안녕하세요 WH입니다.
앞 글에서는 related work까지 다루어 보았죠?
2022.05.30 - [AI 논문] - [ 꼼꼼하게 논문 읽기 ] ViViT : A Video Vision Transformer 1
[ 꼼꼼하게 논문 읽기 ] ViViT : A Video Vision Transformer 1
안녕하세요. WH입니다. 오늘 논문은 goole에서 21년에 발표한 vivit라는 논문인데요, 함께보시죠. 내용 요소는 문단별 요약 그리고 한줄 요약으로 구성하겠습니다. 이게 쓰다보니까 너무 길어질거
developer-wh.tistory.com
거두절미하고 vision transformer 요약부터 이어나가도록 하겠습니다.
이번 글은 문단별로 읽고 그대로 옮기는 것보다 해당 문단을 독해가 아닌 해석하도록 할게요.
Overview of Vision Transformer
VIT은 앞 글에서 간단하게 언급한 바와 같이 2D 이미지 처리에 transformer를 적용한 아키텍처입니다. VIT은 겹치지 않는 N개의 이미지 patch를 뽑는데요,
해당 패치를 X_i라 할 때, demension은 아래와 같습니다.

그리고 각 패치들을 linear projection 하고 rasterise 하여 z로 만들어주게 됩니다.
즉 z_i 는 d로 demesion이 바뀌는데요
즉 패치 x가 z로 되는 것을 말합니다. z식은 아래 그림과 같습니다.
그런데 이 논문은 이 부분만을 봐서는 VIT을 알고 있다고 가정하는 것 같습니다. 때문에 위 정도의 식만을 가지고 설명을 하는데요. 조금 자세하게 다뤄보도록 할게요. 식만 가지고는 너무 불친절하니까요.
우선 VIT 구조에요,
맨 오른쪽 하단의 이미지의 높이를 H, 넓이를 W 라고 하겠습니다. 이를 N으로 나눠주게 되는데요, 즉 H * W 의 이미지 한장이 N * N 개로 분할 되었다고 생각하시면 됩니다. 그 다음 이 N * N 의 나눠진 사진 각각을 patch라고 합니다. 이 덩어리를 가지고 linear projection을 하게 된답니다. 그런데, 이 때 output의 demension size를 조절해주기 위해 E를 곱해줍니다. 이 E는 embeding이라고 하는 데, CNN과 비교하면 이 부분이 convolution의 역할을 합니다. 다만 다른 점은 이것은 Demension을 맞춰주는 역할을 한다는 겁니다. 공간적 정보를 학습하기 위해서는 패치가 몇 번째 있었는지에 대한 정보가 필요하고 이는 p를 더해줌으로써 그에 대한 정보를 주는 대요 z 식의 + p 에서 p가 positional embeding으로 위치 정보를 포함하게 됩니다. 또한 맨 앞에 z_cls 라는 token을 추가해 주는데 이는 classificiation을 위한 token이라고 생각하시면 되겠습니다. VIT에서는 transformer encoder를 통과한 후 계산되 z_cls token( d demosion을 가지는 )을 가져와 MLP 에 넣어 class가 무엇인지 알아낸다고 생각하시면 됩니다. 그 다음 왼쪽에서는 transformer encoder의 구조를 보여주고 있습니다. 어떻게 z_class token을 계산하느냐 하면 우선 z를 embeded pathch라고 부릅니다. 이 input을 transformer encoder에 넣으면 가장 먼저 layer normalize해 줍니다. 그 다음 key, query, value가 들어가 multi-head attention이 나오게 됩니다. 각각의 식은 w가 곱해지는 linear 연산으로 이뤄지는 데, 어떤 의미를 갖는가 하면, query와 key에 대한 유사도를 계산해 높은 유사도에 해당하는 value값을 가져오는 방식입니다. 즉 어떤 부분이 유사하며 그 유사 부분의 value를 던져주는 이 output을 attention이라고 하는데요. attention은 통해 우리가 가지고 있는 이 이미지와 정답 사이에서 주목해야할 특징을 알려주는 역할을 한다고 생각하시면 됩니다. multi head attention이라는 말은 여러 측면에서 그 이미지를 바라보아라라는 의미가 되겠지요. 거기에 skip connection을 해주는 데, 이는 backpropagation 연산 시 연산을 단순하게 하여 학습을 잘되게 하기 위함이라고 보시면 되겠습니다. 이후 다시 normalize해주고 encoder를 통과한 z_cls token을 가지고 MLP를 거쳐 class가 나온다고 생각하시면 되겠습니다. 참고로 MLP는 2개의 linear projections이 있으며 activation으로는 gelu를 사용합니다. gelu는 가우시안 분포를 이용한 activation fuction인데 모양은 relu와 비슷하지만, 0근처에서 아래로 볼록하고 linear한 부분이 약간 곡선의 형태를 띈다고 생각하시면 되겠습니다. 간략하게 설명하였는 데, 자세한 내용은 추후 VIT 논문을 다룰 일이 있을 때 다루도록 하겠습니다.
Embedding video clips
바로 이어 비디오를 transformer로 mapping하는 두가지 방법에 대해 다루는 데요. VIT에서는 한 장의 이미지를 다뤘기 때문에 W*H*C의 demesion을 가지고 있었습니다. 그러나 vedio에서는 시간에 따라 이미지가 재생되기 때문에 T라는 demension이 추가됩니다. 즉 input 이 T*W*H*C의 차원이 됩니다. 이를 sequence of token으로 바꾼다면 차원은 n_t*n_h*n_w*d 의 차원이 되겠지요 ( n은 patch의 개수 입니다 ) . 또한 embeded patch를 얻기 위해서는 token을 N*d로 바꿔주어야 합니다. 그래야만 transfomer에 들어간테니까요. 그렇다면 궁금한 것은 어떻게 sequence of token으로 바꿀지 입니다. 다음 2 문단을 통해 서로다른 방법을 제안합니다.
방법 1. unform frame sampling
방법은 간단합니다. 우선 input vedio를 n 개의 frame으로 나눕니다. 그 다음 각각의 frame에 대해 독립적으로 vit에서 사용한 것처럼 embed 하는 것입니다. 즉 n개의 frame에 대해 n*n개의 patch를 가지고 있게 되는 형태가 되겠지요. 즉 직관적으로 한 장의 엄청나게 큰 2D image를 VIT에 넣는 방법이라고 생각하시면 됩니다.
방법 2. Tubelet embedding
다음 방법으로는 이미지가 아닌 'tube'로 나누는 방법입니다. tube로 나누면 무엇이 장점이냐하면, tube는 시공간적 정보를 모두 가지고 있습니다. 즉 tube 에서 각각의 frame은 공간적 정보를 volum은 시간적 정보를 가지게 된답니다. 각설하고 위에서 보이는 바와 같이 튜브에서 volum을 가지는 patch들을 잘라내고 그를 linear projection 시키는 방법을 생각해 볼 수 있겠지요. 물론 차원이 늘어났기 때문에 ( 부피에 대한 차원 ) 연산량 역시 증가합니다. 다만 앞에서 말한 방법 1과 다른 점은 시공간적 정보를 모두 가지고 있다는 점이지요.
Transformer Models for Video

이 챕터부터 본인들이 한 연구에 대해 설명하기 시작합니다. 가장 먼저 바로 전에 언급드린 방법 1을 시작으로 시공간적 정보를 효과적으로 factorise한 아키텍처로 발전시킨 것을 보여주겠다라며 시작을 알립니다.
Model 1: Spatio-temporal attention
처음 제시하는 모델이 바로 방법 1에서 설명한 모델을 구현해 놓은 모델입니다. 이 방법은 그들이 처음 제시한 방법이 아니라 기존에 " Joint Space-Time model "에서 제시한 모델을 구현한 것인데요, 아시다시피 CNN에서는 층이 깊어질수록 receptive field가 전체적 정보를 가지게 되지만, 해당 모델에서는 처음부터 transformer layer 에 모든 정보가 한번에 들어가게 되지요 물론 모든 프레임을 나눠 token화 했기 때문에, 너무 많은 token이 있고 attention 또한 시공간적 정보를 동시에 가지고 있다보니 복잡성 또한 증가하게 되지요. 비디오를 해석하는데 이 정도 복잡성이 문제가 되는 것은 아니지만, 다음 모델부터는 더욱 효과적이다라고 하며 다음 모델로 넘어갑니다.
Model 2: Factorised encoder

이번 모델에서는 2개의 transformer encoder가 존재합니다. 첫 번쨰는 동일한 시간적 정보에 대해 공간적 정보를 학습하기 위한 encoder이고 다음으로는 시간적 정보를 학습하기 위한 encoder 입니다. temporal token h_i는 spatial transformer를 통과한 이후 얻을 수 있고 h_i의 z_cls는 spatial transformer를 통과하며 얻은 z_cls의 average pooling을 하여 얻게 됩니다. 이 때 H_i의 demension은 n_t*d 이고 h_i가 temproal encoder에 들어가며 시 공간적 정보를 모두 활용할 수 있게 됩니다. 이 모델은 late fusion 모델과 비슷하다고 말하고 있으며, 더 많은 transformer block 떄문에 model 1보다는 많은 연산량이 필요하다고 말하고 있습니다.
Model 3: Factorised self-attention

이 모델은 모델 1과 같은 개수의 transformer layer( block )을 가지고 있는데요, 다른 점은 모든 정보를 한번에 고려하는 것이 아니라, 첫 번째 self attention은 오직 공간적 정보만을 학습하게 하고 다음으로 시간적 정보만을 학습하게 합니다. 즉 공간적 정보 학습에 들어가는 토큰은 같은 시간에 추출된 토큰이고 시간적 정보를 학습하는 데 들어가는 토큰은 같은 공간적 정보를 가지는 토큰이라고 하네요. 즉 이 모델은 모델 2를 구성하는데 인코더가 2 개 였다면 그를 하나로 합쳤다고 생각하시면 되는데요. 그렇기 때문에 같은 복잡성을 가지고 있게 됩니다. 즉 모델 1에 비해 효과적인 연산을 한다고 할 수 없는 것이지요. 그리고 이 순서를 바꾸어 시간적 토큰을 통과 시킨뒤 공간적 토큰을 통과 시키더라도 큰 차이가 없었다고 합니다. 마지막으로 classfication token은 공간적 토큰을 시간적 토큰으로 reshape하는 과정에서 모호성을 제거하기 위해 사용하지 않았다고 합니다. ( 이 부분이 정확한 설명이 안나와 있어 애매하긴 한데, 추측하기로는 z_cls가 아예 존재하지 않는 것은 아닙니다. MLP 에 들어갈 토큰이 존재해야되기 때문이죠. 그렇다면 class token을 사용하지 않았다는 말은, 모델 2에서는 공간적 정보를 가지는 토큰 모두가 z_cls를 가지고 있고 이를 average pooling하여 temporal 에 들어갈 z_cls를 구했었는데, 이번에는 처음 토큰에 z_cls가 들어가지 않고 MLP 들어가기 전에 z_cls 가 들어가는 방식을 채택 했다는 것 같아요. )
Model 4: Factorised dot-product attention

마지막 모델은 시간적 정보와 공간적 정보를 학습하되 model 1과 같은 parameter를 가진 모델을 결국에 만들었다고 하는데요. 그 방식은 공간적 정보에 해당하는 attention과 시간적 정보에 해당하는 attention으로 나누는 것 대신 multi head dot product attention을 사용했다고 합니다. 각 토큰에 대해 공간적 정보를 가지는 attention weights와 시간적 attention weights를 각각 계산했다고 합니다. 그 방식에 대해 설명하겠습니다. attention을 계산하는 것은 transfoermer 에서 사용하는 계산과 동일합니다. 핵심 아이디어는 key 와 value를 구성하는 demesion을 세팅하는 방식인데요, 각 토큰에 대해 공간적 정보를 학습하도록 token의 key와 value의 demension를 n_h dot n_w x d 세팅하고 시간적 정보를 학습하도록 key와 value 의 demension을 n_t * d로 맞춰줍니다. 그렇게 해주면 결과적으로는 model1과 같은 parameter를 가지게 되는 것이지요. 복잡도는 model 2와 3과 동일하게 되는 것이고요.( 어떻게 구현했는지는 의문이기는 합니다.) 즉 위에 언급한 식을 아래와 같습니다

그 다음 마지막으로 concate을 해주고 linear projection을 해줍니다.

initialisation by leveraging pretrained models
이 부분부터는 자신들이 모델을 학습하기 위해 사용했던 방법에 대해 소개합니다. VIT 은 매우 많은 양의 데이터를 필요로 합니다. 마찬가지로 자신들 역시 transformer를 사용하기 때문에 많은 양의 데이터가 필요한 데, 처음부터 학습시켜서 원하는 목표에 도달하기가 쉽지가 않아서 vit의 pre trained 된 모델을 활용했다고 말하고 있습니다. 그런데 이렇게 하려면 몇 가지 의문이 듭니다. 아키텍처가 바뀌는 것이니까 어떻게 VIT 아키텍처의 모델을 사용해서 우리거에 적을 데이터로 학습할 것인가 하는 것인데요. 우선 vit은 이미지 모델이고 자신들은 video 모델이라는 점이 큰 차이점이기 때문이죠. 즉 전체 demension 자체가 중간에 바뀌는 것이 문제다 이 말입니다. 그리고 그걸 어떻게 해결 했는지 말해주는 부분이라고 할 수 있겠습니다.
Positional embeddings
위에서도 언급했다 시피, 차원이 다릅니다. n_t만큼 더 많은 차원이 있죠. 결과적으로 vit에서 사용된 값을 반복적으로 사용하여 차원을 늘렸다고 합니다.
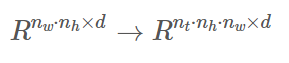
Embedding weights
tubelet embeding에 사용된 tensor는 3차원 인데 비해, vit은 2 차원 tensor 이죠. video classification을 위해 2D filter를 3D filter로 temporal dimension을 따라 filter를 복사하고 평균내어 inflate했다고 말하고 있죠. inflate는 말 그대로 늘렸다는 말입니다. 그니까 차원이 안맞으니까 기존 값을 복사하고 평균내서 필요한데 채웠다라고 정리할 수 있겠네요.

추가적으로 다른 전략도 고려했다고 했는데요. central frame initialisation이라는 방법입니다. 즉 가운데 포지션 t/2 부분을 제외한 모든 부분을 0으로 세팅하는 겁니다.

이렇게 하면 3D convolutional filter ( 여기서는 tubelet 을 활용한 embeding )가 마치 uniform frame sampling 처럼 보여ㅓ서 시간적 정보 역시 학습할 수 있다고 설명하고 있습니다.
Transformer weights for Model 3
모델 3은 transformer block이 vit과 다릅니다. 즉 두개의 multi-headed self attention 모듈을 가지고 있죠. 이 경우에 공간적 MSA 모듈만 pretrained module의 weight로 초기화해주고, 시간적 정보는 0으로 초기화 해주었다고 합니다. 그럼으로써 마치 residual connection ( skip connection ) 처럼 역할을 하도록 초기화 해주었다고 하네요.
그 뒤에는 실험을 해서 어떻게 최고 성능에 도달했는지에 대한 내용이 나옵니다. 그리고 파라미터들을 조정해가며 어떤 결과를 보였는지에 대한 내용이 나오죠. 뭐 결과적으로 우리가 최고다가 되겠습니다. 그리고 다 섞을때가 최고다가 되는 것이구요.
이렇게 이번 논문은 마치려고 합니다.
처음 논문을 정리해서 올리는 것이다보니 생각보다 시간이 많이 걸리네요
어느 정도까지 설명을 써놔야하는지 감이 잘안오네요.
다 다루자니 너무 많고 해석만하자니 의미가 없는 것같아서
어려운 논문 리뷰였던 것 같습니다.
이상 마치도록 하겠습니다. 감사합니다.
'AI 논문' 카테고리의 다른 글
| [꼼꼼하게 논문 읽기]A Comprehensive Survey on Transfer Learning 1 ( 2019 ) (0) | 2022.06.17 |
|---|---|
| [꼼꼼하게 논문 읽기] Multiscale Vision Transformers 1 (0) | 2022.06.09 |
| [꼼꼼하게 논문 읽기] MTV :Multiview Transformers for video recognition 2 ( 2022 ) (0) | 2022.05.31 |
| [꼼꼼하게 논문 읽기] MTV :Multiview Transformers for video recognition 1 ( 2022 ) (0) | 2022.05.31 |
| [ 꼼꼼하게 논문 읽기 ] ViViT : A Video Vision Transformer 1 (0) | 2022.05.30 |



