
[꼼꼼하게 논문 읽기]Universal Instance Perception as Object Discovery and Retrieval ( 2023 )
Abstract
모든 instance perception tasks는 category names, language expressions, 그리고 target annotations와 같은 몇몇 queries에 의해 특정된 certain objects를 찾는 것을 목표로 하죠. 그러나, 이는 field가 multiple independent sub tasks로 나눠져야만 완수될 수 있고요. 이 논문에서 저자들은 universal instance perception model of the next generation을 제안합니다. 이름하여 UNINEXT입니다. UNINEXT는 다양한 instance perception tasks를 unified object discovery와 retrieval paradigm으로 재구성하고 objects의 다른 typeds를 perceive할 수 있죠. 이는 input prompts를 바꿈으로써 가능합니다. 이 unified formulation은 다음과 같은 이점들이 있죠. (1) different tasks로부터 엄청난 data와 label vocabularies는 general instance-level representations를 동시에 training 하기 위해 사용될 수 있습니다. 이는 특히 training data가 부족한 tasks에 굉장한 이점을 가지죠. (2) unified model은 parameter-efficient하고 동시에 multiple tasks를 handling할때 중복된 computation을 절약할 수 있습니다. UNINEXT는 20 challenging benchmarks에서 우월한 성능을 보여줬죠.
Introduction
object-centric understanding은 필수불가결한 요소중 하나고 computer vision에서 challenging한 문제이죠. 여러 해동안, 이 분야의 diversity는 실질적으로 증가했습니다. 이 논문에서 저자들은 10개의 sub-tasks를 논합니다. 이는 Figure 1에서 볼 수 있죠.

가장 기초적인 tasks로써 object detection과 instance segmentation은 특정 카테고리의 모든 objects를 찾아내길 요구하죠. 이는 boxes나 masks로써 찾아집니다. static images로 dynamic videos로 inputs를 확장하면, Multiple Objet Tracking ( MOT), Multi-Object Tracking and Segmentation ( MOTS ), 그리고 Video Instance Segmentation ( VIS ) 는 특정 카테고리의 모든 object trajectories를 찾아낼 것을 요구합니다. category names를 제외하고, 몇몇 tasks는 다른 reference information을 제공합니다. 예를 들면, Referring Expression Segmentation ( RES ), Referring Video Object Segmentation( R-VOS ) 는 주어진 language ex-ression과 matched 된 objects를 찾아내는 것을 목적으로 하죠. 게다가, Single Object Tracking( SOT ) 나 Video Object Segmentation( VOS )는 first frame에서 주어진 target annotations를 reference로 취하죠. 이어지는 frames에서 tracked objects의 trajectories를 예측하길 요구하기 때문이고요. 위에 언급된 모든 tasks는 특정한 properties를 perceive하는 것을 목표로하기 때문에, 저자들은 이들을 통틀어 instance perception이라고 칭합니다.
specific applications에 편리함을 가져옴에도 불구하고, 그런 다양한 task definitions은 전체 field를 fragmented pieces로 나눕니다. 결과적으로, 대부분의 current instance perception methods는 single이나 part of sub-tasks를 위해 developed 되죠. 그리고 specific domains로부터 data에 대해 trained되고요. 이런 fragmented design philosopy는 다음과 같은 결점을 야기합니다. (1) 독립적인 designs는 models를 다른 tasks와 domain 간의 generic knowledge를 공유하고 학습하는데 방해가 되죠. 중복된 parameters를 야기함은 물론이고요 (2) 다른 tasks 간의 mutual collaboration의 가능성은 간과됩니다. 예를 들어보자면, object detection data는 model이 common objects를 인지하게 하죠. 이는 본질적으로 REC와 RES의 performance를 향상시킬수 있습니다. (3) fixed-size classifiers에 의한 Rstricted 때문에, traditional object detectors는 different label vocabularies을 가진 multiple datasets에 대해 동시에 train되기 힘들죠. 또한 inference 동안 detect하는 object categories를 dynamically하기 바꾸는 것 역시 힘들고요. 본질적으로 all instance perception tasks가 몇몇 목적에 따라 특정 objects를 찾는 것을 목표로 하기 때문에, 이는 본질적인 질문을 야기합니다: all mainstream instance perception tasks를 한번에 모두 해결할 수 있는 unified model을 설계할 수 있는가?
이 질문에 대답하기 위해, 저자들은 UNINEXT를 제안합니다. universal instance perception model of the next generation이죠. 저자들은 먼저 10 instannce perception tasks를 3가지 종류로 나눕니다. 이는 different input prompts를 기준으로 하죠. (1) cataegory names as prompts ( Object Detection, Instance Segmentation, VIS, MOT, MOTS ) (2) language expressions as prompts ( REC, RES, R-VOS ) (3) reference annotation as prompts ( SOT, VOS ). 그런 다음 저자들은 unified prompt-guided object discovery와 retrieval formulation을 제안합니다. 이는 위의 모든 tasks를 해결하기 위함이죠. 구체적으로, UNINEXT는 먼저 N개의 object proposals를 prompts의 guidance를 따라 찾습니다. 그리고나서 final instances를 instance-prompt matching scores에 따라 proposals로부터 retrieve하죠. 새로운 formulation에 기반해, UNINEXT는 different instances를 perceive할 수 있죠. input prompts만을 바꿈으로써 말이죠. different prompt modalities를 다루기 위해, 저자들은 prompt generation module을 적용합니다. 이는 reference text encoder와 referece visual encoder로 구성되죠. 그러면 early fusion module은 current image와 prompt embeddings를 raw visual features를 강화합니다. 이 operation은 deep information exchange를 가능하게하고 later instance prediction step을 위한 discriminative representations를 제공합니다. flexible query-to-instance fashion을 고려하여, 저자들은 Transformer-based object detector를 instance decoder로 선택합니다. 구체적으로, decoder는 먼저 N instance proposals를 생성합니다. 그런다음 prompt는 이 proposals로부터 matched objects를 retrieve하는데 사용하죠. 이 flexible retrieval mechanism은 traditional fixed-size classifiers의 disadvantages를 극복하고 different tasks와 domains로부터 data에 대해 동시에 학습 가능하도록 하죠.
unified model architecture를 가진 UNINEXT는 various tasks로부터 massivs data에 대해 strong generic representations를 학습할 수 있습니다. same model parameters를 가진 single model을 사용해 10 instance-level perception을 해결할 수 있죠. Extensive experiments는 UNINEXT가 20 challenging benchmarks에대해 우월한 성능을 달성했음을 보여줍니다. 저자들의 contributions를 요약하면 아래와 같습니다.
- 저자들은 universal instance perception을 위한 unified prompt-guided formulation을 제안합니다. 이는 이전 fragmented instance-level sub-tasks를 하나로 reuniting하죠
- flexible object discovery and retrieval paradigm의 이점 때문에, UNINEXT는 different tasks와 domain에서 task-specific head 없이 train 될 수 있습니다
- UNINEXT는 20 challenging benchmarks에서 10 instance perception tasks에 대해 우월한 성능을 달성합니다. 이는 같은 model parameters를 가진 single model을 사용하죠.
Related work
Instance Perception
10 instance perception tasks의 typical methods와 goals는 아래의 내용을 도입했죠.
retrieval by category Names
Object detection과 instance segmentation은 images에서 boxes나 masks의 형태로 특정 classes의 모든 objects를 찾는 것을 목표로합니다. Early object detectors는 two-stage methods와 one-stage methods로 나눌 수 있는데 이는 RoI-level operations를 사용하는지 여부에 따라 달려있죠. 최근, Transformer-based detectors는 그들의 conceptually simple 하고 flexible한 frameworks 때문에 굉장한 주목을 받아왔죠. instance segmentation approaches는 detector-based와 detector-free fashions로 나뉘고 이는 box-level detectors가 필요한지에 따라 나뉘죠. Object detection과 instance segmentation은 critical한 역할을 하고 모든 다른 instance perception tasks를 위한 기초이죠. 예를 들면, MOT, MOTS, 그리고 VIS는 image-level detection과 segmentation을 videos로 확장합니다. 이는 videos에서 specific classes의 모든 object trajectories 찾는 것을 목표로하죠. MOT와 MOTS의 Mainstream algoriths는 online "detection-then-association" paradigm을 따릅니다. 그러나, MOTS의 benchmarks의 intrinsic difference 때문에 ( MOTS는 high-resolution long videos고 VIS는 low-resolution short video 입니다 ), most recent VIS methods는 offline fashion을 적용합니다. 이 strategy는 simple VIS 2019에서는 상대적으로 좋은 성능을 보입니다. 그러나 challenging OVIS에서는 drastically하게 감소하죠. 최근 IDOL은 online fasion과 its offline counterparts 간의 performance gap에 다리를 놓았는데요 이는 discriminative instance embddings를 통해서였죠. 이는 online paradigm의 잠재가능성을 보여준 사례기도 하고요.
Retrieval by Language Expression
REC, RES, 그리고 RVOS는 language expression에 언급된 specific target을 boxes나 masks를 사용해 주어진 images나 videos에서 찾아내는 것을 목표로 합니다. Object detection과 유사하게, REC methods는 3가지 paradigms으로 나눌 수 있습니다: two-stage, one-stage, 그리고 Transformer 기반으로 말이죠. REC와 다르게, RES approaches는 vision-language alignment를 달성하는 diverse attention mechanisms를 designing 하는 데 초점이 맞춰져있습니다. 최근, SeqTR은 REC와 RES를 unifies했죠. 이는 REC와 RES를 point prediction problem으로 통일하고 promising results를 얻습니다. 마지막으로, R-VOS는 RES의 확장으로 볼수 있는데 image에서 videos로 확장된 것이죠. 최근 SOTA methods는 Transformer-based 이고 전체의 video를 offline fasion으로 처리합니다. 그러나, offline paradigma은 real world에서 applications에 방해가 되고요. 예로는 자율주행이 있겠네요.
Retrieval by Reference Annotations
SOT 나 VOS는 먼저 video의 first frame에서 boxes나 masks를 사용해 tracked objects를 특정하죠. 그런다음 tracked objects의 trajectories를 predict할 algorithms가 요구됩니다. core problems는 (1) informative target features를 어떻게 뽑을 것인가? (2) current frame의 represetations를 가진 target information과 어떻게 fuse할 것인가? 이죠. 첫 번째 질문에 대해, most SOT methods는 target infoermation을 encode하는데 siamese backbone에 template을 통과시키죠. 반면 VOS approaches는 corresponding mask results를 가진 multiple previous frames를 fine-grained target information을 추출하는 memory encoder를 통과시켜죠. 두 번째 질문에 대해, correlations는 early SOT algorithms에 의해 광범위하게 적용되었죠. 그러나, 이들 simple linear operations는 심각한 information loss를 야기했습니다. 이를 완화하기 위해, 후속 연구에서는 ㅡmore discriminative representations를 위해 Transformer에 resort합니다. VOS에서 feature fusion은 space-time memory networks에 의해 거의 dominated되죠.
Unified Vision Models
최근 unified vision models가 그들의 strong generalizability 와 flexibilty 때문에 굉장한 주목을 받고 있고 상당한 진보를 보여왔죠. Unified vision models는 multiple vision이나 muti-modal tasks를 single model로 해결하고자 시도해왔죠. Existing works는 unified learning paradigms와 unified model architectures 로 분류될수 있습니다.
Unified Learning Paradigms
이 연구들은 대게 universal learning paradigm을 제안합니다. 가능한 많은 modalities를 covering하고자 하죠. 예를들면, MuST는 multi-task self-training approach를 6개의 vision tasks에 대해 제안합니다. INTERN은 continuous learning scheme을 도입하는데 이는 26 popular benchmarks에 대해 strong generalization ability를 보여주죠. Unified-IO나 OFA는 unified sequence-to-sequence framework을 제안하는데 다양한 vision, language, 그리고 mulit-model tasks를 다룰수 있죠. 비록 이들 연구가 many tasks에서 수행될 수 있지만, commonality 와 다른 tasks에 따른 inner relationship 은 less explored 되고 exploited 되죠.
Unified Model Architectures
이들 연구는 대게 unified formulation이나 related tasks 의 group을 위한 model architecture을 design 합니다. 예를 들면, Mask R-CNN 은 unified network을 제안합니다. 이는 object detection을 수행하고 instance segmentation을 동시에 수행하죠. Mask2Former는 universal architecture 을 제안하는데 panopticm instance, semantic segmantation을 다룰 수 있죠. Pix2SeqV2는 unified pixel-to-sequence interface를 설계합니다. 4개의 task를 위해서 인데, object detection, instance segmentation, keypoint detection, 그리고 image captioning 이 그 tasks죠. GLIP는 object detection을 phrase grounding으로 reformulates합니다. classical classification을 wor-region alignment로 대체함으로써 말이죠. 이 새로운 formulation은 detection과 grounding data에 대해 동시에 학습하는 것을 가능하게하죠. 다양한 object-level recognition tasks로 strong transferability를 보여주는 것은 당연하고요. 그러나, GLIP는 images&annotations 와 vide-level trcking tasks와 같은 다른 modalities에서 prompts를 지원하지 않죠. object tracking을 고려하면, Unicorn은 unified solution을 제안하는데 이는 SOT, VOS, MOT, 그리고 MOTS를 위한 모델이죠. 8개의 benchmarks에서 same model wieghts를 가지고 우월한 성능을 보여줬고요. 그러나 Unicorn이 diverse label vocabularies를 다루는 것은 여전히 어렵습니다. 이 논문에서, 저자들은 universal prompt-guided architecture를 제안합니다. 10 instance perception tasks를 위한 것이고, GLIP와 Unicorn의 단점을 동시에 정복해냈죠.
Approach
deatailed methods를 소개하기 전에, 저자들은 먼저 existing instance perception tasks를 3 classes로 나눕니다.
- object detection, instance segmentation, MOT, MOTS, and VIS 는 catagory names를 입력으로 받는데 specific classes의 모든 instance를 찾는 prompts입니다.
- REC, RES, and R-VOS 는 expression을 사용하는데 certain target을 localize하는 prompt입니다.
- SOT와 VOS는 first frame에서 주어진 annotation을 사용하는데, tracked target의 trajectories를 predicting하기 위한 prompt입니다.
본질적으로, 위의 모든 tasks는 some prompts에 의해 특정된 objects를 찾는 것을 목표로 합니다. 이 commonality는 저자들이 all instance perception tasks를 prompt-guided object discovery and retrieval problem으로 고려하도록 reformulate하는데 motivates하게 했죠. 그리고 unified model architecture and learning paradigm으로 이 문제를 해결하는 데 역시 motivate했고요. Figure 2에서 나타나 있다시피, UNINEXT는 세 개의 main components 로 구성되어 있죠. (1) prompt generation (2) image-prompt feature fusion (3) object discovery and retrieval
Prompt Generation
먼저, prompt generation module은 original diverse prompt inputs를 unified form으로 transform하기 위해 적용되죠. different modalities에 따라, 저자들은 다음 two paragraphs에서 각각 corresponding strategies를 도입합니다.
language-related prompts를 다루기 위해, language encoder E_nc_L이 adopted되죠. specific하기 위해, category guided tasks에 대해 저자들은 current dataset에 나타는 class names를 language expression으로 concatenate합니다. example로 COCO를 입력으로 받으면, expression은 "person, bicycle, ... , toothbrush"로 쓰여집니다. 그러면 cagegory-guided와 expression-guided tasks 모두에 대해, language expression은 E_nc_l을 지나게 되겠죠. sequence length L을 가진 prompt embedding F_p( R ^ Lxd ) 을 얻게 되고요.
anntation-guided tasks에 대해, fine-grained visual features를 추출하고 traget annotation을 fully expolit하기 위해, additional reference visual encoder E_nc_v^ref가 도입됩니다. 구체적으로,먼저 2^2 times target box area 를 가진template은 cropped 되는데 target location에 centerted 된 template죠. 그런다음 template는 fixed size of 256 x 256으로 resized 됩니다. 더 정확한 target information을 도입하기 위해, target prior라는 extra channel을 template image에 concatenated합니다. 4-channel input이 되는 것이죠. 더 자세하게 말하면, target prior의 value는 target region에 대해 1이고 그렇지 않으면 0입니다. 그런다음 template image는 target prior와 함께 reference visual encoder를 통과하고 hierarchical feature pyramid를 얻게 해주죠( C3, C4, C5, C6 ) 각각 spatial sizes는 32x32, 16x16, 8x8, 4x4 입니다. fine target information을 keep하고 other tasks로써 same format에서 prompt embedding을 get하기 위해, merging module이 적용됩니다. 즉, fetures의 all levels가 먼저 32x32로 upsampled되고 난 다음 더해지죠. 그리고 final prompt embedding F_p ( R ^ 1024xd )로 flattened 됩니다.
prompt generation process는 아래와 같이 공식화됩니다.

Image-Prompt Feature Fusion
prompt generation을 활용해 병렬적으로, 모든 current image는 다른 visual encoder를 통과하고 hierarchical visual features F_v를 얻게 됩니다. image context로 original prompt embedding을 강화하고 original visual features를 prompt-aware하게 만들기위해, early fusion module이 adopted됩니다. 더 구체적으로, 먼저 bi-directional corss-attention module ( Bi-XAtt)이 different inputs로부터 information을 retrieve하기 위해 사용됩니다. 그런 다음 retrieved representations가 original features에 더해지죠. 이 process는 아래와 같이 공식화 되죠.

GLIP와 다른점은, 6 vision-language fusion laters가 적용됬고 6개의 추가적인 BERT layers가 feature enhancement를 위해 사용된 것이 GLIP라면 저자들은 early fusion module은 훨씬 efficient하죠.
Object Discovery and Retrieval
discriminative visual 과 prompt representation을 활용해, 다음 crucial한 step은 input features를 variou perception tasks를 위한 instances로 transform하는 것이죠. UNINEXT는 encoder-decoder architecture를 adopt 하는데 Deformable DETR에서 제안된 architecture이고 이는 flexible query-to-instance fashion을 위한 것이죠.
Transformer encoder는 hierarchical prompt-aware visual features를 input으로 취합니다. efficient Multi-scale Deformable Self-Attention의 도움을 받아, different scales로부터 target information을 완전히 exchanged할 수 있고, subsequent instance decoding을 위한 stronger instance를 내보일수 있죠. two-stage Deformable DETR이 수행될 때, auxiliary prediction head는 encoder의 마지막에 붙여지는데 N 개의 initial reference points를 생성하고 이는 decoder의 inputs으로써 높은 점수를 가지고 있는 것들이죠.
Transformer decoder는 enhanced multi-scale features를 취합니다. N 개의 reference points와 N object queries가 inputs으로 역시 들어가죠. 이전 연구에서 보여지는바와 같이, object queries는 instance perception tasks에서 매우 중요한 역할을 하죠. 이 논문에서, 저자들은 two query generation strategies를 시도합니다: (1) static queries 이고 이는 images나 prompts에 따라 변하지 않죠. (2) dynamic queries이고 prompts에 따라 달라지죠. 첫 번째 strategy는 쉽게 구현됩니다. nn.Embedding(N,d)를 활용하면 되죠. 후자는 먼저 enhanced prompt feature F'_v를 sequence dimension을 따라 pooling함으로써 수행될 수 있죠. 이렇게 global representation을 얻은 후에, N times를 반복합니다. 위의 두 방법은 sec 4.3에서 비교합니다. 저자들은 static queries가 dynamic queris보다 대게 좋은 성능을 보인다는 것을 알아냅니다. 잠정적인 이유는 static queries가 richer information을 포함할 수 있고 dynamic queries보다 안정적으로 학습될 수 있기 때문일거라고 추측하죠. deformable attention의 도움으로, object queries는 prompt-awre visual features를 efficiently하게 retrieve할수 있고 strong instance embedding을 learn할 수 있습니다.
decoder의 마지막에서, prediction heads의 group은 final instance predictions를 얻기위해 사용됩니다. 구체적으로, instance head는 target의 boxes와 masks를 생성하죠. embedding head는 MOT, MOTS, 그리고 VIS에서 이전 trajectories를 가진 detected results를 associating 하기 위해 도입됩니다. 지금까지, N 개의 potential instance proposals를 mined했고 Figure 2에서 gray masks를 활용해 represented 되었죠. 그러나, 모든 proposals가 prompts가 실제로 참조하는 것은 아니죠. 그럼으로 저자들은 proposals로부터 matched objects를 더 retrieve할 필요가 있고 이는 Figure2의 오른쪽에 나타난 것처럼 prompt embedding를 따라 retrieve하죠. 구체적으로, prompt embeddings F'_p 가 early fusion 이후에 주어지면, category-guided tasks를 위해, 저자들은 each category name의 embedding을 weight matrix W 로 받습니다. expression-guided 와 annotation-guided tasks에 대해, weight matrix W 는 sequence dimension을 따라 global avergage pooling( GAP )를 사용해 prompt embedding F'를 aggregating 함으로써 얻죠. 식으로 정리하면 아래와 같습니다.

마지막으로, instnace-prompt matching scores S는 matrix multiplication으로 계산되는데 target features와 trasposed weight matrix을 행렬곱한 것이죠. 식은 아래와 같고요

이전 연구에 따르면, matching scores는 Focal Loss로 supervised 될 수 있죠. 이전 fixed-sized classifiers와 다른점은, proposed retrieval head는 objects를 prompt-instance matching mechanism으로 select한다는 것이고요. flexible design은 UNINEXT가 different tasks로부터 다양한 label vocabularies를 가진 enormous한 datasets에 대해 동시에 학습 가능하도록 합니다.
Training and Inference
Training
전체 training process는 연속된 3가지 step으로 구성되어 있죠. (1) general perception pretraining (2) image-level joint training (3) video-level joint training.
첫 번째 단계에서, 저자들은 UNINEXT을 large-scale object detection dataset Objects365에 대해 학습하는데 objects에 대해 unibersal knowledge를 학습하기 위함이죠. Objects365가 mask annotations를 가지고 있지 않기 때문에, 두가지 auxiliary losses를 도입하는데 이는 BoxInst에서 제안되었었고 mask branch를 training하기 위함이죠. loss function은 아래과 같이 구성됩니다.
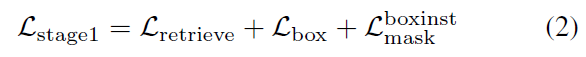
그런 다음, first stage의 pretrained weigths에 기반해, UNINEXT를 image datasets에서 finetune하는데요. 해당 데이터셋은 COCO와 mixed dataset of RefCOCO, RefCOCO+, 그리고 RefCOCOg입니다. manually하기 labeled 된 mask annotations을 가지고 Dice Loss 와 Focal Loss 같은 traditional loss functions가 mask learning을 위해 사용되죠. 이 step 다음, UNINEXT는 obejct detection, instance segmentation, REC , RES에서 우월한 성능을 가지게 됩니다.

마지막으로, 저자들은 UNINEXT를 video-level dataset에 대해 finetune하는데요 다양한 object tracking tasks와 bechmars를 위해서죠. 이 stage에서, model은 original videos에서 randomly 하게 선택된 2개의 frames에 대해 trained됩니다. 또한 image-level tasks에서 학습된 knowledge가 지워지는 것을 피하기위해, image-level dataset을 pseudo vidioes로 바꾸고 video dataset과 함께 학습합니다. 요약하면, 3번째 stage에서 training data는 pseudo videos를 포함하는 데 이 video는 COCO, RefCOCO/g/+, SOT&VOS datasets ( GOT-10k, LaSOT, TrackingNet, Youtube-VOS), MOT&VIS datasets( BDD100K, VIS19, OVIS , R-VOS dataset Ref-Youtube-VOS). 그러는 동안 SOT&VOS를 위한 reference visual encoder와 association을 위한 extra embedding head가 도입되고 optimized됩니다. Loss function은 아래와 같죠.
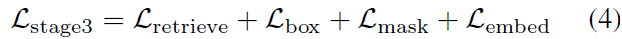
Inference
category-guided tasks를 위해, UNINEXT는 different categories의 instances를 예측합니다. 그리고 previous trajectories로 그들을 associates하죠. association proceeds는 online fashion을 따르고 learned instance embedding 에 기반합니다. expression-guided와 annotation-guided tasks는 final results로써 주어진 prompts를 활용해 highest matching score를 가진 object를 직접 pick합니다. 이전 연구와 다른점은 저자들의 방식은 간단하고 online 이며 post-processing free하다는 점이죠.
여기까지 할게요!
그럼 다음에 뵈요!