
[꼼꼼하게 논문 읽기]Sparse Instance Activation for Real-Time Instance Segmentation ( 2022 )
Abstract
이 논문에서, 저자들은 개념적으로 새롭고 효율적이고 fully convolutional framework을 제안하는데 real-time instance segmentation에 관한 framework이죠. 이전에는, 대부분의 instance segmentation methods는 object detection에 크게 의존하고 bounding boxes나 dense centers에 기반해 mask prediction을 수행합니다. 반면에, 저자들은 instance activation maps의 sparse set을 제안하죠. 이는 new object representation이고 각 foreground object에 대해 informative regions를 highlight하죠. 그런 다음, instance-level features는 recognition과 segmentation을 위한 highlighted regions에 따라 features를 aggregating 함으로써 얻어지죠. 게다가, bipartite matching에 기반해, instance activation maps는 object를 one-to-one style로 예측할 수 있죠. 따라서, post-processing에서 NMS를 피할 수 있죠. instace activation maps를 활용한 simple하지만 effective design 때문에, SarseInst는 극단적으로 빠른 inference speed를 가지고 40FPS를 달성하죠. ( 서버 기준으로 RTMDetIns와는 비교가 안되지만 NMS 가 없어서.. edge에서는 더 빠를수도 있겠네요 ) coco benchmark에서 37.9 AP를 달성하고요.
Introduction
Instacne segmetation은 intance-level segmentation을 이미지에서 각 object에 대해 생성하는 것을 목적으로하죠. deep convolutional neural networks와 object detection의 advances에 기반해, 최근 연구는 instacne segmentation에서 굉장한 진보가 있었죠. 그리고 large-scale benchmarks에서 인상적인 결과를 달성했죠. 그러나, real-time and efficient instance segmentation algorithms를 developing하는 것은 여전히 challenging 하고 urgent 하죠. 특히 autonomous driving과 robotics에서는 더욱 그렇죠.
prevalent mehtods는 instances first 는 localize 하는 detectors 적용하고 region-based convolutional networks, dynamic convolutions 등을 통해 segment하는 경향이 있죠. 이 방법들은 개념적으로 직관적이고 great perfomance를 달성하죠. 그러나, real-time에 관해서는 이 방법들은 some limitations로부터 고통받죠. 먼저, 대부분의 methods는 dense anchors를 사용하는데, 이는 object를 localize한 다음 segment 하죠. 예를 들면, CondInst에서는 ( 512 x 512 input이 주어지면 ) 5456개의 이상 instances 가 있죠. 이는 많은 redundant predictions과 훨씬 많은 computation burden를 초래하죠. 게다가, 각 pixel의 receptive field는 limited 되고 만약 centers나 anchors에 의해 objects를 densely localize하면 contextual information은 불충분하죠. 두번째로, most methods는 multi-level prediction을 요구하고 이는 natural objects의 scale variation을 handle하죠. 이는 본질적으로 latency를 increases하죠. Region-based methods는 region features를 acquire하는 RoI-Align 적용하고 이는 edge/embedded device에 algorithm을 deploy하기 어렵게 하죠. 마지막으로, post-processing은 attention을 요구하는데 sorting과 NMS 를 포함한 masks를 processing하는 것이 time-consuming 하기 때문이죠. 특히 dense prediction에대해서는 더욱 그렇죠. improves NMS 조차 ~2ms 이 소요되고 이는 전체 시간의 약 10%를 차지하죠.
이 논문에서 저자들은 real-time instance segmentaion에 대해 새로운 highlight to segment paradigm을 제안합니다. object를 represent하는 boxes나 centers를 사용하는 대신, instance activation maps( IAM )의 sparse set을 사용합니다. IAM은 informative object regions를 highlight하죠. 이는 CAM에서 영감을 받았는데 weakly-supervised object localization에 광범위 하게 사용되는 방법이죠. instance activation maps는 instance-aware weighted maps인데요 instance-level features는 highlighted regions에 따라 직접 aggregated 될 수 있죠. 그런 다음, recognition과 segmentation이 instance features에 기반해 수행되죠. Figure2는 region-based, center-based, IAM-based representations를 비교합니다.

이 비교에서, IAM는 다음 이점을 보입니다. (1) IAM은 discriminative instacne pixels를 highlights합니다. 그리고 obstructive pixels를 억제하고 개념적으로 incorrect instance feature locaization problem을 피하죠 이 문제는 center-/region-based method 가 가지고 있는 문제기도 하고요. (2) IAM은 전체 이미지로부터 instance features를 aggregates하고 more contexts를 offer하죠. (3) activation maps를 활용해 instance features를 computing하는것은 RoI-Align과 같은 extra operation 이 없어서 간단하죠. 그러나 spatial priors(anchors나 center)를 사용하는 previous work과 다른데, instance activation maps는 input과 different objects에 대해 arbitrary 에 따라 바뀌며 training을 위해 hand-crafted rules를 활용한 target을 assign하는 것이 불가능하죠. 이를 다루기 위해, 저자들은 instance activation maps에 대해 label assignment를 공식화하는데 bipartite maching problem으로 다루고 DETR에서 제안되었죠. 구체적으로, 각 target은 Hungarian algorithm을 통한 its activation map 뿐만 아니라 object prediction에 assigned 되죠. training 동안 bipartite matching은 instance activation maps를 이용하는데 해당 maps는 individual objects를 highlight하고 redendant predictions를 금지하죠. 따라서 inference 동안 NMS가 필요없게 되죠.
나아가, 저자들은 이 paradigm을 구체화하고 SparseInst를 제안합니다. 극도로 simple 하지만 efficient 한 method죠. SparseInst 는 single-level prediction을 적용합니다. image feature를 추출하는 backbone과 single-level features에 대해 multi-scale representation를 강화하는 encoder그리고 instance activation maps를 계산하는 decoder로 구성되어 있고 recognition과 segmentation을 수행합니다. 이는 Figure 3에서 볼 수 있죠.
SparseInst 는 pure하고 fully convolutional framework입니다. 그리고 detector로부터 독립적이죠. fact로 부터의 이점은 다음과 같습니다. (1) instance activation maps를 통한 sparse predictions (2) single-level prediction (3) compact structures (4) NMS나 sorting이 없는 간단한 post-processing.
Related work
object representations에 따르면, existing methods는 두 개의 groups로 나눌 수 있죠. region-based methods와 center-based methods
Region-based Methods
Region-based methods는 object detectors에 의존하죠. detector는 object를 detect하고 bounding boxes를 acquire하고 난 뒤 RoIPooling 이나 RoIAlign을 적용하여 pixel-wise segmentation을 위한 region features를 추출하죠. Mask R-CNN은 대표적인 방법으로 Faster R-CNN을 확장하였는데 mask branch를 추가하였죠. mask branch는 objects에 대한 masks를 예측하고 end-to-end instance segmentation을 위한 strong baseline을 제안합니다. Mask R-CNN이 발생시키는 low-quality segmentation과 coarse boundaries를 해결하기 위해 몇몇 연구들이 있고 그들은 high-quality masks를 위해 mask predictions를 refine하는 방법을 제안하죠. 몇몇 연구는 cascade structures를 사용하는데 더 정확한 mask prediction을 위해 object localization을 점진적으로 향상시키죠.
Center-based Methods
최근, 많은 approaches가 single-stage detectors를 사용하고있죠. 특히 anchor-free detector를요. 이 방법들은 objects를 center pixels로 나타내죠. 이는 bounding boxes를 사용하는 대신이죠. 그리고 center features를 사용해 segment합니다. 몇몇 방법은 object contours를 사용하는 데 object에 대해 hollows 나 multiple pars를 갖는 것과 같은 제한이 있죠. YOLACT은 instance masks를 생성하는데 maks coefficients와 prototype mask를 결합하는 방식을 사용하죠. MEInst 와 CondInst는 FCOS의 확장입니다. 이는 encoded mask vector나 mask kernels를 예측함으로써 확장한것이죠. SOLO는 detector-free method지만 objects를 center를 활용해 localize하고 recognize 하죠. 뿐만 아니라 mask kernels를 생성함은 물론이고요 SparseInst 는 sparse instance activation maps를 사용합니다. 이는 간단한 pipeline과 hight effciency로 objects를 represent하죠.
Bipartite Matching for Object Detection
bipartite matching은 end-to-end object detection에 광범위하게 사용되어왔죠. 이는 NMS 를 피하죠. SOLQ나 ISTR은 mask encodings를 사용했죠. QuerInst는 dynamic mask head를 추가함으로써 확장했고요. 게다가 여러 연구들은 instance, semantic queries를 활용해 transformers를 사용하는데 이는 panoptic segmentation results를 얻게 해주죠. 그러나 저자들의 방법은 fast speed를 목적으로 합니다. instance activation maps를 활요해서 말이죠.
Method
이번 section에서 저자들은 먼저 instance activation maps를 investigate합니다. 이는 object를 representing하는데 사용되죠. 그 다음 저자들은 새로운 framework을 제안하는데 objects를 highlight하는 instance activation maps의 sparse set을 사용하고 instance-level recognition과 segmentation을 위해 instance features를 aggregate하죠.
3.1 Instance Activation Maps
Formulation
직관적으로, instance activation maps는 instance-aware weighted maps이죠. 이는 각 object에대해 informative regions를 highlight하는 것을 목적으로 하고요. 그리고 highlighted regions로부터 features는 semantically 하게 abundant하고 objects를 separating하고 recognizing 하는 데에 instnace-aware 하죠. 그럼으로 저자들은 features를 instnace feautres로써 activation maps를 따라 직접 aggregate합니다. input image feature X ( R ^ D x ( H x W ) ) 가 주어지면, instance activation maps는 다음과 같이 공식화 될수 있습니다.
여기서 A는 N instance activation maps의 sparse set이고 F_iam() 은 simple network인데 sigmoid non-linearity를 가지고 있죠. 그러면 저자들은 instance features의 sparse set을 얻을 수 있습니다. 이는 instance activation maps를 활용해 input features maps X로부터 distinctive information을 gathering함으로써 가능하죠. 식으로는 아래와 같습니다
여기서 z ={z_i}^N 는 image에서 N potential objects 에 대해 feature representations 이죠. bar A는 각 instance map에 대해 1로 normalized 된 것이죠. sparse instance-aware features는 {z_i}^N 은 직관적으로 사용되는데 recognition과 instance-level segmentation에 사용되죠.
Learning Instance Activations
Instance activation maps는 explicit supervisions를 사용하지 않습니다. 예를 들면 instance masks와 같은 것들이죠. 본질적으로, recognition과 segmentation을 위한 subsequent modules는 indirect supervisions를 활용한 instance activation maps를 제공하는데, F_iam이 informative regions를 discover하도록 돕죠. 더욱이, supervisions는 instance-aware한데 이는 bipartite matching 때문이죠. 이 matching은 F_iam이 objects를 discriminate하게하고 map 당 하나의 object만 activate 하게 합니다. 결과적으로, proposed instance activation maps는 idividual objects에 대해 discriminative regions를 highlight할 수 있죠.
3.2. SparseInst
Figure 3에서 설명하다시피, SparseInst는 간단하고 압축적이며 공통된 framework이죠. backbone과 instance context encoder 그리고 IAM-based decoder로 구성되어있습니다. backbone network는 ResNet 등의 예가 있으며, multi-scale features 를 주어진 이미지로부터 추출하죠. instance context encoder는 backbone에 붙여지는데 more contextual information을 강화하고 multi-scale features를 fuse하기 위함이죠. faster inference를 위해, encoder는 single level features를 출력으로 주죠. 이는 input image에 대해 1/8 x 의 resolution을 가집니다. features는 IAM-based decoder에 입력으로 주어지고 classification과 segmentation을 위한 foreground objects를 highlight하는 instance activation maps를 generate합니다.
3.3 Instance Context Encoder
자연적 상태에서 objects는 다양한 범위의 scales이 있죠. 이는 detectors의 performance를 약화시키는 경향이 있고요. 많은 approaches는 multi-scale feature fusions를 적용합니다. 예시로는 feature pyramids가 있죠. 그리고 multi-level prediction을 적용하기도 합니다. 이는 different scales의 objects를 위해 recognition이 용이하게 하죠. 그럼에도 불구하고, multi-level pyramidal features를 사용하는 것은 중복된 예측의 양을 증가시킬 뿐더러 computation burden을 증가시키는데 특히 heavy heads를 사용하는 detectors에게는 더욱 치명적이죠. 반대로, 저자들의 방법은 더 빠른것을 목적으로 하죠. 물론 single-level prediction을 사용하죠. 다양한 scales의 objects에 대해 single-level features의 limitations를 고려해서, 저자들은 feature pyramid networks를 reconstruct 하고 instance context encoder를 제안합니다. 이는 Figure 3에서 설명한 바와 같죠. instance context encoder는 receptive fields를 확대하는 C_5 이후에 pyramid pooling module을 적용하고 P3에서 P5까지 features를 fuse 합니다. 이는 output single-level features에 대해 multi-scale representations 강화하죠.
3.4 IAM-based Segmentation Decoder
Figure 3은 IAM-based segmentation decoder를 설명하죠. instance branch와 mask branch를 가지고 있고요. 두개의 branch는 256 channels를 가진 3 x 3 convolutions이 쌓여 구성되어 있죠. instance branch는 recognition과 instance-aware kernel을 위해 instance activation maps과 N instance features를 생성하는 것을 목적으로 하고 mask branch는 instance-aware mask feautres를 encode하기 위해 designed 되었죠.
Location-Sensitive Features
실험적으로, objects는 different positions에서 localized됩니다. 그리고 spatial locations는 instances를 구별하는 cues로 사용될수 있죠. 따라서, 저자들은 two-channel coordinate features를 설계하는데 spatial locations의 normalized absolute (x,y) coordinates로 구성되며 CoordConv와 유사하죠. 그런다음 저자들은 output features를 encoder로 부터 concatenate하는데 instance-aware representation을 강화하는 coordinate feature를 활용하죠.
Instance Activation Maps
저자들은 간단하지만 효과적인 sigmoid를 가진 3x3 convolution 을 vanilla F_iam으로 적용합니다. 이는 single activation map을 가진 각 instance를 highlights하죠. 따라서 instance features {z_i}는 activation maps를 통해 얻어집니다. 각 potential object는 256-d vector로 encoded됩니다. 그런 다음 three linear layers가 classification, objectness score, mask kernel {w_i}^N을 위해 적용됩니다. 게다가, fine-grained instance features를 얻기위해, 저자들은 group instance activation maps( Group-IAM) 을 제안하고 이는 각 object에 대해 regions의 groups을 highlight하죠. 예를 들면 object 당 multiple activation maps가 되겠죠. 구체적으로,저자들은 4-group의 3x3 convolution을 F_iam으로 적용하는데 이는 group_IAM을 위해서죠. 그리고 group으로부터 features를 concatenating함으로써 instance features를 aggregate하죠.
IoU-aware Objectness
저자들은 one-to-one assignment가 most predictions가 background가 되도록한다는 것을 발견했죠. 이는 classification confidence가 더 낮아질 수 있으며, classification socres와 segmentation masks 간의 misalignments를 야기할 수 있죠. 위의 문제를 완화하기 위해, 저자들은 IoU-aware objectness를 도입합니다. IoU-aware objectness는 classification outputs를 adjust하죠. 저자들은 predicted masks와 ground-truth masks간의 estimated IoU를 foreground objects를 위한 targets로써 적용합니다. instances를 위한 ground-truth objectness 다양한데 instances를 separate하는 network를 용이하게 할수 있죠. mask predictions에 기반한 IoU score를 predict하는 extra head를 사용하는 것과 다른데, 저자들은 오직 IoU를 objectness targets으로써만 적용합니다. inference stage에서, 저자들은 classification probability p_i를 resocre합니다. IoU-aware objectness s_i를 활용하죠. 그리고 ultimate probability 를 얻습니다. 식은 아래와 같죠. 여기서 i는 i-th instance를 나타냅니다.

Mask Head
instance-aware mask kernels {w_i}^N은 instance branch에 의해 생성되며 이를 활용해, 각 instance에 대해 segmentation mask는 직접 생성될 수 있죠 식은 아래와 같고요.
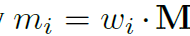
여기서 m_i는 i-th predicted mask이고 이에 해당하는 kernel은 w_i ( R^1 x D )입니다. M ( R^ D x H x W )는 mask features입니다. final segmentation mask는 upsampled 되는데 bilinear interpolation을 통해 되고 original resolution으로 upsampled되죠.
3.5. Label Assignment and Bipartite Matching Loss
제안된 SparseInst는 predictions의 fixed-size set을 결과물로 내놓죠. 때문에 hand-crafted rules를 가진 ground-truth objects를 assign하기 어렵고요. end-to-end training으로 다루기 위해, 저자들은 label assignment를 bipartite matching으로 공식화합니다. 먼저, 저자들은 pairwise dice-based matching score C( i, k )를 i-th prediction과 k-th ground-truth object에 대해 제안합니다. 이는 Eq(1)에 있고 classification scores와 segmentation masks의 dice coefficients에 의해 determined 됩니다.
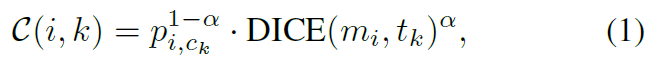
alpha는 hyper-parameter이고 이는 classification과 segmentation의 impacts를 balance하고 0.8로 set합니다. c_k는 k-th gorund-truth object에 대한 category label이고 p_i,c_k는 i-th prediction의 category c_k에 대한 probability를 나타내죠. m_i와 t_k는 i-th prediction의 masks와 k-th ground-truth object 를 각각 말합니다. dice coefficient는 Eq(2)에서 정의되어 있습니다.
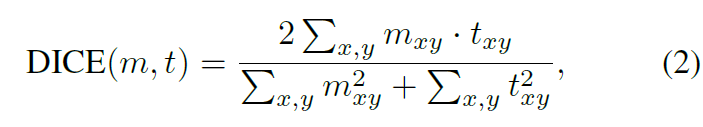
여기서 m_xy와 t_xy는 predicted mask m 과 ground-truth mask t에서 (x,y)에 pixels 각각 나타냅니다. 그러면, 저자들은 Hungarian algorithm을 적용하는데 이는 k ground-truth objects와 N prediction 간의 optimal match를 찾아주죠.
Training loss는 Eq(3)처럼 정의되어 있습니다. classification을 위한 losses를 포함하여, objectness prediction, segmentation losses가 포함되어있죠.

여기서 L_cls는 focal loss 이고 object classification을 위한 loss입니다. L_mask는 mask loss, L_s는 binary cross entropy loss로 Iou-aware objectness 위한 loss이고요. background와 foreground간의 심각한 imbalance problem을 고려하여 저자들은 hybrid mask loss를 적용하는데 Eq(4)에 나타나 있죠. 이는 dice loss와 segmentation mask를 위한 pixel-wise binary cross entropy loss와 결합한 형태죠. 식은 아래와 같고요.
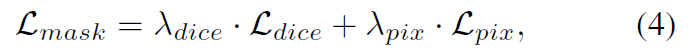
여기서 L_dice와 L_pix는 dice loss와 binary cross entropy loss이고 lambda_dice 와 lambda_pix는 coefficients에 해당하죠.
3.6 Inference
SparseInst의 inference stage는 매우 간결하고 직관적입니다. given image를 전체 network에 Foward하면 classification scores {~p_i}^N를 가진 N 개의 instances와 그에 해당하는 raw segmentation masks {m_i}^N를 얻을 수 있죠. 그런다음 category와 각 instance에 대한 confidence score를 결정할 수 있습니다. thresholding을 통해 final binary mask를 얻을수 있죠. Sorting과 NMS는 필요하지 않습니다. 따라서 inference procedure를 매우 빠르게 만들죠.
여기까지 할게요.