안녕하세요! WH입니다
정말 오랜만에 글을 쓰네요, 요즘 매우 정신이 없었거든요
블로그도 시간이 있어야 쓴다는 데, 프로젝트 마무리 기간이라 정신이 없었어요.
시작하겠습니다.
처음부터 모든 내용을 다루기에는 양이 많아서
이미지 관련 기본 내용들부터 생각나는 데로 차근차근 정리해드리겠습니다.
참고로 저는 computer vision, edge device AI 분야에 재직 중입니다.
더 기초 자료, 기초 내용은 요청이 있거나 시간이 날 때 추가로 업로드 할게요
컴퓨터에게 이미지란
처음 주제는 컴퓨터에게 이미지란 이라는 주제입니다. 우리는 컴퓨터가 인식하는 이미지에 대해 알 필요가 있습니다. 간단하게 예시를 들게요. 2 * 2 이미지가 있다고 가정해 봅시다. ( 내부 숫자는 임의의 숫자임을 알려드립니다 ) 예시를 위해 만든 숫자에요

예를 들어 왼쪽의 고양이 사진은 오른쪽의 숫자로 나타난다고 가정하겠습니다. 즉 컴퓨터는 이미지를 숫자로 이해합니다. 매우 작은 사이즈 32 * 32 의 이미지는 1024개의 숫자로 나타내어지고, 그 이미지는 1024개의 숫자로써 컴퓨터는 인식하게 된답니다. 쉽죠? 뭐 예를 들자면 대표적 이미지로 대표적 이미지 set 손글씨 set인 mnist 데이터과 위와 같은 방식입니다. 하나만 짚고 넘어가자면, 위의 그림에서 2*2 숫자로 나타내어 진 부분을 채널이라고 부른답니다. 조금만 더 들어갈게요. 아래 그림을 볼까요?

실제 이미지는 RGB 3 개의 채널의 숫자 데이터를 가지고 모든 색을 표현합니다. 우리는 즉 우리는 고양이 사진이 2*2 로나타내어 진다고 가정하고 이미지가 컬러이미지라면, 2*2( 채널 크기 )*3( 채널 개수 ) = 12 개의 숫자가 사진을 표현한다고 할 수있습니다. 너무 쉽죠? 이런 기본적인 내용을 왜 다루냐. 반드시 필요하기 때문입니다.
숫자로 다루기 때문에 발생하는 문제점
우리는 이미지를 대상을 따로 인식하기 때문에 문제가 없습니다. 컴퓨터에게는 쉽지 않은 일입니다. 이미지 속 대상만이 아닌 배경을 표함한 모든 부분을 숫자로 인식하기 떄문이죠. 그렇기 때문에 문제가 발생합니다.
1. 배경이 달라질 때
1-1. 특히 배경과 비슷할 때 ( 예를 들면 눈보라가 치고 눈이 쌓인 환경에 흰 옷을 입고 있는 사람이 있는 경우 )
2. 같은 물체의 자세가 바뀌거나, 색이 바뀔 때
3. 빛이 바뀔 때 ( 어두운 곳, 밝은 곳 등 )
4. 물체가 가려질 때
5. 하나의 종에 다양성에 의해 ( 즉 고양이도 여러 종류가 있겠죠? 그 종류 마다 고양이가 아닌 각각 다른 이미지로 인식합니다.)
이게 왜 문제냐, 위에서 언급한 모든 경우를 같은 물체라도 다른 이미지로 인식하기 때문에 물체를 구분한다거나, 물체의 위치를 특정하는 일이 쉽지가 않은 것입니다. 용어 하나만 정리하고 가자면, 물체가 무엇인지 종류를 구분하는 것을 classification, 물체의 위치를 찾아 주는 것을 localization, 물체를 구성하는 픽셀마다 물체를 classification해주는 것을 segmentation, 물체의 위치가 이동함에 따라 위치를 따라 오는 것을 tracking이라고 표현합니다. 그리고 크게 classification + localization을 합쳐서 detection이라고 표현하죠
여튼 아셔야 하는 점은, 매우 조금의 이동이나 변화가 있으면 컴퓨터는 다른 전혀 새로운 이미지로 인식한다는 점입니다. 꼭 기억하시길 바랍니다.
classification
이미지 인식의 시작은 분류입니다. 즉 classification 인데요. 이미지를 보고 해당 이미지가 배경을 포함하고 모든 것을 고려했을 떄 무엇인지 분류해 낼 수 있어야, 그 다음 위치를 찾든가 할 테니까요. 그렇다면 궁금한 것은 이미지를 어떻게 분류해 낼꺼냐라는 질문이 시작입니다.
우선 모든 일반적인 상황에 대해 모든 문제를 전부 다를 수 있는 명시적인 알고리즘은 존재하지 않습니다. 일부 제한된 상황에서 분류를 포함한 인식이라는 과정을 진행하는 것이죠.
이제 차근차근 생각해보겠습니다. 우리는 이미지를 분류하는 것이 목표입니다. 분류를 하기 위해서는 반드시 기준이 필요합니다. 즉, 차이를 인식할 수 있어야 합니다. 즉 우리는 정답이 필요하고 정답과 비교하여 얼마만큼의 차이를 가지는 지에 대한 논의가 반드시 필요합니다. 여기서 다시 한번 짚고 넘어가겠습니다. 이미지는 숫자로 인식합니다.
그렇다면 차이를 인식하기 위해 가장 간단한 방법은 이미지가 이루고 있는 숫자마다 차이를 계산해서 유사도를 측정하는 것일 겁니다. 이미지가 숫자로 인식하기 떄문에 우리는 차이를 표현하기위해 '거리'라는 표현을 씁니다. 숫자간 차이를 표시하기 위해서죠. 아래 예시를 보겠습니다.

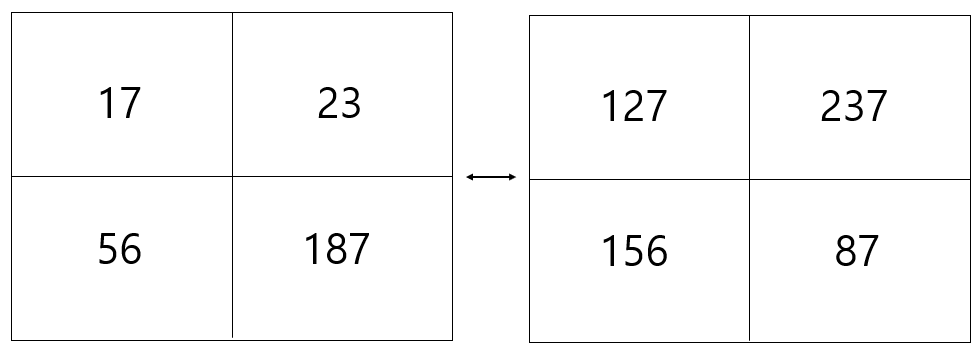
2개의 고양이가 있습니다. 각각의 숫자로 표현되고 이해의 편의를 위해 채녈은 1개만 있다고 가정해봅시다. 그렇다면 위에서 언급한 두 이미지를 구분하는 가장 간단한 방법은 각각의 픽셀의 차이를 비교해서 더한 것을 기준으로 하는 거겠죠?
즉
1. 127 - 17 = 110
2. 237 - 23 = 214
3. 156 - 56 = 100
4. 187 - 87 = 100
총 차이 = 424
두 이미지는 총 424 만큼의 차이가 있다고 생각해 볼 수 있겠네요. 또한 424는 해당 분류기에서 loss에 해당한다고 할 수 있습니다. loss는 분류기가 얼마나 나쁜가를 나타내 주는 척도 이죠. 그렇다면 이 분류 기준에서 차이가 작으면 작을 수록 첫번째 기준 이미지와 비슷하다고 판단해 볼 수 있겠지요. 여기 쓰인 판단의 기준은 용어적으로 L1 distance를 이용했다고 말하고, 해당 알고리즘은 NN 알고리즘( Nearest Neighbor ) 라고 부릅니다. 다만 한가지 말씀드리면, 이는 이미지 분류에 쓰이지 않는다는 것을 먼저 알려드립니다. 이유는 간단합니다. 빛에 따라 특정 사물의 위치에 따라 전혀 다른 이미지 이지만 차이는 같게 나오는 문제가 발생할 수 있기 때문입니다. 여튼 말씀드리고 싶었던 것은, 이미지 분류를 위해 기준이 필요하고 그 기준을 주는 것이 무엇인가 입니다. 여기서 확장된 알고리즈림 KNN이지만 이미지 분류에는 사용되지 않음으로 skip하고 넘어가도록 하겠습니다.
오늘 이 글을 통해 얻어가셔야 하는 점은, 이미지는 숫자로 인식된다. 그리고 이미지 인식의 시작은 분류이며 기준이 필요하다는 것입니다.
또한 픽셀 속 숫자들은 각각의 특징과 방향을 포함하는 벡터로 볼 수 있다는 점 역시 기억해주시길 바랍니다. 갑자기 무슨 벡터냐고요? 앞으로 필요하게 될겁니다. 이 글에서 언급하지 않은 관계로 궁금하신 분들은 아래 글을 참조하시길 바랍니다.
2022.02.18 - [AI] - AI에서 벡터를 사용하는 이유
AI에서 벡터를 사용하는 이유
안녕하세요! WH 입니다. 어제부로 AI팀으로 옮기게 되었는데요. 사실 그게 중요한 것은 아니고, 듣는 교육과 공부한 내용들을 정리해보고자 합니다. 벡터가 사용되는 이유가 무엇일까 AI를 접할
developer-wh.tistory.com
다음 글부터 시작해서, 앞으로 컴퓨터 비전에 대한 기초 이론들, 논문 내용, 프로젝트에 사용되는 실제 모델들과 실예 정도 까지 정리해보도록 하겠습니다. 물론.. 프로젝트와 관련해서는 올릴 수 없는 관계로.. 그 부분은 조금 생각해보도록 할게요. 여튼 이번 글은 여기까지 입니다. 즐거운 하루 되셔요
'AI' 카테고리의 다른 글
| AI 개발자를 준비하기 위해 필요한 것 (0) | 2022.04.22 |
|---|---|
| computer vision AI ( feat. 역전파, backpropagation, computational graph ) (0) | 2022.04.22 |
| computer vision AI ( feat loss fuction, 손실 함수, 최적화 ) (0) | 2022.04.21 |
| computer vision AI( feat. linear classifier 선형 분류기 ) (0) | 2022.04.21 |
| AI에서 벡터를 사용하는 이유 (0) | 2022.02.18 |

