고 teacher prediction은 past iterations에서 models의 information을 encodes합니다 따라서 catastropic forgetting에 영향을 덜 받죠.
Augmentation-Averaged Pseudo-Labels
training time 동안 Data augmentation은 model performance를 향상시키기 위해 널리 적용되어왔죠. Different augmentation policies는 manually하게 designed되거나 different datasets에 대해 searched 되죠. test-time augmentation은 robustness를 향상시킬 수 있다는 것이 증명되어왔고, augmentation policies는 일반적으로 specific dataset에 대해 determined되고 fixed됩니다. 이는 inference time 동안 distribution change를 고려하지 않죠, 지속적으로 변화하는 환경에서, augmentation policy를 만드는 것은 타당하지 않죠. 저자들은 test-time domain shift를 고려하고 prediction confidence로 domain difference를 approximate합니다. augmentation은 domain difference가 large할때만 적용되는데 error accumulation을 감소시키죠. 식은 아래와 같습니다.
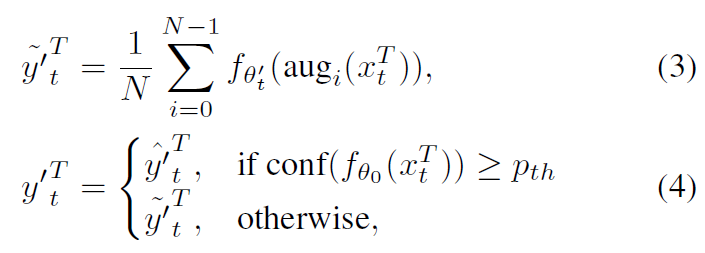
여기서 ~y'^T_t 는 augmentation-averaged prediction인데 teacher model로부터 파생되죠. hat y'^T_t는 direct prediction이고 역시 teacher model로 부터 나옵니다. conf( f_theta_0( x^T_t ) )는 source pre-trained model로부터 나온 prediction confidence인데 현재 input에 대한 confidence이죠. p_th는 confidence threshold 입니다. 저자들은 source와 current domain간의 difference를 approximate하고자 시도하는데 eq4에서 f_theth_0를 사용해 현재 input에 대해 prediction confidence를 계산하죠. 저자들은 lower confidence는 larger domain gap을 나타내고 상대적으로 높은 confidence은 smaller domain gap을 나타낼 것이라 가정합니다. 따라서, confidence가 높고 threshold보다 크다면, hat y'^T_t를 직접 pseudo-label로 사용하는데 aumentation은 하지 않습니다. 그러나 confidence가 낮으면, 저자드릉ㄴ N random augmentation을 적용하는데 이는 pseudo-label quality를 더욱 향상시키죠. filtering은 매우 중요한데, 저자들은 random augmentations가 small domain gaps를 가진 confident smaples에 대해 적용되면 model의 performance를 저하한다는 사실을 발견했기 때문이죠. 저자들은 이 현상에 대해 보충자료에서 다룬다고합니다. 요약하면, 저자들은 confidence를 사용하는데 domain difference를 approximate하고 언제 augmentations를 적용해야하는지를 결정합니다. student model은 아래와 같이 재 정의된 pseudo-label에 의해 update되죠.

Stochastic Restoration
더 정확한 pseudo-labels는 error accumulation을 완화할 수 있죠. self-training에 의한 continual adaptation은 errors가 축적되고 foregetting을 야기합니다. 이문제는 strong domain shifts를 만나면 strong distribution shift 가 mis-calibrated를 일으키죠. Self-training은 이 상황에서 wrong predictions를 강화합니다. 더 최악인 것은 이런 상황을 만난 이후입니다. model은 복구될 수 없는데 continual adaptaion 때문이죠.
이 문제를 다루기 위해, 저자들은 stochastic restoration method를 도입합니다. source pre-trained model로부터 knowledge를 restore하는 것이죠.
step t에서 Equation1에 기반해 gadient updat 일어난 student model f_theta의 convolution ralyer를 고려해봅시다. 식으로는 아래와 같죠.
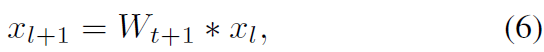
여기서 *는 convolution operation을 표기합니다. x_l과 x_l+1은 input과 ouput을 표기하죠. W_t+1은 trainable convolution filters를 표기합니다. 제안된 stochastic restoration method는 weight를 아래의 식으로 update합니다.

여기서 dot 는 element-wise multiplication을 의미합니다. p는 small restore probability를 뜻하고 M은 mask tensor인데 W_t+1과 같은 shape이죠. mask tensor는 W_t+1에 어떤 element가 source weight W_0에 restore back 될지를 결정합니다.
Stochastic restoration은 Dropout의 특별한 형태로 볼 수 있습니다. stochastically하게 restroing하므올써 적은수의 tensor elements가 원래 weight로 초기화되고 network가 초기 모델가 너무 멀어지는 것을 막아줍니다. 게다가, information을 보전함으로써 all trainable parameters를 model collapse 걱정없이 학습시킬 수 있습니다. 이는 adpatation을 위한 capacity를 증대시킵니다.
Algorithm1에서 볼수 있다시피, refined pseudo-labels와 stochastic restoration을 결합하는 것은 저자들의 online continual test-time adpatation method를 가능하게 하죠.

오늘은 여기까지 하겠습니다.
갑자기 왠 adaptation이냐 할 수 있겠지만,
이제는 detection, segmentation, tracking, analysis를 벗어나
폭 넓은 논문 역시 다루고자 합니다.



