[꼼꼼하게 논문 읽기]EcoFormer: Energy-Saving Attentionwith Linear Complexity ( 2023 )
Abstract
transformer는 deep learning을 위한 trasformative frameworks 죠. sequential data를 models하고 다양하고 광범위한 분야에서 remarkable performance를 달성했죠. 그런데, high computational and energy cost의 가 항상 문제죠. efficiency를 향상시키기 위해, popular choice는 models를 compress하는 것이죠. 이는 binarization을 통해 가능한데 floatingpoint values를 binary ones로 제한하죠. bitwise 연산이 상당히 cheap하기 때문에 resource consumption을 절약하기도하고요. 그렇지만, 현존하는 binarization method는 input distribution에 대해 statistically하게 information loss를 최소화하는 것만을 목표로 하죠. 즉, attention mechanism의 core에서 pairwise similarity modeling을 무시한다는 것이 문제죠. 그래서 저자들은 new binarization paradigm을 제안하는데 kernelizaed hashing을 통해 high-dimensional softmax attention으로 custmized하죠. 이를 EcoFormer라부르고 original queries와 keys를 hamming space에서 low-dimensional binary codes로 map합니다. kernelized hash functions는 self-supervised way로 attention map으로 부터 추출된 ground-truth similarity relations를 match하도록 학습합니다. Hamming distance와 binary codes의 inner product 간의 equivalence와 matrix multiplication의 associative property에 기반해, 저자들은 binary codes의 dot-product로써 표현함으로써 attention을 linear complexity로 가정할 수 있죠. 게다가 EcoFormer에서 queries와 key의 compact binary representations는 저자들에게 대부분의 expensive한 multiply-accumulate operations를 edge devices에서 considerable한 on-chip energy footprint를 절약하는 simple accumulations를 활용한 attention으로 대체 가능하도록하죠. vision과 language tasks에 대한 광범위한 실험은 EcoFormer가 훨씬 적은 resources를 사용하면서도 standard attentions와 견줄만한 performance를 보인다는 것을 보여주죠. 구체적으로, PVTv2-B0와 ImageNet-1K에 기반한 on-chip energy footprint에서 EcoFomer는 73%의 절감을 달성했죠. performance는 0.33% 감소했고요.
Introduction
최근, Transformers가 빠르고 흥미로운 progress를 보여줘 왔죠. NLP와 CV에서요. 이는 exraordinary한 representational poewer때문이기도 하고요. CNNs와 비교하면, Transformer models는 광범위한 양의 data에 더 generally하게 scalable하고 less inductive bias를 가진 long-dependency global information에서 better하죠. 그러나, efficiency bottlenecks, 특히 high energy consumption의 경우, resource-constrained edge devices에 Transformer models의 deployment는 굉장히 hamper하죠. mobile phones나 unmanned aerial vehicles와 같은 곳에서요. 즉 real-world applications에 활용되기 어렵죠.
energy consumption을 줄이기 위해, quantization은 network weights의 더 낮은 bit-width represention에 대해 활발히 연구되어 왔죠. most aggressive bit-width을 활용해, binary quantization은 훨씬 더 많은 관심을 받아왔는데 single bit로 values를 representing함으로써 efficient bit-wise operations를 가능하게 하기 때문이죠. BinaryConnect로 weights를 binarize할 때, 많은 양의 energy-hungry multiply-accumulate operations를 simple envergy-efficient accumulations로 대체함으로써 dedicated hardware에 큰 이점을 야기하죠. Transformers를 활용해 inference를 시행할 때 필요한 상당한 on-chip area와 energy를 절약하죠. 이 때문에 limited resources를 가진 mobile platforms에 deployed 될 수 있는 것이고요. 그러나, 전통적인 binarization process는 original full-precisiondata distribution과 quantized Bernoulli distribution 간의 quantization errors를 최소화하는데 초점이 맞춰져 있죠. 즉, 각 token이 각각 binarized됩니다. binary representations가 tokens간에 original similarity relations를 잘 보존하지 못하게 되죠. 이것은 저자들이 binarization process를 softmax attention으로 customize하도록하는 동기가 되었습니다. 구체적으로는 tokens간의 pairwise similarity를 encodes하는 core mechanism을 말하고요 결국 저자들은 well-establised hashing methods를 적용하는데 high-dimensional queries와 keys를 compact binary codes에 map합니다. 이는 Hamming space에서 similarity relations를 보존할 수 있도록 하죠. simple solution은 LSH를 사용하는 것인데 binary quantization counterparts로써 대체되는 방법이기도 하죠.
그럼에도 불구하고, 다른 enery bottleneck이 Transformers에 존재합니다. 구체적으로 tokens의 sequence가 주어지면, soft max attention은 attention wieghts를 얻죠 이는 query token과 all key tokens와 inner product를 계산함으로써 얻고요. 이는 quadratic time complexity O ( N^2 )을 야기하는데 여기서 N은 tokens의 수죠. 이는 Figure 1 (a)에서 볼수 있습니다.

이 문제는 long sequence length N 에 대해 최악이죠. 특히 high resolution images를 가진 dense prediction tasks에서는 더욱 문제가 됩니다. softmax attention의 complexity를 줄이기 위해, 기존 몇몇 연구는 attention을 kernelized feature embeddings의 linear dot product로서 attention을 표현하길 제안합니다. matrix multiplication의 associative property를 활용해 attention operation은 linear complexity(N)으로 추정될수 있고 이는 Figure 1 (b)에서 볼 수 있죠.
hashing mechanism과 attention의 kernel-based formulation에 기반하여, 저자들은 simple하지만 effective energy-saving attention을 발명합니다. EcoFormer라고 불리고 Figure 1 (c)에서 볼 수 있죠. 자세히, 저자들은 queries와 keys를 compact binary codes에 map하는 RBF kernel를 가진 kernelized hashing을 사용하길 제안하죠. resulting codes는 similarity preserving에 대해 valid한데 codes' inner product와 Hamming distance가 one-to-one correspondence를 가지는 property 때문이죠. binary codes간의 linear dot-product의 associative property 덕분에, kernelized hasing attention은 linear comlexity를 가진체로 상당한 energy saving이 되죠. 게다가, pariwise similarity matrix은 hash function learning을 위한 supervision labels를 얻는데 직접 사용될 수 있고 새로운 self-supervised hasing paradigm을 만들어냈고요. tokens의 similar pairs에 대해 Hamming affinity를 maximizing함으로써 그리고 동시에 tokens의 dissimilar한 pairs를 mizimizing함으로써, pairwise similarity relations는 preserved 될 수 있죠. low-dimensional binary queries와 keys를 활용해, 저자들은 energy-hungry floating-point multiplications의 대부분을 simple additions로 대체할 수 있는데 on-chip energy footprint를 greatly하게 절감할 수 있습니다.
요약해서, 3가지 main contributions를 말하면 1) softmax attention에서 pairwise similarity를 더잘 보존하는 새로운 binarization paradigm을 제안합니다. 자세히, EcoFormer를 제안하는데, energy-sabing attention은 linear complexity를 가지고 있고 이는 kernelized hashing에 의해 powered 되죠. 이 attention은 queries와 key를 compact binary codes로 map합니다. 2) kernelized hash functions는 Hamming affinity ground-truth에 기반하고 attention scores로부터 추출된 정보를 활용하며 self-supervied way으로 학습되죠. 3) CIFAR-100, ImageNet-1K, and Long Range Arena에서의 광범위한 실험은 EcoFormer가 accuracy를 보존하면서 on-chip energy를 상당히 감소시킬수 있다는것을 보여주죠.
Related Work
Efficient attention mechanisms
vanilla attention을 위한 quadratic computational cost 완화하기위해, 많은 연구는 efficient attentions를 개발하는데 많은 노력을 기울였죠. research의 한 줄기는 tokens의 part에 대해서만 attention을 수행하죠. 예를 들면, Reformer, SMYRF. Fast Transformers나 LHA는 attention을 제한하는데 similar token paris에 대해 수행되며 이는 hasing을 통해 억제되죠. 그렇게 complexity를 NlogN으로 줄입니다. Linformer는 key와 value의 길이를 줄이는 low-rank factorization을 가진 attention을 추정합니다. research의 다른 line은 vanilla attention의 speed를 증대시키는 것이었고 이는 kernel-based method입니다. 예로는, Peformer는 orhogonal random feautres를 가진 softmax operation으로 동작합니다. Nystromformer 와 SOFT는 matrix decomposition을 통해 모든 self-attention matrix를 approximate하죠. 인상적인 achievements가 달성되었음에도불구하고 highly energy-efficient한 attention을 develop하는 방법은 여전히 미지의 영역이었죠. adderNet variants는 energy-hungry multiplication-based similarity measurement를 energy-efficient addition-based L1 distance로 대체했고 additions 역시 powerful feature representations를 제공한다고 주장했죠. 그럼에도 불구하고 이 heuristic approach는 drastic performance drop을 야기했죠. 반면에, 저자들은 binarization의 perspective로부터 attention scores를 사용해 kernel-based hash functions를 학습하기를 제안하죠. 이는 original features를 compact similarity-preserving binary codes로 map하고 Hamming distance를 활용하죠. 이는 energy-efficient한데 linear complexity를 가집니다. low-dimensional binary queris와 keys를 활용해, EcoFormer는 대부분의 multiplications를 simple accumulations로 대체합니다.
Hashing
Hashing은 efficient nearest neighbor search method인데요. high-dimensional data를 similarity preserving low-dimensional binary codes로 embedding하죠. 이는 similar data는 same hash key에 assigned 되어야한다는 직관에 기반하고요. Hashing methods는 data-independent와 data-dependent schemes로 roughly하게 categorized됩니다. former는 random hash functions을 building하는데 초점이 맞춰져있습니다. locaaly sensitive hasing ( LSH )는 대표적인 representative one 인데 sub-linear time similarity search를 보장하고 kernel을 가진 hashing과 같은 non-linear extensions이 뒤따르죠. 후에는 더 나눠져 unsupervised, semi-supervised 그리고 supervised hashing으로 세분화 됩니다. Transformers와 관련해서, self-attentions이 tokens를 따라 pairwise similarity를 encodes하기 때문에 hasing은 query가 주어지면 유사한 keys를 retrieve하는 natural한 choice이죠. Reformer는 pionnering work인데, similar token을 group할 것을 제안하죠. single hash buket에서 group하고 bucket은 sparse self-attention을 form합니다. 저자들의 EcoFormer는 본질적으로 Reformer와 세가지 측면에서 다릅니다. 1) Reformer는 local attention lookups 에 의존하는데 lookups는 complexity를 감소시키죠 반면 EcoFormer는 numerical perspective에서 설계되었고요. low-dimensional binary codes는 multiplications를 절감하는데 사용되죠. 2) Reformer는 linear mapping을 활용한 LSH에 기반해 설계되었습니다. sequence length로 linearly하기 scale하는 attention의 kernel-based formulation을 다룰 수 없죠. 3) 저자들의 hash funtions는 attention에서 pairwise affinity labels에 의해 self-supervised 됩니다. 이는 network parameters를 활용해 conjunction에서 optimized되고 unsupervised random projections보다 훨씬 더 정확하죠.
Binary quantization
Binarization, extreme quantization scheme은 binary codes로 vectors를 represent하는 것을 추구하죠. 결과적으로, computationally heavy matrix multiplications는 light-weight bitwise operations가 되는데, memory saving과 acceleration을 promising하도록 하죠. 일반적으로, binary neural networks가 accuracy에 대해 reliable하도록 만들기 위해, current research는 두 가지 main chanllenges에 tackling하는 것을 target으로하죠. first challenge는 quantization error를 minimize하는 것입니다. 기본적으로 scaling factors를 learning하는 것, quantization ragne나 intervals를 parameterizaing하는 것과 multiple binary bases를 essembling하는 것에 기반하죠. 연구의 다른 catagory는 discretization process 때문에 발생하는 non-differentiable optimization을 해결하는 것에 초점을 맞추는데 이는 regularization, knowledge distillation, relaxed optimzation, full-precision branches를 appending하는 것을 활용하죠. CNNs의 한부분에서 떨어져 나와, Transformers를 binarizing하는데 새로운 시도가 있었죠. BinaryBERT는 Transformer quantization을 lweight binarization까지 limit으로 push합니다. BiBERT는 weights, embeddings 그리고 activations를 1-bit로 모두 quantizes하고 FLOPs와 model size를 상당히 절감했죠. 물론 명백한 performance drop이 있었고요. 반면 저자들은 binarization paradigm을 customize할 것을 제안하는데 hashing perspective로 부터 softmax attention으로 customize하라는 것이죠. 이는 compact binary codes에서 pairwise similarity information을 perserving하죠. compact binary codes는 linear-complexity, energy-efficient self-attention deliver 하는데 사용됩니다.
Preliminaries
Attention Mechanism
X( R^NxD )가 standard multi-head self-attention( MSA ) layer로 들어가는 input sequence라고 하자. N은 input sequence의 length 이고 D는 hidden dimension의 수를 표기합니다. standard MSA layers는 query, key and value vector의 sequence를 계산하는데 세 개의 learnable projection matrices W_q, W_k, W_v를 가지고 있죠. 이는 아래처럼 공식화 될 수 있습니다.

D_p는 각 head를 위한 dimensions의 수를 나타냅니다. 각 query vector에 대해, attention output은 all value vectores에 대해 wieghted-sum인데 식은 아래와 같죠.

여기서 tau 는 softmax의 flatness를 controlling하기 위한 temperature이고 exp( <> )는 exponential function입니다. N 개의 token을 가진, attention의 computation은 space와 time에 대해서 quadratic complexity ( N^2 )를 가지고 있죠. long sequences를 다룰 때 hughe computational cost가 야기되는 이유기도 하고요.
Kernel-based Linear Attention
kernel-based linear attention에 기반한 idea는 similarity measure을 Eq (2)로 표현하는 것이죠. kernel embeddings의 linear dot-product로써 나타내는데, polynomial kernel, exponetial of RBF kernel과 같은 것을 아래처럼 표현하죠.
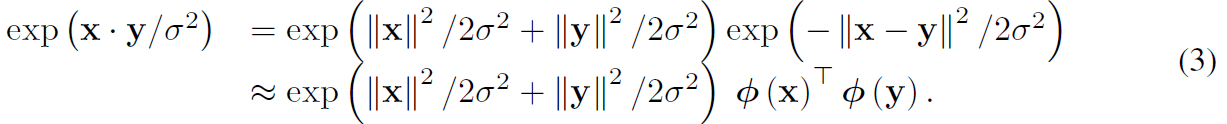
이 choice는 finite random mapping을 사용하는데 infinte dimensional RBF kernel을 근사화하죠. 그런다음 Rahimi 연구 theorem에 따라 pi로 transformed된 vector x와 y의 pair간에 inner product가 Guassian RBF kernel을 approximate합니다. Eq 2에서 exp(<>)로 unbiased estimation을 제공하죠.
queries와 keys가 unit vectors로 가정하면, attention computation은 아래와 같이 approximated 될 수 있죠.
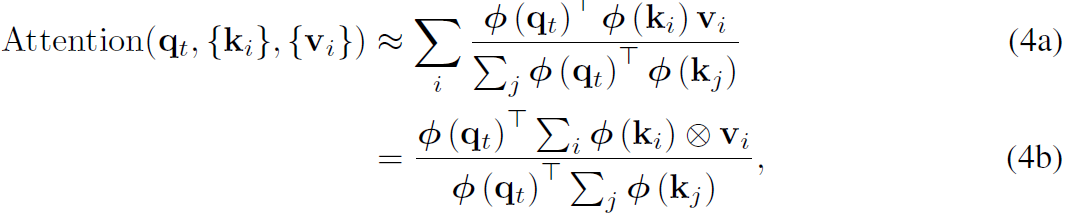
여기서 x 처럼 생긴 연산은 outer product를 나타냅니다. 최근 연구는 kernel-based linear attentions가 machine translation에서 original softmax attention과 protein sequence modeling보다 faborably하게 동작한다는것을 보여줬죠. 그러나, complexity가 linear하게 감소했음에도 불구하고, intensive floating-point multiplications가 여전히 많은 양의 energy를 소비하죠. 이는 mobile/edge platforms에 대해 batteries를 빠르게 방전시키죠.
Binary Qunantization
binary quantization은 전형적으로 full-precision을 u ( R ^ n )을 추정하는데, binary hat u ( { -1 , 1 } ^n )과 scaling factor alpha ( R+ )를 사용하죠. 즉 식으로 나타내면 아래와 같습니다.
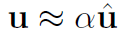
accurate estimation을 find하기위해, existing methods는 quantization error를 아래와 같이 minimize합니다.

(5)를 해결함으로 저자들은 아래와 같은 hat u와 alpha를 얻을 수 있죠.

sign function은 non-differentiable, straight-through estimator( STE )이기 때문에, hard tanh의 gradient 나 piecewise polynomial function과 같은 gradient를 approximate 하기위해 applied되죠.
Proposed Method
self-attention의 energy consumption을 줄이기 위해, binary quantization을 queries와 keys에 대해 수행합니다. 이 경우, 대부분의 energy-expensive multiplications를 energy-efficient bit-wise operations로 대체할수 있죠. 그러나, 현존하는 binary quantization methods는 origianl full-precision values와 binary ones 간의 quantization error를 minimizing하는데 초점이 맞춰져 있죠. 이는 attention에서 different tokens간의 pairwise semantic similarity를 preserve하데 fail하고 performance degradation을 야기하죠.
attention은 pairwise tokens에 대해 kernel smoother를 적용하는 것으로써 볼수 있고 kernel scores는 token pairs의 similarity를 표기하죠. 이에 영감을 받아, 저자들은 새로운 binarization method를 제안하는데 , Gaussian RBF를 가진 kerenlized hashing을 적용하는 것이죠. 이는 original high-dimensional queries/keys를 low-dimensional similarity-preserving binary codes로 Hamming space에서 map합니다. 제안된 framework은 EcoFormer라 불리고 Figure 1 ( c ) 에 나타나 있죠. attention에서 semantic similarity를 maintain하기 위해, 저자들은 self-supervised manner로 hash functions을 학습시킵니다. binary codes간의 linear dot-product의 associative property를 사용함으로써 , code innerproducts와 Hamming distances간의 동질성을 활용해서 self attention을 linear time에서 low energy cost로 approximate할 수 있습니다. 저자들은 먼저, kernelized hashing attention을 소개하고 self-supervised 방식으로 hash functions를 학습하는 방법에대해 보여줍니다.
Kernelized Hashing Attention
hash functions를 적용하기 전에, queris와 keys가 identical 하다고 하면 kernelized hash functions를 적용할 수 있습니다. transformation을 적용하지 않아도 되죠. q_i와 k_i를 b-bit binary codes H(q_i) 와 H(k_j)로 map하죠. 이 경우, Hamming distance는 아래와 같이 정의됩니다

H_r() 은 binary codes의 r-th bit입니다 1{} 는 indicator funciton인데 A가 satisfied면 1을 아니면 0을 retrun합니다. D( H( q_i ), H( k_j ))를 활용해 H(q_i)와 H(k_j) 간의 codes inner product는 아래와 같이 공식화 될 수 있죠.

Eq7 은 Hamming distance와 codes inner product간의 동질성을 보여줍니다. one-to-one correspondence에 해당하기 때문이죠. hased quries와 key로 대체함으로써, 저자들은 self-attentions을 아래와 같이 근사할수 있습니다.
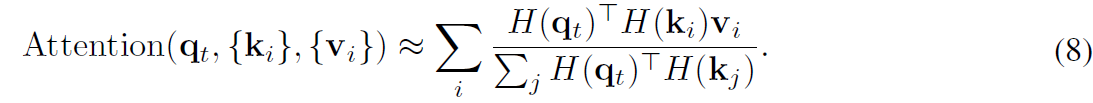
denominator에서 zero를 피하기 위해, 저자들은 bias term 2^c를 각 inner product에 도입합니다. similarity measure에는 영향을 미치지 않죠. 여기서 c 를 log_2( b+1 )로 set하면 [u] 는 u와 같거나 그것보다 큰 integer를 return하죠. matrix multiplication의 associative property를 사용하여, 저자들은 self-attention을 아래와 같이 근사합니다.
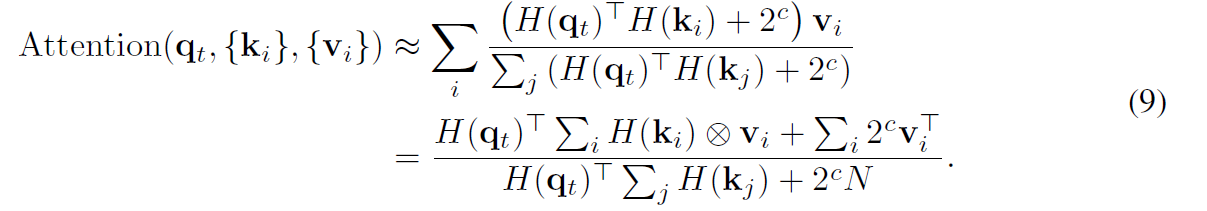
binary codes와 full-precision value 간의 multiplications는 simple additions 와 subtractions로 대체될수 있습니다.이는 computational overhead를 굉장히 감소시키죠. 게다가, multiplications는 bit-shift operations로 구현될 수 있습니다. 결과적으로 multiplications는 numerator와 denominator간의 element-wise division에만 남아있게 되죠.
Self-supervised Hash Function Learning
queris가 주어지면, 저자들은 hash functions의 group을 학습시킵니다. transformation funtion을 적용하는 대신, kernel function을 가진 hash fucntions를 계산합니다. 주어진 queris에서 m 개의 queries를 randomly하게 뽑는데 이들은 kernel-based supervised hasing( KSH )를 support하는 sample들이죠. 그리고 hash function h 는 아래와 같습니다.
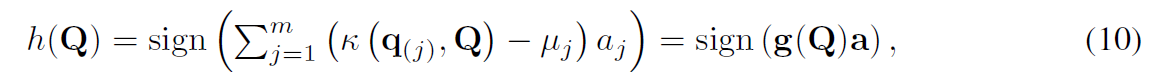
여기서 a는 h의 weight 입니다. u_j는 zero-mean으로 kernel function을 normalize하는 것입니다. 그리고 g는 g(Q)에 의해 w정의된 mapping입니다. 그러면 저자들은 kernelized hash function을 아래와 같이 적을 수 있죠.

A와 h_r(Q)는 r-th bit를 위한 hash function입니다. binary codes의 learning을 guide하기 위해, 저자들은 similar token pairs가 minimal Hamming distance를 가지길 바라고 dissimilar token pairs는 maximal distance를 갖길 원하죠. 그럼에도 불구하고 Hamming distance로 직접 optimizing하는 것은 non-convex와 non-smooth때문에 어렵죠. code inner products와 Hamming 간의 동질성을 활용하여 저자들은 reconstruction error를 minimize하는 Hamming affinity에 기반하여 optimization을 시행하죠 식은 아래와 같습니다.
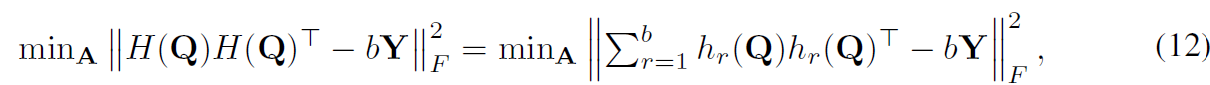
여기서 || ||_F는 Frobenius norm이고 Y는 target Hamming affinity matrix입니다. queries와 key 간의 similarity relations를 preserve하기위해. 저자들은 attention scores를 Y를 construct하기위한 self-supervised information으로 사용합니다. S와 u를 similar와 dissimilar pairs의 token으로 정의하면 Top-l largest 와 smallest attenstion scores를 가진 token pairs를 selecting함으로써 S와 U를 얻을 수 있고 labels Y를 construct할 수 있습니다.

그러나 problem 12는 NP-hard입니다. 이 문제를 해결하기 위해, 저자들은 discrete cyclic coordinate descent를 적용합니다. binary codes를 learn 시키는 방법으로 말이죠. 구체적으로 a_r을 해결하면 이전 a1..,a_r-1은 optimized되죠. hat Y_r-1 은 residual matrix이고 여기서 hat Y_0 = bY 입니다. 그러면 a_r을 obtain하는 objective를 minimize할수 있죠.
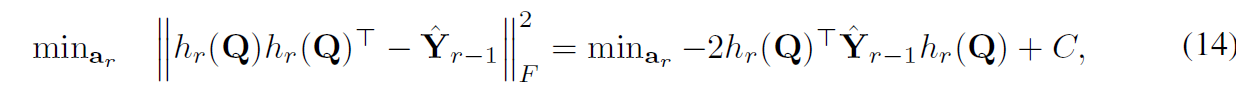
여기서 C는 constant이고 hat Y_r-1은 symmetric matrix입니다. 따라서 probelm 14는 standard binary quadratic programming problem입니다. 이는 현존하는 많은 방법으로 효율적으로 풀수 있죠. a_r을 학습시키기위해 gradient-based methods를 사용하여 해결합니다. non-differentiable sign function을 위해, STE를 사용하는데, gradient를 approximate하죠. hard tanh를 사용하고요. each epoch에 대해 hash functions를 학습시키는 것은 아직 unnecessary하고 computationally expensive합니다.
여기까지 할게요.