[ 꼼꼼하게 논문 읽기 ]CenterMask: Real-Time Anchor-Free Instance Segmentation ( 2020 )
Abstract
저자들은 간단하고 효율적인 anchor-free instance segmentation 인 CenterMask를 제안하는데요. 새로운 spatial attention-guided mask (SAG-Mask) branch를 anchorfree one stage object detector ( FCOS ) 에 도입하죠. Mask R-CNN을 활용한 한 줄기중 하나고요. FCOS object detector에 연결된 SAG-Mask branch 는 segmentation mask를 검출된 각 box에 segmentation mask를 예측하는데요. 이는 spatial attention map을 활용하고 이 map은 informative pixels에 집중하고 noise를 억압하는 역할을 하죠. 저자들은 또한 backbone networks를 개발하는데, VoVNetV2 이죠. 이는 두가지 effective strategies를 포함합니다: (1) residual connection 은 optimization probelm을 완화하는데 사용되고, (2) effective Squeeze-Excitation ( eSE )는 기존 SE의 channel information loss probelm을 다루게 되죠. SAG-Mask와 VoVNetV2를 활용해 CenterMask와 CenterMask-Lite를 설계합니다. 각각은 large model과 small model이죠. RestNet-101-FPN backbone을 사용해서, CenterMask는 38.3%을 달성합니다. 좋은 성능이다 이런 말이 아래 쭉 나와있네요.
Introduction
최근, instance segmentation은 object detection에 힘입어 엄청난 진보를 보여왔죠. 가장 대표적인 방법으로, Mask R-CNN이 있죠. COCO benchmarks를 지배해왔고요. 왜냐하면 instance segmentation은 object를 탐지함으로써 쉽게 해결될 수 있죠. 그런다음 각 box에 대해 pixels를 예측하죠. 그러나, 많은 연구에도 불구하고, instance segmentation의 속도를 고려한 연구는 거의 없죠. YOLACT이 parallel structure과 극도로 lightweight assembly process 때문에 가능한 첫 real-time one-stage instance segmentation임에도 불구하고, Mask R-CNN과 accuracy gap은 여전히 중요한 문제죠. 따라서 저자들은 accuracy와 speed의 trade-off에 초점을 맞추죠.
Mask R-CNN이 two-stage object detector에 기반하죠. 즉 먼저 box proposals를 생성하고 난 다음 box location과 classification을 예측하죠. YOLACT은 one-stage detector ( RetinaNet ) 에 기반하죠. boxes를 proposal step없이 예측하죠. 그러나, 이 object detectors는 pre-define anchors에 의존하죠. 이는 다른말로 hyper-parameters에 민감하다는 겁니다. input size, aspect ratio, scales와 같은 것들이죠. dataset에 역시 영향을 크게 받죠. 게다가, 더 높은 recall rate을 위해 anchor boxes를 densly하게 배치했기 때문에, excessively 하게 많은 anchor boxes는 positive/negative samples의 imbalance를 야기하죠. 더불어 higher computation/memory cost가 들어감은 물론이고요. anchor boxes의 drawbacks를 해결하기 위해, 최근 많은 연구가 anchor boxes로부터 벗어나 anchor-free 로 나아가고자 했죠. corner를 사용하거나, center points를 사용하는 방식이 대표적이고요. 이덕에 computation-efficient가 발생하고 anchor box 기반의 detector에 비해 좋은 성능을 보이기 시작했죠.
그럼으로, 저자들은 CenterMask라고 부르는 one stage instance segmentation model을 설계하죠. 새로운 spatial attention-guided mask branch를 FCOS에 더하는 방식이고 Mask R-CNN과 같은 방식을 따르죠. 이는 Figure 2에 나타나 있죠.

FCOS에 붙여서, 저자들의 spatial attention-guided mask ( SAG-Mask ) branch는 FCOS detector로부터 예측된 boxes를 input으로 취하고 각 Region of Interest ( RoI )별로 segmentation masks를 예측하죠. spatial attention module ( SAM )은 mask branch가 meaningful pixels 에 집중하고 uninformative pixels는 제외하도록 돕죠.
RoI에 대해 features를 추출할때,RoI pooling 이 배치되어야하는데 RoI scale를 고려해야하죠. Mask R-CNN은 새로운 assignment function을 제안하는데 RoIAlign이라 불리죠. 차이점은 input scale을 고려하지 않는다는 점이고요. 따라서, 저자들은 scale-adaptive RoI assignment function을 설계하는데 이는 input scale을 고려하고 나아가 one-stage object detector에 적합하죠. 저자들은 또한 VoVNetV2 backbone network를 제안하는데, VoVNet에 기반하죠. VoVNet은 RestNet과 DenseNet에 비해 더 빠르고 좋은 성능을 보이고요. 물론 VoVNet인 One-shot Aggregation( OSA )을 가지고 있기 때문이죠.
저자들은 OSA modules를 stacking하는 것이 성능 저하를 가져온다는 것을 발견하였고. 이 현상이 backprogation에서 gradient가 손실되기 때문이라는 것을 알게 되었죠. 따라서 residual connection을 각 OSA module에 사용하여 optimazation이 간단하도록 했죠. 이는 VoVNet이 깊어지면서 성능역시 향상되는 것을 가능하게 했고요.
Squeeze-EXcitation ( SE ) channel attention module에서는 저자들은 fully connected layers가 channel size를 줄인다는 사실을 알게되었죠. 그럼으로 computational burden을 줄였죠. 그렇지만 channel information의 손실역시 발생하게 되었고요. 따라서 SE module을 재설계하였는데, 두 개의 FC layers를 channel dimension을 유지하는 하나의 FC layer로 바꾸었죠. 이는 information loss를 줄여 성능 향상에 도움이 되었고요. residual connection과 eSE module을 활용해, VoVNetV2를 제안합니다.
SAG-Mask와 VoVNetV2 를 활용해 저자들은 CenterMask와 CenterMask-Lite를 설계하는 데 각각 large model과 small model이죠. 그 아래는 동일 조건에서 실험했더니 가장 좋은 결과가 나왔다라는 것을 말하네요.
2. CenterMask
저자들은 먼저 FCOS 에 대해 review하고 CenterMask에 대해 보여준다고 합니다. 그 다음 SAG-Mask가 어떻게 설계뙤어 FCOS detector에 들어갔는지를 설명한다고 하네요. 마지막으로 가장 효과적인 VoVNetV2를 제안한다고 합니다.
2.1. FCOS
FCOS는 anchor-free 하고 proposal-free objet detection 인데요. pixel prediction 방법으로 FCN과 비슷한 방식을 취하죠. Faster R-CNN, YOLO, RetinaNet과 같은 SOTA object detector 들은 대게 pre-defined anchor box를 사용하죠. 이는 elaborate한 parameter tunning을 요구하고 box IoU 와 관련된 복잡한 계산이 training time에 필요하죠. FCOS는 4D vector와 각 spatial location에 class label를 직접 예측하죠. 물론 feature map level에서요. Figure 2에서 보여줬다시피, 4D vector는 bounding box의 4 위치로부터 상대적 offsets로 embeds 하죠. ( left, right, top, bottom ) 게다가, FCOS 는 centerness branch를 도입하는데, 이는 해당 bounding box의 center에 pixel의 deviaition을 예측하죠. FCOS는 memory/computation cost를 줄이는 것은 물론, 다른 detectors들을 뛰어넘었죠. 저자들은 FCOS 위에 CenterMask를 설계합니다.
2.2 Architecture
Figure 2는 전체 architectue를 보여줍니다. CenterMask는 3 part로 구성되어 있죠. (1) feature extracion을 위한 backbone. (2) FCOS detection head, 그리고 (3) mask head. object를 masking하는 절차는 FCOS box head로부터 detecting objects 후에 segmentation masks를 예측하죠. 이때 cropped regions는 per-picel manner로 들어가고요.
2.3. Adaptive RoI Assignment Function
object proposals가 FCOS box head에서 예측되어진 후에, CenterMask가 segmentation masks를 예측하는데요. 이때 predicted box regions가 사용되고 Mask R-CNN과 같은 맥락을 따르죠. RoI는 FPN에서 다른 level의 feature map으로부터 예측되어지는데, feature를 extract하는 RoI Align은 RoI scales를 고려하여 feature maps의 다른 scales에 할당되어야 하죠. 구체적으로, large scale을 가진 RoI는 higer feature level에 할당되어야 합니다. Mask R-CNN은 two-stage detector에 기반하고 FPN에서 Equation1을 사용합니다.

이는 feature mpa을 할당하기 위함이고요. 위 식에서 k0는 4입니다. w, h는 각각 width와 height이죠. 그러나 Equation 1은 CenterMask에 적합하지 않죠. one-stage detector 이기도 하지만 2가지 이유때문이죠. 먼저 Equation 1은 two0stage detectors에 맞춰져 있습니다. 즉 one-stage detectors와 비교해보면 다른 featue levels를 사용하는 겁니다. 구체적으로, two stage detectors는 더 높은 feature level을 사용합니다. 즉 one-stage에서 사용하는 features가 더 낮은 resolution을 활용한 더 큰 receptive fields를 가지고 있죠. 게다가, 표준 ImageNet pretraining size는 224이고 이는 hard0cded되어서 feature scale variation에 적용될 수 없죠. 더 쉽게, input dimension이 1024 x 1024일때, RoI는 224 ^2입니다. RoI는 상대적으로 높은 feature인 P4에 할당되죠. input dimension이 있음에도 말이죠. 물론 이는 small object AP를 낮추는 결과를 가져오죠. 따라서 저자들은 Equation 2를 정의합니다. 새로운 RoI assignment function이고 CenterMask에 적합하죠.

여기서 k_max는 feature map의 last level입니다. A_input과 A_RoI는 input image와 RoI를 각각 나타내죠. 표준적인 size 224 없이 Equation 2에서는 RoI pooling scale이 input/RoI area의 ratio로 adaptively하게 할당되죠. 만약 k가 minimum level 보다 작다면 k 는 minimum levle로 고정되죠. 구체적으로, 만약 RoI의 area가 input area의 반보다 크다면, RoI는 highest feature level에 할당됩니다. 뒤집어서, Equation 1은 P_4에 RoI 224^4를 할당하죠. Equation2는 k_max-5 level을 결정하죠. 이는 RoI의 area에 대한 가장작은 feature level일 겁니다. input size보다 20x 이상 작은 size죠. 저자들은 proposed RoI assignment method는 small object AP를 Equation 1보다 향상시켰다는 것을 알아낼 수 있었죠. 왜냐면 adaptive 하고 scale-aware assignment strategy 때문이죠.
2.4. Spatial Attention-Guided Mask
최근 attention methods가 object detections에 광범위하게 적용되었죠. important features에 집중하도록 도와주고 불필요한 것들에 대해서는 무시하도록 도와주기 때문이죠. 특히, channel attention은 feature maps의 channels를 따라 초점을 마추는데 '무엇'에 초점을 맞출지를 강조합니다. 반면에 spatial attention은 informative regions를 의미하는 'where'에 초점을 맞추고요. spatial attention mechanism에 영감을 받아 저자들은 spatial attention module을 적용하는데, 이는 meaningful pixels를 spotlighting하고 uniformative ones를 repressing 하도록 mask head를 guide 하죠.
따라서, 저자들은 spatial attention-guided mask ( SAG-Mask )를 설계합니다. Figure2에서 보여줬듯, predicted RoIs 안에서 features는 RoI Align에 의해 extracted 되죠. RoI Align은 14x14 resolution을 활용하죠. 이 features는 4개의 con layers과 spatial attention module( SAM ) 의 입력으로 주어집니다. spatial attention map A_sag( X_i) ( 1xWxH )를 feature descriptor로 사용하기위해 input feature map X_i (CxWxH) 가 주어지면, SAM은 먼저 pooled features P_avg, P_max ( 1 x W x H )를 생성합니다. 각각은 average pooling과 max pooling을 의미하고요. channel axis를 따라 연산되고 concatenation을 통해 합쳐집니다. 그런 다음, 3 x 3 conv layer를 통과하고 sigmoid function을 통해 normalized됩니다. 이 과정을 요약해서 식으로 보여주면 아래와 같죠.

여기서 sigma는 sigmoid funtion을 나타내죠. F_3x3 은 3 x 3 conv layer를 나타내고 o 는 concatenate operation을 나타냅니다. 마지막으로 attention guided feature map X_sag ( C x W x H )는 아래와 같이 계산됩니다.

여기서 곱하기 처럼 생긴 연산자는 element-wise multiplication을 나타냅니다. 이후에, 2x2 deconv 는 spatially attended feature map을 28 x 28 resolution으로 upsamples하죠. 마지막으로 1x1 conv는 class-sepcific mask를 예측하기위해 적용됩니다.
2.5. VoVNetV2 backbone
저자들은 더 effective backbone network, VoVNetV2를 제안합니다. CenterMask의 성능을 향상시키기도 하죠. VoVNetV2는 VoVNet을 기반으로 향상되었죠. residual connection을 더해줌으로써 말이죠. 그리고 eSE attention module 역시 더해졌죠. VoVNet은 computation과 energy efficient backbone입니다. OSA module 덕분에 feature representation을 efficiently하게 diversified 할 수 있죠. Figure 3(a) 에서 볼 수 있고 OSA module은 conv layers로 구성되어 있고 subsequent feature maps를 한번에 aggregate하죠. 이는 diverse receptive fields를 efficiently 하게 capture할 수 있고 결국 DenseNet과 ResNet을 accuracy와 speed 에서 모두 뛰어넘게 되죠.

Residual connection
efficient와 diverse feature representation을 가지고도, VoVNet은 optimazation 측면에서 limitation을 가지고 있었죠. OSA modules은 stacked 되는데 저자들은 deeper models의 accuracy가 더 낮다는 사실을 발견하죠. ResNet에 기반해 저자들은 stacking OSA modules가 gradient의 backpropagation을 hard하게 만드는게 아닐까 추측했다고 합니다. 이는 conv와 같은 transformation functions의 증가 때문일거라고 추측했고요. 따라서, Figure 3(b)에서 보여주는 것과 같이 identity mapping을 OSA module에 추가합니다. input path가 OSA module의 마지막에 연결되고 이는 모든 OSA module의 gradients를 backpropagate하게 해주죠. 마치 ResNet과 같죠.
Effective Squeeze_excitation
VoVNet의 performance를 boosting 하기 위해, 저자들은 channel attention module을 제안하는데 eSE라고 부르고 origimal SE를 향상시킨 것이죠. Squeeze-Excitation은 representative channel attention method인데 CNN architectures에 적용되었고, its representation을 enhance하는 feature maps의 channels 간의 interdependency를 명백하게 models합니다. SE module은 spatial dependency를 channel specific descriptor를 learn하는 global average pooling으로 squeeze 한 다음, 두 개의 fully-connected layer가 useful channels 만을 highlight하는 input feature map을 rescale하죠. 요약하면 input feature map X_i ( C x W x H ) 가 주어지면, channel attention map A_ch( X_i ) ( C x 1x 1 )은 아래와 같이 계산됩니다.
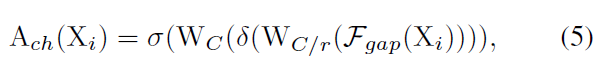
F_gap( X ) = 1/WH*( SIGMA (X_i,h) ) 는 channel-wise global aberage pooling 이고 W_C/r, W_C 는 두 개의 fully-connected layers의 weights이죠. delta는 ReLU non-linear operator를 뜻하고, sigma는 sigmoid function을 나타내죠.
그러나, SE module은 limitation을 가지고 있는데요. channel information loss이죠. 이는 dimension reduction 떄문이고요. high model complexity burden을 avoiding하기 위해, SE module이 가지는 두 개의 FC layers는 channel dimension을 reduce해야 하죠. 구체적으로 처음 FC layer는 input feature channels C를 C/r 고 줄이죠. 여기서 r은 reduction ratio를 의미하고요. second FC layer는 reduced channels를 original channel size C로 확장합니다. 결과적으로 이 과정 중에 일어났던 channel dimension reduction이 channel information loss를 발생시키죠.
그럼으로, 저자들은 eSE 를 제안합니다. 하나의 FC layer만을 사용하죠. 이는 channel dimension reduction을 없애기 위함이죠. 그렇게 해서 channel information을 유지하고 성능을 향상시킵니다. eSE는 아래와 같이 정의되죠.
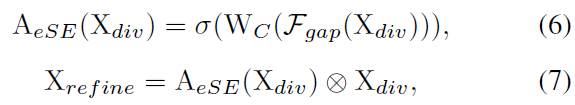
여기서 X_div 는 diversified feature map 이고 1x1 conv에 의해 계산되죠. channel attentive feature descriptor, A_eSE 는 diversified feature map X_div에 적용되는데 이는 diversified feature 이 더 informative 할 수 있도록 하기 위함이죠. 마지막으로 residual connection을 사용할 떄, input feature map은 element-wise로 X_refine 에 더해집니다. X_refine은 refined feature map을 의미하고요. 어떻게 OSA module에 eSE가 더해지는 지는 Figure 3(c)에서 보여줍니다.
나머지는 생략할게요.