안녕하세요 WH입니다.
지난 글에 이어 이번에는 모델에 대해 알아보도록 하겠습니다
지난 글이 궁금하시면 아래 글을 참조해주세요
2022.05.31 - [AI 논문] - [꼼꼼하게 논문 읽기] MTV :Multiview Transformers for video recognition 1 ( 2022 )
[꼼꼼하게 논문 읽기] MTV :Multiview Transformers for video recognition 1 ( 2022 )
안녕하세요! WH입니다 오늘은 최신 논문을 다뤄볼까합니다 올해 google에서 나온 논문이죠? 시작해 볼게요. 누군가는 논문을 읽을 때 왜 굳이 introduction과 related work을 읽냐고 물어봅니다 간단합니
developer-wh.tistory.com
Multiview Transformer for Video
우선 시작은 vit과 vivit을 리뷰하면서 시작하겠다고 말을하네요. 이 부분은 바로 이전 글에서 자세히 다뤘기 때문에 이 부분은 넘어가도록 하겠습니다. 해당 부분을 아래 링크로 남겨놓겠습니다.
2022.05.30 - [AI 논문] - [ 꼼꼼하게 논문 읽기 ] VITVIT : video vision transformer 2
[ 꼼꼼하게 논문 읽기 ] VITVIT : video vision transformer 2
안녕하세요 WH입니다. 앞 글에서는 related work까지 다루어 보았죠? 2022.05.30 - [AI 논문] - [ 꼼꼼하게 논문 읽기 ] ViViT : A Video Vision Transformer 1 [ 꼼꼼하게 논문 읽기 ] ViViT : A Video Vision Tr..
developer-wh.tistory.com
VIT과 VIVIT을 overview한 이후에 바로 자신들의 모델을 소개하는데요 같이 보도록 하겠습니다
Multiview tokenization
자신들의 모델은 기본적으로 multiple set of token을 추출한다고 말합니다. 아래 와 같이 말이죠.

여기서 V는 다양한 스케일의 view의 개수를 말합니다. 따라서 첫 번째 요소는 0번째 transformer 처리 layer 이후의 (1)번째 view를 뜻하게 된답니다. 그리고 여기서 view는 비디오에서 뽑아낸 특정 사이즈로 고정된 tubelet을 의미한다고 말합니다. (이 말이 바로 전 글에서 언급했던 tubelet volume에 따라 다른 veiw를 뽑아낸다고 말한 근거 입니다 ) 그리고 view에 대해 덧붙여 설명하는 데요, large view는 tubelet의 volume이 큰 tubelet을 말합니다 ( 그러면 당연히 token의 개수가 적겠죠 ) 마찬가지고 small veiw는 tubelet의 volume이 작아서 많은 token을 가지고 있는 view를 말합니다.

위의 그림에서 보면 왼쪽 input이 large view, 오른쪽 input이 samll view가 되겠지요. 또한 각각의 view를 3D convolution을 사용해서 token화 시킨다고 말합니다. 또한 small view에 convolutional kernel이 작게 적용하여 많은 토큰을 생성할 수 있도록 했다고 합니다. 그래서 직관적으로 small view에서는 미세한 행동변화를, large view에서는 변화가 적은 장면에 대한 정보를 capture할 수 있도록 했다고 합니다. 또한 transformer 역시 다양한 크기로 사용했다고 합니다. 그리고 이 부분은 다음 파트에서 설명한다고 하며 넘어갑니다.
Multiview transformer
앞서 언급했던 바와 같이, 처음 input video로 부터 token을 추출해 내는 데, 해당 input은 아래와 같이 정리 됩니다.

self-attention이 이차의 복잡성( 다른 논문에서 언급하고 있다는 데, 보지 못했던 논문이라 조만간 정리해서 올리겠습니다 )을 가지고 있기 때문에, 모든 view에 대해 동시에 계산하는 것이 가능하지 않기 때문에 개별적으로 L층을 가지는 transformer 인코더로 구성된 multiview encoder를 사용했다고 합니다. 더불어 아래 그림과 같은 방식으로 나열 연결을 구현했다고 합니다. 그래서 최종적으로 아래 그림과 같은 각각의 예시와 같이 토큰을 추출하고 최종 글로벌 인코더로 해당 토큰들을 처리하고 class token을 생성하여 분류를 해낸다고 하네요 ( 그니까 이말은 multiveiw 가 하나로 합쳐지고 classification을 위한 class token을 생성한 후에 분류를 한다고 하는 것인데요, 모든 모델에서 flow를 조금 보면 large scale의 토큰에 small veiw에서 추출된 token의 정보가 더해지는 방식으로 구현되어 있어요. ) ( 왜 이렇게 불친절할까요 사실 읽으면서도 한번에 파악이 안된건 안비밀 )

Multiview encoder
자신들이 제시하는 multiview encoder는 개별 view를 위한 각각의 transformer로 구성되어 있고, view는 cross-view 정보를 합치기위해 나열되어 연결(? lateral connection인데 좋은 표현있을까요?)되어 있다고 말합니다. 각각의 transformer는 정보를 합치는 옵션적으로 layer 안에서 다른 스트림의 정보를 합칠수 있는 부분을 제외하고 transformer의 구조를 따른다고 합니다. 그리고 해당 부분은 뒤에서 다루겠다라고 말하네요. 또한 자신들의 모델이 transformer layer 사용에 있어서 정해진 틀이 있지 않다고 말하고 있네요 ( 무조건 무슨 layer가 들어가야되고 이런 부분을 말합니다 ) 또한 각각 개별 transformer layer 안에서 self -attention을 동일한 시간적 인덱스에 대해 계산한다고 합니다 ( 이 부분은 vivit에서 아이디어를 가져온 것 같네요 ) 조금 다른 부분은 vivit에서와 달리 모든 부분의 시공간적 token이 필요하지 않은데 이유는 다른 스트림에서 정보를 가져오고 global encoder에서 모든 스트림으로 부터 얻은 token을 사용하기 떄문이라고 합니다.
Cross-view fusion
위 그림에서 사용한 cross-view fusion에 대해 말한다면서 시작합니다. d(i)는 hidden dimension으로 view에 따라 다양한 값이라는 것을 알려주며 시작합니다.
Cross-view attention(CVA)
가장 먼저 설명하는 CVA 입니다. 이것은 straight-forward method 인데요, straight-forward method란 말 그대로 모든 토큰을 쭉 펴서 거대한 하나의 set을 만드는 방식입니다 vivit에서 model 1이 이 방법으로 구현되어 있었죠. 그런데 그냥 쭉 합치는 것은 self-attention의 quadratic complexity ( 조만간 파악해서 올리겠습니다 ) 때문에, 비디오 모델에서는 사용이 어렵다고 하며 자신들은 효과적인 대안책을 찾았다고 합니다.
그 아이디어는 바로 인접한 view를 순차적으로 융합하는 사실에서 출발합니다. 구체적으로 larger view로 부터 token을 업데이트 하려면 attention을 smaller view의 token, z(i)의 queries와 z(i + 1)의 key와 value를 가지고 계산해야 한다는 겁니다. 그런데 이 때 token의 hidden dimensions이 lager view와 smaller view 각각 다를 수 있기 때문에 같은 dimension으로 project 시킵니다. 또한 residual connetion을 사용하는 데, 이는 image-pretrained model을 사용할 때 도움이 된다고 합니다. 그에 대한 논문이 바로 ( Cross-attention multi-scale vision transformer for image classification. In ICCV, 2021 ) 인데요 조만간 다루도록 하겠습니다.
Bottleneck tokens
서로 다른 두 view 사이의 정보를 전달하는 가장 효과적인 방법은 중간 token set에서 bottle neck token을 이용하는 것입니다. 이 아이디어 역시 순차적으로 모든 쌍에 대해 정보를 합치고 있다는 점을 말하며 내용으로 넘어갑니다.
시작합니다. bottlenck token을 초기화 해줍니다. 이때 dimension은 아래와 같습니다.
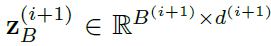
이 때 B(i+1)은 (i+1) transformer layer 이후 bottleneck token의 수가 됩니다. 물론 이 수는 전체 token N 보다는 훨씬 작은 수가 되겠지요. 또한 B(i+i) token은 위의 그림 (b)에서 볼수 있다시피 같은 view 의 input token에 합쳐져 있습니다. 그리고 self-attention을 통과하지요. 이게 i+1 의 정보를 효과적으로 전달하는 방법이라고 말합니다. 그 이후에, Z_B_(i+1) 토큰은 i 번째 view에 linearly 하게 project됩니다. 그리고 이 z(i)에 합쳐지게 되고 이 input이 self attention이 포함된 encoder를 통과하게 됩니다. 이 과정이 모든 인접한 pair view 에 대해 수행하게 됩니다.
이 cross-view attention을 통해, 모든 인접한 view pair에 대해 ( 모든 scale의 view ) 정보를 고려할 수있게 됩니다. 물론 토큰의 수는 줄어들게 되겠죠. ( straight-forward 방법에 비해 ) 그리고 bottleneck tokens 은 random하게 초기화 했다고 하네요. 그리고 bottleneck token을 사용한 선행 연구 2가지도 밝히고 있는데, 이 논문들 역시 시간이 지나면서 다뤄보도록 하겠습니다.
MLP fusion
이 방법은 MLP block을 통과하기 전에 concete하는 방법을 사용합니다. 구체적으로 dimension d(i+1)을 가지는 z(i+1) i번째 view의 hidden dimesion에 맞춰 합쳐줍니다. 그리고 이 변형된 input을 MLP에 넣어주고 depth d(i)에 linear project 시켜주는 방식입니다. 이 방식을 인접한 view에 적용시켜줍니다.
Fusion locations
앞에서도 언급했다시피, 이론적으로 레이어마다 cross view fusion을 통해 다른 view 정보를 전달할 필요는 없습다고 말하고 있습니다. 왜냐면 fusion operation이 receptive field를 가지고 있기 때문이죠 ( 그렇지만 transformer에서 attention은 이미 이전 모든 token에 대한 정보를 가지고 있습니다, 그렇기 때문에 이론적으로는 불필요한 과정이라고 말하는 것이죠 ) 게다가 개별 view는 각각 다른 depth의 encoder를 가지고 있기 때문에, 서로 다른 layer를 통과한 상태라면 fusion 정보가 다른 상태임을 의미하죠. 그래서 design의 선택에 따라 바뀌게 되는 것이고 이것을 뒤에 실험에서 이것저것 빼보며 design 했다고 합니다. 요약하자면, 이론적으로 필요없는 데, 넣어보니 성능은 좋아지고, 어떤게 best인지 모르니까 실험해서 최고로 나온것들을 보여주겠다 이겁니다.
Global encoder
이 global encoder는 모든 정보를 취합한 token을 만든 다음에 통과 시키는 encoder입니다. 그림이 위에 있어서 다시한번 가져왔습니다. 이 그림에서 맨 위의 encoder를 의미하는데요. 여기서 i 번째 의 class token을 모두 가져옵니다. 즉
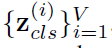
이것을 바로 global encoder에 넣는 것이 아니라, transformer의 원문에 있는데로 넣는다고 하네요. transformer의 원문을 따른다고 말하고 있는 데요. 바로 뒤에서 C ( number of classes ) classification에 mapping 된다고 하는 것을 보니, 단어 개수 대신 embeding 이 class 수에 맞도록 해서 하는 것이 아닌가 추측해봅니다. 이 부분은 구현된 부분을 봐야 무슨말인지 정확하게 알겠네요. ( 아직 구현까지는 보지 못했습니다 )
그 뒤의 내용은 한 마디로 요약하자면
몇몇 데이터 셋에서 최고 성능을 일궈냈다로 요약가능하겠네요.
이것으로 MTV 논문 리뷰를 마치도록 하겠습니다.
수식은 일부러 다루지 않았습니다.
또한 이런 논문 리뷰를 할 커뮤니티를 만들 예정이니 관심있으신 분은
댓글 남겨주세요~ 이상 WH였습니다.
'AI 논문' 카테고리의 다른 글
| [꼼꼼하게 논문 읽기]A Comprehensive Survey on Transfer Learning 1 ( 2019 ) (0) | 2022.06.17 |
|---|---|
| [꼼꼼하게 논문 읽기] Multiscale Vision Transformers 1 (0) | 2022.06.09 |
| [꼼꼼하게 논문 읽기] MTV :Multiview Transformers for video recognition 1 ( 2022 ) (0) | 2022.05.31 |
| [ 꼼꼼하게 논문 읽기 ] VITVIT : video vision transformer 2 (0) | 2022.05.30 |
| [ 꼼꼼하게 논문 읽기 ] ViViT : A Video Vision Transformer 1 (0) | 2022.05.30 |


