얼마만에 쓰는 건지 참
시간이 너무 빨리 가네요.
그래도 본업에 충실하느라 조금은 늦었지만
조금..? 조금이라 치고
오늘 다뤄볼 논문은
최근 나름 활발하게 연구가 진행되는
분야입니다. HOI 분야인데
nividia jetpack 6 정식 릴리즈에서 활용될
가능성이 있으니 준비는 해놔야겠죠?
시작해보겠습니다.
Abstract
Human-Object interaction detection 기술은 trasnformer 기반 detector에 영향을 받아왔죠. 그럼에도 불구하고 transformer 기반 detector들 parametric interaction을 vnailla Transformer를 통해 one-stage 방법으로 HOI predictions의 set에 직접 map하죠. 이는 내부 혹은 상호 작용 구조를 충분히 활용되지 못하게 하죠. 이 연구에서 저자들은 새로운 transformer-style HOI detector를 설계합니다. structure-aware Transformer over Interaction proposals ( STIP )라 불리는 HOI detector이죠. 이 설계는 HOI set prediction의 과정을 두 개의 subsequent phase로 나눕니다. interaction proposal generation이 먼저 수행되고 그 뒤에 non-parametrci interation proposlas가 structure-aware Transformer를 통해 HOI predictions로 transforming되죠. structure-aware Transformer는 vanilla Transformer 에 interaction proposlas 중에 holistically semantic structure와 각 interaction proposal 내에서 human/object의 locally spatial structure를 추가적으로 encoding 함으로써 upgrade 했습니다.
Introduction
Human-Object Interaction ( HOI ) detection은 이미지 내에서 상호작용하는 human과 object 를 localize하고 그들 간의 interactions를 identify 하죠. 물론 ( 사람, 객체, 상호 작용 ) triplets의 형태로 HOI predctions를 만들어내죠. practical한 HOI detection systems는 human-centric scene understanding을 수행합니다. 따라서 많은 applications에 대해 굉장한 잠재력을 가지고 있죠. 예를 들면, 보안 이벤트 detection, robot imitation learning 등이 있죠. 일반적으로, conventional HOI detectors는 HOI set predcition task를 간접적으로 다룹니다. 이 task는 human/object/interaction에 대해 surrogate regression과 classification problems로 공식화하죠. 이런 간접적인 방식들은 subsequent post-processing을 요구하는데 near-duplicate predcitons를 제거하고 heuristic한 matching을 하죠. 따라서 end-to-edn 방법으로는 학습시킬 수 없고, sub-optimal solution을 야기하죠. sub-optimal solution 문제를 극복하기 위한 의도는 최근 SOTA HOI detectors의 발전을 가져왔죠. HOI detection을 direct set prediction probelm으로 보고 DETR을 활용한 것이 예가 되겠습니다. 물론 end-to-end 방식을 추구합니다. 더 자세히, vanilla Transformer는 parametric interaction queris를 one-stage 방식으로 HOI predictions의 set으로 map하기 위해 사용되죠. ( learnable positional embedding sequence 등 과 같은 ) 그러나, 이런 HOI detectors는 무작위로 초기화된 embeddings를 가지고 parametric interaction queries로부터 HOI set prediction을 시작합니다. 즉, parametric interaction queries와 output HOIs 간의 correspondence( 대게는 Hungarian algorithm 에 의해 할당되죠 )는 dynamic한데 이 말은 interaction query 각 target HOI 에 해당하는 corresponding은 HOI set predction 초기에는 알려지지 않는다 거죠. 이는 prior knowledge의 사용을 방해하죠. 이 정보는 HOI set prediction에서 inter actions 중 relational reasoning에 매우 유용한 정보죠.
자세히, inter-interaction structure를 가지고, 저자들은 HOI들 간의 holistic semantic dependencies를 참조하는 데, 이는 두 개의 HOIs가 같은 사람이나 object를 공유하는지를 고려하여 직접 결정될 수 있죠. 이런 structure는 common sense konwledge를 함축하는데, 이 지식들은 HOI의 semantci dependencies를 다른 HOIs과 비교하여 활용함으로써 한 HOI의 prediction을 용이하기 하게 하죠. Figure 1에서 input image를 받아들여, " human wear glove"의 존재는 "human fold bat"에 대한 강한 indication을 제공합니다. 게다가, intra-interaction sturcture는 각 HOI에 대해 local spatial structure로 interpreted 될 수 있죠. 예를 들면, human 과 object의 layout은 interaction을 묘사하기 위해 image area에 대한 model's attention을 유도하는 추가적인 prior knowledge로 활용되죠.
이 연구에서, 저자들은 새로운 scheme을 설계하는데 Transformer-style HOI detector에 기반합니다. Structure-aware Transformer over Interaction Proposals ( STIP )라 불리죠. 이 design은 set prediction의 one-stage solution을 두 개의 cascaded phases로 나눕니다. 먼저 interaction proposlas를 만든 뒤에 HOI set prediction을 interaction proposals에 기반하여 수행하죠 ( Figure1에서 볼 수 있죠 )

non-parametric interaction queries로서 interaction proposal network( IPN )에 의해 유도된 interaction proposals를 input으로 받는 STIP는 더 합리적인 interaction queries를 가진 subsequent HOI set predction을 도출하고 이는 HOI set prediction을 boosting 할 수 있는 static auery-HOI correspondence를 도출합니다. predicted interaction proposals는 interaction proposals 간이나 각 interaction proposal안에서 human&object 간의 structured understanding을 constructing을 위한 fertile ground를 제공합니다.
요약하면, 저자들의 contribution은 다음과 같습니다. 1) Transformerstyle HOI detector의 제안된 two-phase implementation이 HOI proposals간에 잠재적인 interactions의 매끄러운 incorporation을 보여주는데 이는 one-stage approach가 가진 문제를 극복하죠. 2) structure-aware Transformer는 vanilla Transformer의 강화된 performance를 위한 intra / inter interaction structure를 사용하는 것에 대해 추가적인 expoitation opportunity를 용이하게 합니다.
Related Work
HOI detection task는 지속적으로 정의되어 왔고 최근 HOI detectors의 발전은 2 분류로 나뉩니다. two-stage methods와 one-stage approach가 있죠.
Two-stage Methods
two-stage method는 먼저 humans/objects를 detect하고 interaction classification 을 수행합니다. 많은 연구들이 HOI feature learning을 강화하도록 제안되었고 이는 interaction classification을 담당하는 두 번째 stage에 해당하죠. HOI features는 3 개의 perspectives로부터 유도됩니다. : appearance/visual features, spatial features, 그리고 linguistic feature 이죠. 다양한 방법들이 instance-centric graph structure에 대해 relational reasoning을 수행하는 message passing mechanism을 활용합니다. 이는 human과 object instances 들간의 global contextual information를 가진 HOI features를 더 풍부하게 하는 것을 목표로하죠. 한 연구는 contextual cues의 meaning을 용이하게하는 contextual ateention mechanism을 다양화합니다. 게다가 human pose, body parts, detailed 3D body shape에 대한 informateion들이 HOI feature representation을 강화하는데 사용될 수 있죠. 다른 연구들에서는 external source와 language domain으로 부터의 추가적인 knowledge가 HOI feature learning에 사용됩니다. 가장 최근, ATL scheme은 multiple HOI datasets에 걸친 affordance feature bank를 construct했고 affordance feature 를 interactions가 발생할 때 object representaion에 추가하죠.
One-stage Approaches
one-stage HOI detectors는 직접 HOI triplets를 predict하는데 이는 잠재적으로 two-stage에 비해 빠르고 간단합니다. UnionDet는 one-stage manner로 human-object pairs의 union regions를 detect하는 첫 시도였습니다. 다른 연구는 HOI detection을 keypoint detection problem으로 정의하여 문제를 풀고자 했죠. 최근, Transformer-based object detectors의 성공으로 제한점이 더욱 적어지고 있습니다. 다른 연구들은 single interaction Transformer decoder를 사용하는데 HOI triplets를 예측합니다. 전체 architecture는 end-to-end 방식으로 최적화 될 수 있고 이 때, hungarian loss를 사용하죠. 그러나, 해당 연구들은 두 개의 병렬적인 transformer decoders를 사용했는데, 각각은 interactions와 instances를 detect하고 두 출력 결과를 가지고 최종 HOI predictions를 생성합니다.
This Scheme
STIP는 Transformer-style architecture인데 HOI detection을 set prediction problem을 봅니다. 이로써 post-processing을 제거하고 architecture가 end-to-end로 학습 가능하게 되죠. 기존 transformer-style methods는 HOI set predcition을 one-stage 방식으로 수행하지만, STIP는 이 과정을 두 개의 과정으로 나눕니다. 먼저 high-quality interaction queries로써 interaction proposals를 생성합니다. 그런다음 HOI set prediction을 생성하는 non-parametric queries 로써 그들은 input으로 취합니다.
Apporach
Figure2는 STIP 의 개요를 보여주며, 모든 framework는 4 개의 main components로 구성됩니다. object detecion을 위한 DETR, interaction proposals를 생상한기 위한 interaction proposal network, interaction-centric graph construction, HOI set prediction을 위한 structure-aware Transformer이고 아래 그림에서 확인할 수 있습니다.

구체적으로, off-the-shelf DETR은 사람과 물체를 input image 내에서 detect하는 데 적용됩니다. 다음, detection results에 기반해서, 저자들은 IPN을 설계하는데 IPN은 interaction proposals로써 가장 interactive한 human-object pairs를 선택하죠. 그 이후에, 선택된 모든 interaction proposals를 graph nodes로 여기고 이는 interaction-centric graph 가 됩니다. 이는 inter-interactinion semantic sturecture와 intra-interaction spatial sturcture를 나타냅니다. 선택된 interaction proposals는 더 나아가 non-prarmetric queries로 취해지는데, 이는 HOI set prediction을 생산하고 structure-aware Transformer를 활용하죠. 해당 Transformer는 relational reasoning을 강화하는 interaction-centric graph으로 부터 유도된 이전 knowledge를 사용하죠.
Interatction Proposal Network
탐지된 사람과 객체에 따라, IPN은 interaction proposals를 생성합니다. 예로, probably interactive human-object pairs를 들 수 있죠. 더 자세히, 저자들은 모든 가능한 human-object pairs를 pairs 별 connectivity를 활용합니다. 각 human-object pair에 대해, IPN은 MLP를 통해 그들 간의 존재하는 interaction에 대한 probability를 예측하죠. top-K human-object paris 가 output interaction proposals로 나오게 되죠.
Human-Object Pairs Construction
탐지된 사람과 객체의 각 pair를 연결하고, input image에서 가능한 모든 human-object pairs를 생성합니다. 각 human-object pair는 세가지 feature로 나타내집니다. appearance feature, spatial feature, 그리고 linguistic feature 로 표현되죠.
구체적으로 apperance feature는 DETR로 부터 유도된 human과 object instace features의 concatenation으로 나타납니다. normalized center coordinate를 정의함으로써, 저자들은 spatial feature를 측정하는데 이는 모든 geometric properties의 concatenation이죠. linguistic feature는 object의 name을 300-dim vector로 encoding함으로써 얻어지죠. 최종 representation의 human-object pair는 apperance, spatial, 그리고 linguistic features의 concatenation으로 계산되죠.
Iteractiveness Prediction
Interactiveness prediction module은 IPN에 있고 human-object pair를 input으로 받아, pair 간에 interactions가 존재하는지에 대한 probability를 예측하는 것을 학습하죠. 저자들은 이 interactiveness prediction의 sub-task를 binary classification problem으로 보고 K 개의 human-object pairs를 샘플링하죠. 이는 positive / negative pairs로 구성되어 있습니다. 사람과 객체 bounding boexs의 예측값들이 ground-truth와 IoU를 비교하여 0.5 크다면, 저자들은 이 pair를 positive sample로 다뤘죠. 그 반대의 경우를 negative sample로 간주하고요. negative paris를 가져오는 자연스런 방법은 randomly sampling strategy를 사용하는 겁니다. 대신에, 저자들은 hard mining strategy를 사용합니다. 즉 high predicted interactiveness scores를 가진 negative pairs를 뽑느데 이는 interactiveness prediction의 learning을 용이하게 하죠. 뽑아낸 N개의 human-object pairs를 interactiveness prediction module에 mini batch 형태로 넣어 focal loss 를 사용하여 최적화합니다.
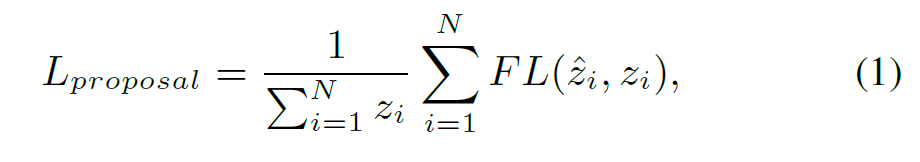
Interaction-Centric Graph
선택된 모든 interaction proposlas에 기반해, 저자들은 interaction-centric graph를 구성하는 방법에 대해 설명합니다. 이는 inter- / intra-interaction sturcture의 풍부한 이전 knowledge를 완전히 펼치죠. 기술적으로, interaction proposals을 하나의 graph node로 봅니다. 그런다음 interaction-centric complete graph는 graph edges로 모든 두 개의 nodes와 연결함으로써 완성되죠.
Inter-interaction Semantic Structure
직관적으로, 같은 이미지에서 interactions간에 semantic structure가 존재합니다. 예를 들어, " human hold mouse" 라는 interaction을 찾았다면, 이는 언급된 human이 "human look-at screen"과 연관될 가능성이 매우 높죠. 이 사실은 저자들이 common sense knowldege를 사용하도록 하는데 이 knowledge는 HOI에 대해 interactions 중에 relational reasoning을 boost하는데 사용됩니다. 저자들은 논문에서 directional semantic connectivity를 <HOI(i_2) -> HOI(i_1)> 으로 표현합니다. 이는 HOI(i_2)에 대해 interaction proposal HOI(i_1)의 semantic dependency를 나타내죠. Figure 3에서 보여지듯이, 두개의 interaction proposals가 같은 human이나 object를 공유하는지에 따라 6 종류의 interaction semantic dependencies가 정의됩니다.
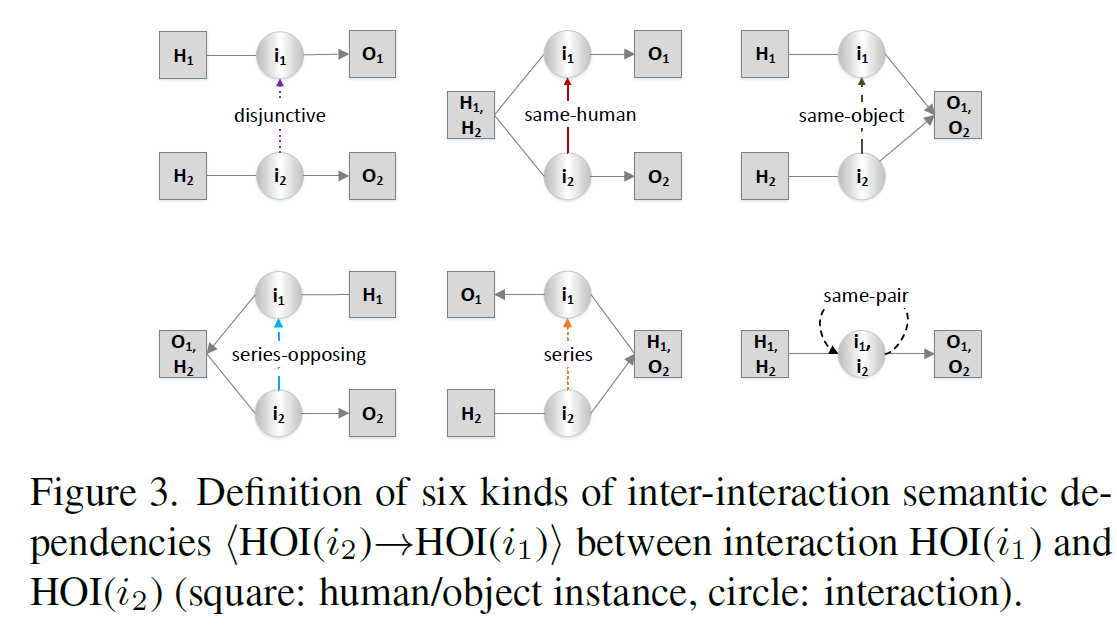
구체적으로, HOI(i_1)와 HOI(i_2)가 어떤 human/object instance도 공유하지 않는다면, "disjunctive"로 dependency를 분류합니다. 만약 HOI(i_1)과 HOI(i_2)가 같은 human/object instance를 공유한다면, same-human이나 same-object로 label합니다. HOI(i_1)의 human/object instance가 HOI(i_2)의 object/human와 정확히 동일하다면, series-opposing과 series로 각각 label합니다. 만약 human과 object가 HOI(i_2)와 HOI(i_1)에서 각각 같다면, same-pair로 label합니다.
Intra-interaction Spatial Structure
전체 whole interaction-centric graph에 대해 inter-interaction semantic structure는 모든 interaction proposals에 걸친 semantic dependencies를 종합적으로 펼칩니다. 그러는동안, 각 interaction proposal안에서 human/object의 spatial structure 는 사용되지 않죠. 따라서 저자들은 intra-interaction spatial structure를 가진 각 graph node를 charcterize합니다. Figure 4에서 나타내지듯 해당하는 interaction proposal에서 각 componet의 layout으로써 interpreted 될 수 있죠.
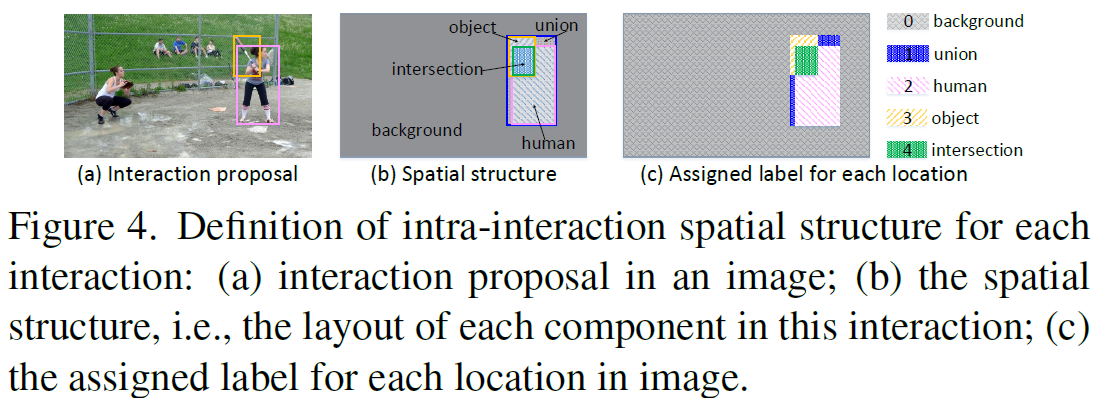
구체적으로 저자들은 spatial location을 identify합니다. 그리고 layout label을 각 location에 할당하죠.
Structure-aware Transformer
K개의 interaction proposals와 interaction centric graph를 활용해, 저자들은 inter-/intra- interaction structures의 이전 knowledge를 relational reasoning에 integrate하는지를 보여줍니다. 구체적으로, structure-aware Transformer는 structure-aware self-attention과 cross-attention modules를 통해 inter-/intra-interaction structures의 additional guidance를 활용해 all interaction proposals를 encode하기 위해 devised합니다.
Preliminary
먼저, 간략하게 vanilla Transformer에 대해 요약합니다. attention mechanism을 사용하고 queries의 sequence에 key-value pairs를 output sequence로 transform하죠. 각 ouput element는 attention을 활용해 weighted된 all values를 aggregating함으로써 계산되죠. 여기서 attention weight는 softmax를 활용해 normalized됩니다.
Structure-aware Self-attention
현존하는 Transformertype HOI detectors는 HOI set prediction을 위해 vanilla Transformer의 self-attention module을 통해 interactions 중에 relational reasoning을 수행합니다. 그러나, vanilla Transformer에서 relation reasoning process는 parametric interaction queries에 의해 발생되고 사용되지 않은 inter-ineraction structure의 이전 knowledge는 남아있게 되죠. 대안으로, structure-aware Transformer는 non-parametric queries로부터 HOI set prediction을 수행합니다 ( selected interaction proposals 에 대해 수행합니다 ). 그리고 structure-aware self-attention module을 통해 inter-interaction semantic structure을 활용해 conventional relation reasoning을 upgrade 하죠
구체적으로, K 개의 interaction proposals q를 interaction queries, keys, 그리고 values로 받아, structure-aware self-attention module은 inter-interaction structure-aware resoning을 시행하는데 이는 각 interaction의 HOI representation을 강화합니다. 저자들은 각 key q_j를 q_i에 대해 의미론적인 dependency를 가지는 inter-interaction의 encoding을 활용해 보강하는데 이는 q_j의 concatenation과 해당 semantic dependency label d_ij로 측정되죠. 이런 방식으로, 저자들은 inter-interaction semantic structure를 attention wieght의 learning으로 통합합니다. 식은 아래와 같죠.
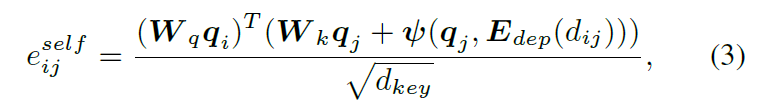
여기서 E_dep는 semantic dependency label의 embedding matrix을 표기합니다. 그리고 프사이는 2-layer MLP로 구현되는데 이는 inter-interaction semantic dependency를 encode하죠. 따라서 structure-aware self-attention module의 intermedeate HOI features hat q 출력은 interactions 중에 semantic structure를 가지게 되죠.
Structure-aware Cross-attention
다음, intermediate HOI feature hat q에 기반해, structure-awre cross attention modul은 HOI features를 강화하는데 사용되는데 이는 interactions들과 DETR에서 original image feature map 간의 contextual information을 사용함으로써 강화하죠. K의 HOI intermediate HOI features hat q를 queries로 받고 image feature map 을 key와 values로 받습니다. structure-aware cross-attention module은 각 interatcion의 HOI feature를 강화하는 image feature map에서 intra-interaction structure-aware reasoning을 수행합니다. structure-aware self-attention module과 유사하게, 각 key x_j는 hat q quer에 해당하는 intra-interaction spatial sturecture의 encoding을 활용해 보충하죠. attention weight의 learning는 intra-interaction spatial sturcture에 통합되는 데 그 식은 아래와 같습니다.
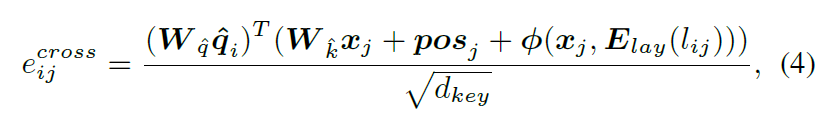
여기서 pos_j는 position encoding 이고 E_lay는 layout label의 embedding matrix입니다. 저자들은 파이를 2-layer MLP로 구현하고 이는 intra-interaction spatial sturcture를 encode하죠
Training Objective
학습 동안, structure-aware Transformer의 최종 HOI representaitons output을 interaction classifier로 던져주고 이는 각 interaction proposals의 interaction classes를 예측하죠. interaction classification의 objective는 focal loss에 의해 측정되고 식은 아래와 같죠.
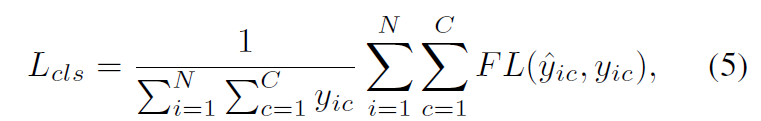
여기서 C는 interaction classes의 수이고 y_ic는 i-th proposal의 labels가 c-th interaction class를 포함하는지를 나타냅니다. hat y_ic는 c-th interaction class의 probability를 예측합니다. 따라서 STIP의 objective는 interactiveness prediction objective와 interaction classification objective를 합치게 되죠.
오랜만에 정리하는 데,
이 글도 처음 쓰고 한달정도 걸려서 정리한것 같네요
요즘 너무 정신이 없어서..
밀린게 많은데 음 열심히 정리해야죠 그럼 이만



